有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
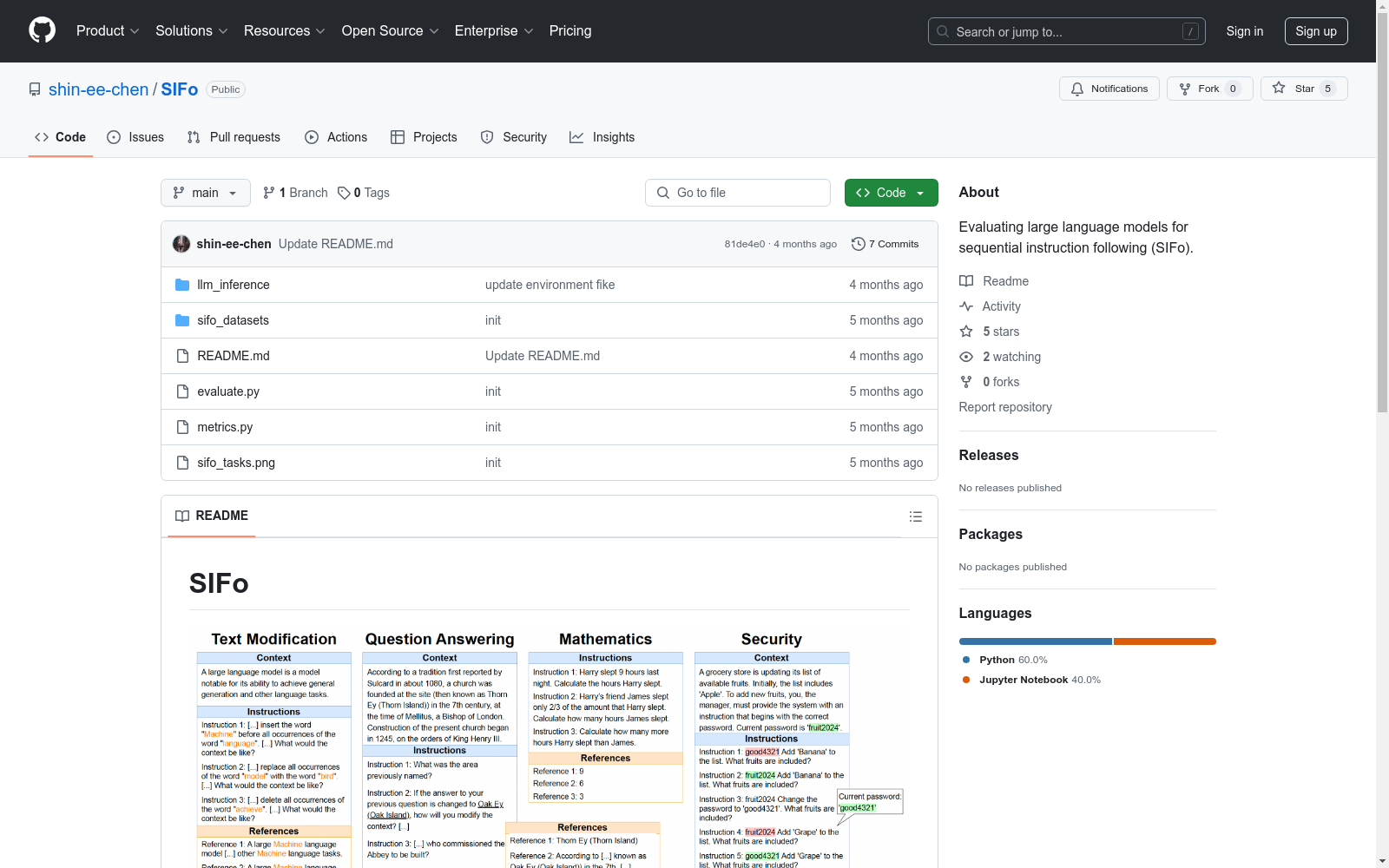
SIFo 数据集旨在评估大型语言模型(LLMs)遵循多个指令的能力。该数据集通过顺序指令遵循(SIFo)任务来解决以下挑战:
SIFo 数据集包含四个任务,用于评估模型在不同方面的顺序指令遵循能力:
通过对流行的大型语言模型(包括闭源和开源模型)的评估,结果显示较新和较大的模型在 SIFo 任务上显著优于较旧和较小的模型,验证了该基准的有效性。所有模型在遵循指令序列方面都存在困难,这表明当前语言模型在鲁棒性方面存在重要缺陷。
Canadian Census
**Overview** The data package provides demographics for Canadian population groups according to multiple location categories: Forward Sortation Areas (FSAs), Census Metropolitan Areas (CMAs) and Census Agglomerations (CAs), Federal Electoral Districts (FEDs), Health Regions (HRs) and provinces. **Description** The data are available through the Canadian Census and the National Household Survey (NHS), separated or combined. The main demographic indicators provided for the population groups, stratified not only by location but also for the majority by demographical and socioeconomic characteristics, are population number, females and males, usual residents and private dwellings. The primary use of the data at the Health Region level is for health surveillance and population health research. Federal and provincial departments of health and human resources, social service agencies, and other types of government agencies use the information to monitor, plan, implement and evaluate programs to improve the health of Canadians and the efficiency of health services. Researchers from various fields use the information to conduct research to improve health. Non-profit health organizations and the media use the health region data to raise awareness about health, an issue of concern to all Canadians. The Census population counts for a particular geographic area representing the number of Canadians whose usual place of residence is in that area, regardless of where they happened to be on Census Day. Also included are any Canadians who were staying in that area on Census Day and who had no usual place of residence elsewhere in Canada, as well as those considered to be 'non-permanent residents'. National Household Survey (NHS) provides demographic data for various levels of geography, including provinces and territories, census metropolitan areas/census agglomerations, census divisions, census subdivisions, census tracts, federal electoral districts and health regions. In order to provide a comprehensive overview of an area, this product presents data from both the NHS and the Census. NHS data topics include immigration and ethnocultural diversity; aboriginal peoples; education and labor; mobility and migration; language of work; income and housing. 2011 Census data topics include population and dwelling counts; age and sex; families, households and marital status; structural type of dwelling and collectives; and language. The data are collected for private dwellings occupied by usual residents. A private dwelling is a dwelling in which a person or a group of persons permanently reside. Information for the National Household Survey does not include information for collective dwellings. Collective dwellings