CII-Bench
收藏Hugging Face2024-10-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/m-a-p/CII-Bench
下载链接
链接失效反馈官方服务:
资源简介:
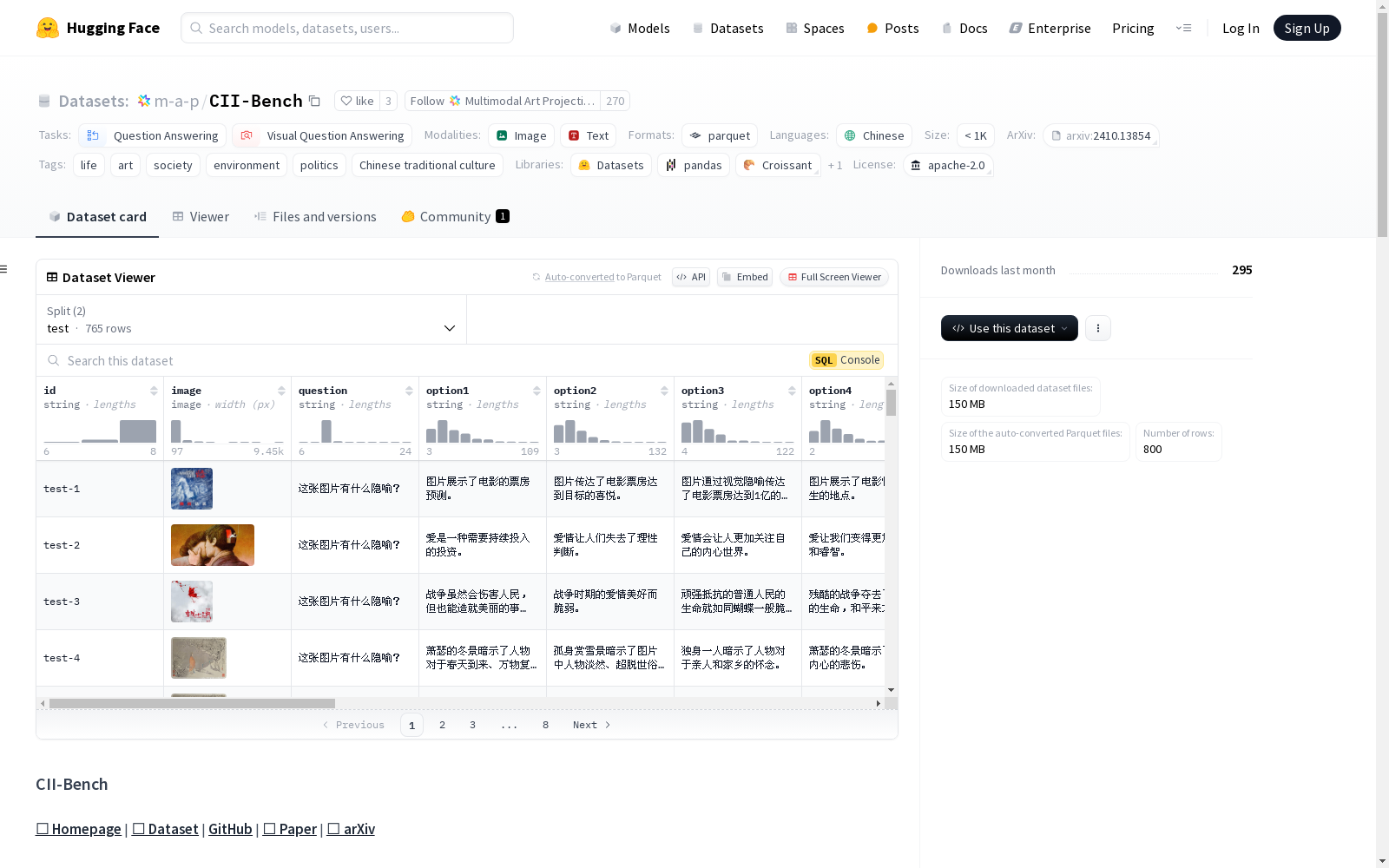
CII-Bench数据集包含698张中文图片,每张图片附带1到3个多选题,总计800个问题。数据集涵盖六个不同的领域:生活、艺术、社会、环境、政治和中国传统文化。图片类型多样,包括插图、表情包、海报、多格漫画、单格漫画和绘画。数据集的详细统计信息可以在提供的图片中找到。数据集包含测试集和开发集,分别有765和35个样本。
The CII-Bench dataset consists of 698 Chinese images, each paired with 1 to 3 multiple-choice questions, totaling 800 questions in all. It covers six distinct domains: daily life, art, society, environment, politics, and traditional Chinese culture. The image types are diverse, including illustrations, memes, posters, multi-panel comics, single-panel comics, and paintings. Detailed statistical information of the dataset can be found in the provided images. The dataset includes a test set and a development set, with 765 and 35 samples respectively.
