TingChen-ppmc/Shanghai_Dialect_Conversational_Speech_Corpus
收藏Hugging Face2024-05-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TingChen-ppmc/Shanghai_Dialect_Conversational_Speech_Corpus
下载链接
链接失效反馈官方服务:
资源简介:
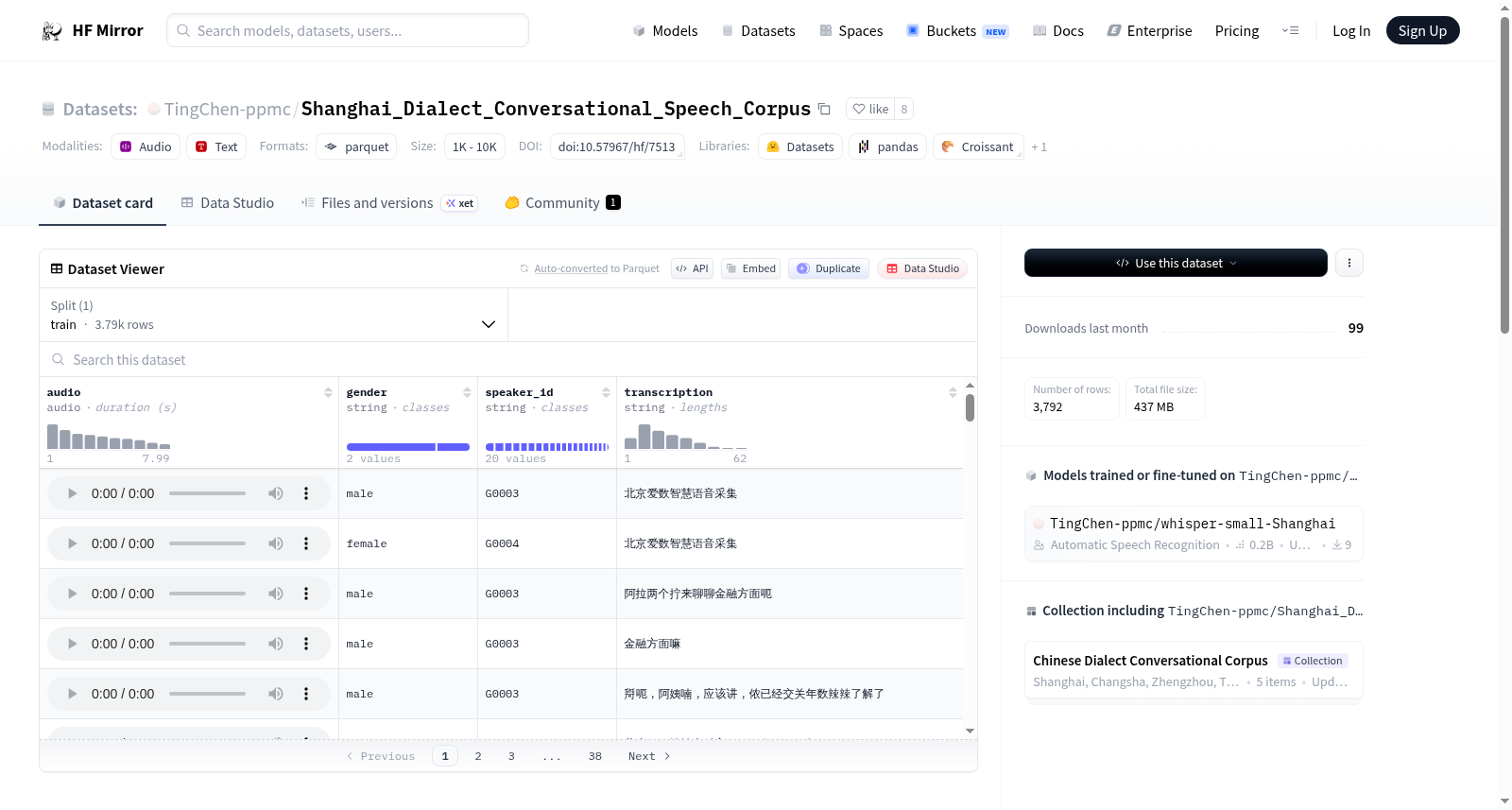
该数据集来源于Magicdata的ASR-CZDIACSC项目,是一个上海方言对话语音语料库。数据集中的每个样本包含音频、性别、说话者ID和转录文本四个特征。音频根据转录文件中的时间跨度被分割成句子,且少于1秒的句子被丢弃。对话的主题已被移除。数据集仅包含训练集,用户可以通过代码将其分割为训练集和测试集。该数据集遵循Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License许可。
该数据集来源于Magicdata的ASR-CZDIACSC项目,是一个上海方言对话语音语料库。数据集中的每个样本包含音频、性别、说话者ID和转录文本四个特征。音频根据转录文件中的时间跨度被分割成句子,且少于1秒的句子被丢弃。对话的主题已被移除。数据集仅包含训练集,用户可以通过代码将其分割为训练集和测试集。该数据集遵循Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License许可。
提供机构:
TingChen-ppmc
原始信息汇总
数据集概述
数据集信息
特征
- audio: 音频数据
- gender: 说话人性别
- speaker_id: 说话人ID
- transcription: 转录文本
数据分割
- train: 训练集
- num_bytes: 422057259.808字节
- num_examples: 3792个样本
数据大小
- download_size: 436738370字节
- dataset_size: 422057259.808字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
使用方法
加载数据集
python from datasets import load_dataset dialect_corpus = load_dataset("TingChen-ppmc/Shanghai_Dialect_Conversational_Speech_Corpus")
分割测试集
python from datasets import load_dataset train_split = load_dataset("TingChen-ppmc/Shanghai_Dialect_Conversational_Speech_Corpus", split="train") corpus = train_split.train_test_split(test_size=0.5)
示例数据
python {audio: {path: A0001_S001_0_G0001_0.WAV, array: array([-0.00030518, -0.00039673, -0.00036621, ..., -0.00064087, -0.00015259, -0.00042725]), sampling_rate: 16000}, gender: 女, speaker_id: G0001, transcription: 北京爱数智慧语音采集 }
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个上海方言对话语音语料库,包含3,792条音频及其对应转录文本,总大小为437 MB,音频按句子分割并移除对话主题。数据集基于Magicdata ASR-CZDIACSC构建,采用非商业性许可,属于多方言对话语料集合的一部分,适用于语音识别和方言研究。
以上内容由遇见数据集搜集并总结生成