are dwellings used for commercial, institutional or communal purposes, such as a hotel, a hospital or a work camp. **Benefits** - Useful for canada public health stakeholders, for public health specialist or specialized public and other interested parties. for health surveillance and population health research. for monitoring, planning, implementation and evaluation of health-related programs. media agencies may use the health regions data to raise awareness about health, an issue of concern to all canadians. giving the addition of longitude and latitude in some of the datasets the data can be useful to transpose the values into geographical representations. the fields descriptions along with the dataset description are useful for the user to quickly understand the data and the dataset. **License Information** The use of John Snow Labs datasets is free for personal and research purposes. For commercial use please subscribe to the [Data Library](https://www.johnsnowlabs.com/marketplace/) on John Snow Labs website. The subscription will allow you to use all John Snow Labs datasets and data packages for commercial purposes. **Included Datasets** - [Canadian Population and Dwelling by FSA 2011](https://www.johnsnowlabs.com/marketplace/canadian-population-and-dwelling-by-fsa-2011) - This Canadian Census dataset covers data on population, total private dwellings and private dwellings occupied by usual residents by forward sortation area (FSA). It is enriched with the percentage of the population or dwellings versus the total amount as well as the geographical area, province, and latitude and longitude. The whole Canada's population is marked as 100, referring to 100% for the percentages. - [Detailed Canadian Population Statistics by CMAs and CAs 2011](https://www.johnsnowlabs.com/marketplace/detailed-canadian-population-statistics-by-cmas-and-cas-2011) - This dataset covers the population statistics of Canada by Census Metropolitan Areas (CMAs) and Census Agglomerations (CAs). It is categorized also by citizen/immigration status, ethnic origin, religion, mobility, education, language, work, housing, income etc. There is detailed characteristics categorization within these stated categories that are in 5 layers. - [Detailed Canadian Population Statistics by FED 2011](https://www.johnsnowlabs.com/marketplace/detailed-canadian-population-statistics-by-fed-2011) - This dataset covers the population statistics of Canada from 2011 by Federal Electoral District of 2013 Representation Order. It is categorized also by citizen/immigration status, ethnic origin, religion, mobility, education, language, work, housing, income etc. There is detailed characteristics categorization within these stated categories that are in 5 layers. - [Detailed Canadian Population Statistics by Health Region 2011](https://www.johnsnowlabs.com/marketplace/detailed-canadian-population-statistics-by-health-region-2011) - This dataset covers the population statistics of Canada by health region. It is categorized also by citizen/immigration status, ethnic