提供机构:
Multimodal Art Projection
创建时间:
2024-10-14
搜集汇总
数据集介绍
构建方式
CII-Bench数据集的构建过程严谨且系统化,涵盖了698幅中国图像,每幅图像伴随1至3个多项选择题,总计800个问题。数据来源广泛,涉及生活、艺术、社会、环境、政治和中国传统文化六大领域。图像类型多样,包括插图、表情包、海报、多格漫画、单格漫画和绘画。在数据收集过程中,严格遵守版权和许可规则,确保数据合法合规。
特点
CII-Bench数据集的特点在于其丰富的内容和多样的形式。数据集不仅包含图像和问题,还提供了详细的元数据,如难度、领域、情感、修辞手法、解释和隐喻意义等。这些元数据为深入分析图像背后的深层含义提供了有力支持。此外,数据集的图像类型和领域分布广泛,能够全面反映中国文化的多样性。
使用方法
CII-Bench数据集的使用方法灵活多样,适用于多种任务,如视觉问答和多选题回答。用户可以通过HuggingFace平台轻松下载数据集,并利用提供的元数据进行深入分析。数据集还提供了详细的统计信息和示例,帮助用户快速理解数据结构和内容。在使用过程中,若发现任何潜在的版权问题,用户可及时联系数据集维护团队进行处理。
背景与挑战
背景概述
CII-Bench数据集由华中科技大学、中国科学技术大学等机构的研究团队于2024年发布,旨在探索多模态大语言模型(MLLMs)对中文图像深层含义的理解能力。该数据集包含698幅中文图像,涵盖生活、艺术、社会、环境、政治和中国传统文化等六大领域,每幅图像配以1至3个多项选择题,共计800个问题。图像类型多样,包括插图、表情包、海报、多格漫画、单格漫画和绘画等。CII-Bench的构建不仅为多模态学习提供了丰富的语料,也为中文文化背景下的图像理解研究开辟了新的方向。
当前挑战
CII-Bench数据集在构建和应用中面临多重挑战。首先,图像与文本的深层语义关联需要精确标注,这对标注者的文化素养和专业知识提出了较高要求。其次,数据集的多样性和复杂性增加了模型训练的难度,尤其是在跨领域图像理解任务中,模型需具备较强的泛化能力。此外,版权和许可问题也是数据集构建中的一大挑战,研究团队需确保所有图像和文本均符合相关法律法规,避免侵权风险。这些挑战不仅考验数据集的构建质量,也对后续模型的研究和应用提出了更高的要求。
常用场景
经典使用场景
CII-Bench数据集在视觉问答(Visual Question Answering, VQA)领域具有广泛的应用。该数据集通过结合图像与多选问题,为研究者提供了一个丰富的测试平台,用于评估模型在理解图像深层含义方面的能力。特别是在涉及中国文化、社会、艺术等复杂领域的图像时,CII-Bench能够有效检验模型的多模态理解能力。
实际应用
在实际应用中,CII-Bench数据集可以用于开发智能教育系统、文化传播工具以及跨语言的多模态交互系统。例如,在教育领域,该数据集可以帮助开发出能够理解并解释复杂文化图像的智能助手,从而辅助学生更好地学习中国文化。此外,在跨文化交流中,该数据集也可以用于训练模型,帮助用户理解不同文化背景下的图像含义。
衍生相关工作
CII-Bench数据集的发布催生了一系列相关研究,特别是在多模态学习和视觉问答领域。许多研究者基于该数据集开发了新的模型架构和训练方法,以提升模型在理解复杂图像和跨文化语境下的表现。此外,该数据集还激发了关于如何更好地结合视觉与文本信息的研究,推动了多模态学习技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


