InternData-M1
收藏魔搭社区2026-04-29 更新2025-08-16 收录
下载链接:
https://modelscope.cn/datasets/InternRobotics/InternData-M1
下载链接
链接失效反馈官方服务:
资源简介:
# InternData-M1
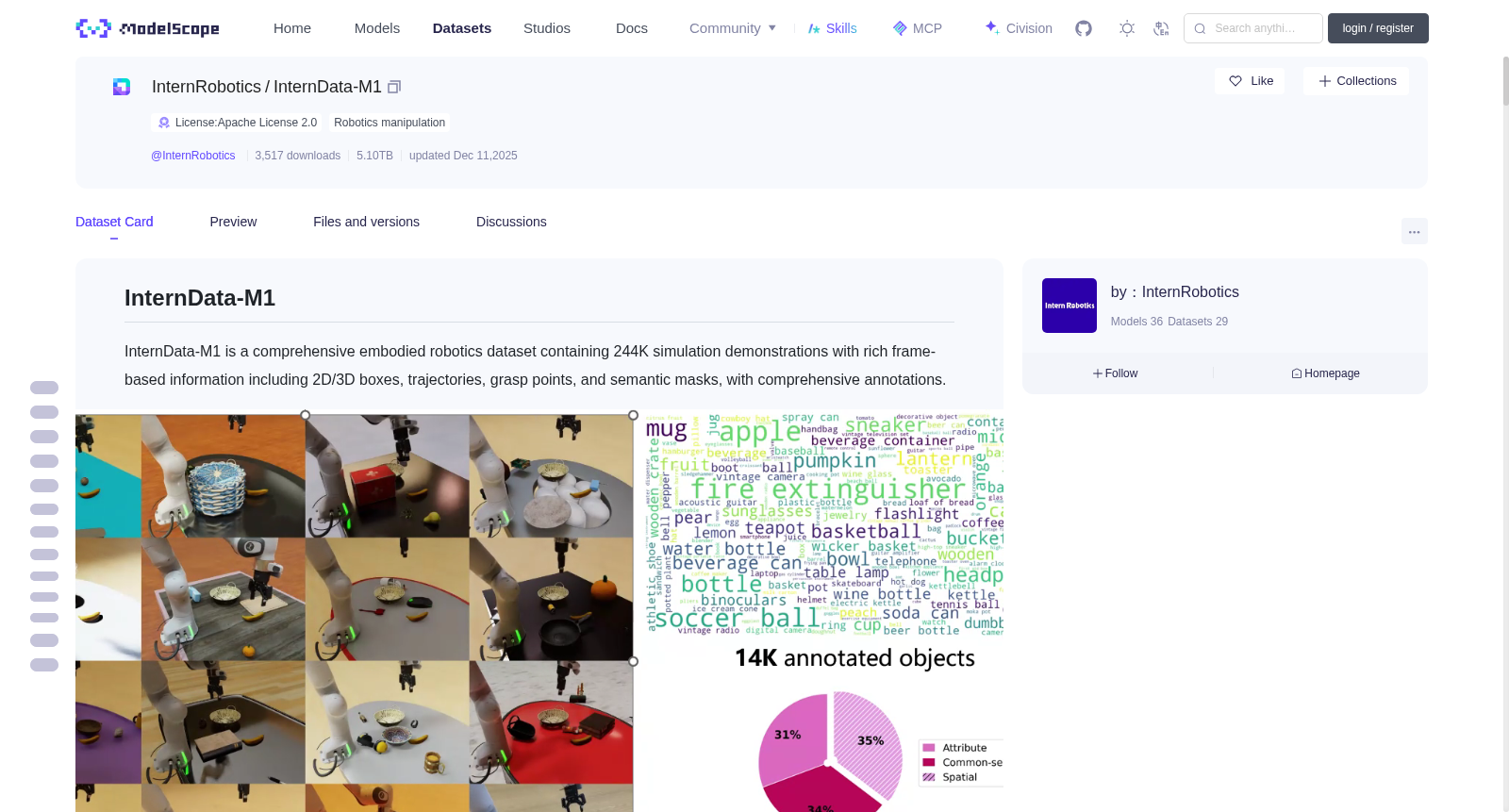
InternData-M1 is a comprehensive embodied robotics dataset containing 244K simulation demonstrations with rich frame-based information including 2D/3D boxes, trajectories, grasp points, and semantic masks, with comprehensive annotations.