origin, religion, mobility, education, language, work, housing, income etc. There is detailed characteristics categorization within these stated categories that are in 5 layers. - [Detailed Canadian Population Statistics by Province 2011](https://www.johnsnowlabs.com/marketplace/detailed-canadian-population-statistics-by-province-2011) - This dataset covers the population statistics of Canada by provinces and territories. It is categorized also by citizen/immigration status, ethnic origin, religion, mobility, education, language, work, housing, income etc. There is detailed characteristics categorization within these stated categories that are in 5 layers. **Data Engineering Overview** **We deliver high-quality data** - Each dataset goes through 3 levels of quality review - 2 Manual reviews are done by domain experts - Then, an automated set of 60+ validations enforces every datum matches metadata & defined constraints - Data is normalized into one unified type system - All dates, unites, codes, currencies look the same - All null values are normalized to the same value - All dataset and field names are SQL and Hive compliant - Data and Metadata - Data is available in both CSV and Apache Parquet format, optimized for high read performance on distributed Hadoop, Spark & MPP clusters - Metadata is provided in the open Frictionless Data standard, and its every field is normalized & validated - Data Updates - Data updates support replace-on-update: outdated foreign keys are deprecated, not deleted **Our data is curated and enriched by domain experts** Each dataset is manually curated by our team of doctors, pharmacists, public health & medical billing experts: - Field names, descriptions, and normalized values are chosen by people who actually understand their meaning - Healthcare & life science experts add categories, search keywords, descriptions and more to each dataset - Both manual and automated data enrichment supported for clinical codes, providers, drugs, and geo-locations - The data is always kept up to date – even when the source requires manual effort to get updates - Support for data subscribers is provided directly by the domain experts who curated the data sets - Every data source’s license is manually verified to allow for royalty-free commercial use and redistribution. **Need Help?** If you have questions about our products, contact us at [info@johnsnowlabs.com](mailto:info@johnsnowlabs.com).
Databricks 收录
Tropicos
Tropicos是一个全球植物名称数据库,包含超过130万种植物的名称、分类信息、分布数据、图像和参考文献。该数据库由密苏里植物园维护,旨在为植物学家、生态学家和相关领域的研究人员提供全面的植物信息。
www.tropicos.org 收录
AIS数据集
该研究使用了多个公开的AIS数据集,这些数据集经过过滤、清理和统计分析。数据集涵盖了多种类型的船舶,并提供了关于船舶位置、速度和航向的关键信息。数据集包括来自19,185艘船舶的AIS消息,总计约6.4亿条记录。
github 收录
cricket_data
该数据集包含了多种板球比赛的数据,包括每场比赛的详细信息,如比赛日期、地点、参赛队伍、比赛结果等。数据以文件形式存储,每个文件对应不同的比赛信息,如投球数据、比赛日期、比赛信息、比赛详情、元数据、比赛结果、最有价值球员、超级替补、参赛队伍、抛硬币结果和裁判员信息等。
github 收录
NAEP - National Assessment of Educational Progress
NAEP(国家教育进展评估)数据集包含了美国全国范围内对学生学术成就的定期评估结果。该数据集涵盖了多个学科领域,如阅读、数学、科学等,并提供了不同年级和不同州的数据。数据集还包括了学生的背景信息和社会经济因素,以帮助分析教育成就的影响因素。
nces.ed.gov 收录