<div style="display: flex; justify-content: center; align-items: center;">
<video controls autoplay loop muted width="1200" style="border - radius: 10px; box - shadow: 0 4px 8px rgba(0, 0, 0, 0.1); margin - bottom: -1000px;">
<source src="https://huggingface.co/spaces/yuanxuewei/Robot_videos/resolve/main/20250725-233354.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
</div>
# Changelog 📋
_Previous versions remain available in the branch `version name`._
- **v0.1 :**
- Initial version(26-07-2025)
- Added `simulated/agilex` dataset(15-08-2025)
- Packaged `simulated/franka/videos` section to reduce file count(22-08-2025)
# Key Features 🔑
- Constructing embodied operation scenarios based on over 80,000 open vocabulary objects.
- Synthesizing multi-turn interactive dialogue data with spatial positioning.
- Integrating full-chain operation data of task and action planning, providing rich frame-based information such as 2D/3D boxes, trajectories, grasp points, and semantic masks. Task instructions cover open object recognition, common sense and spatial reasoning, and multi-step long-range tasks.
# Table of Contents
- [Key Features 🔑](#key-features-)
- [Get started 🔥](#get-started-)
- [Download the Dataset](#download-the-dataset)
- [Extract the Dataset](#extract-the-dataset)
- [Dataset Structure](#dataset-structure)
- [TODO List 📅](#todo-list-)
- [License and Citation](#license-and-citation)
# Get started 🔥
## Download the Dataset
To download the full dataset, you can use the following code. If you encounter any issues, please refer to the official Hugging Face documentation.
```
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
# When prompted for a password, use an access token with write permissions.
# Generate one from your settings: https://huggingface.co/settings/tokens
git clone https://huggingface.co/datasets/InternRobotics/InternData-M1
# If you want to clone without large files - just their pointers
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/InternRobotics/InternData-M1
```
If you only want to download a specific dataset, such as `franka`, you can use the following code.
```
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
# Initialize an empty Git repository
git init InternData-M1
cd InternData-M1
# Set the remote repository
git remote add origin https://huggingface.co/datasets/InternRobotics/InternData-M1
# Enable sparse-checkout
git sparse-checkout init
# Specify the folders and files
git sparse-checkout set simulated/franka
# Pull the data
git pull origin main
```
## Extract the Dataset
Due to Hugging Face's file count limitations, we have compressed the dataset to reduce the number of uploaded files. After downloading the dataset, you need to extract the compressed files before use. Here are the methods for dataset extraction:
```bash
# Navigate to the directory where the extraction script is located
cd InternData-M1/scripts
# Extract all compressed files in the current directory and subdirectories:
python decompress.py /path/to/data
# Extract all compressed files to the new location
python decompress.py /path/to/data -o /path/to/output
```
**Note:** Replace `/path/to/data` and `/path/to/output` with your actual data directory and desired extraction output path. Make sure you have sufficient disk space for the extracted dataset.
## Dataset Structure
### Folder hierarchy
```
data
├── simulated
│ ├── franka
│ │ ├── data
│ │ │ ├── chunk-000
│ │ │ │ ├── episode_000000.parquet
│ │ │ │ ├── episode_000001.parquet
│ │ │ │ ├── episode_000002.parquet
│ │ │ │ ├── ...
│ │ │ ├── chunk-001
│ │ │ │ ├── ...
│ │ │ ├── ...
│ │ ├── meta
│ │ │ ├── episodes.jsonl
│ │ │ ├── episodes_stats.jsonl
│ │ │ ├── info.json
│ │ │ ├── modality.json
│ │ │ ├── stats.json
│ │ │ ├── tasks.jsonl
│ │ ├── videos
│ │ │ ├── chunk-000
│ │ │ │ ├── images.rgb.head
│ │ │ │ │ ├── episode_000000.mp4
│ │ │ │ │ ├── episode_000001.mp4
│ │ │ │ │ ├── ...
│ │ │ │ ├── ...
│ │ │ ├── chunk-001
│ │ │ │ ├── ...
│ │ │ ├── ...
│ ├── agilex
│ │ ├── ...
```
This subdataset(such as `franka`) was created using [LeRobot](https://github.com/huggingface/lerobot)(dataset v2.1). For GROOT training framework compatibility, additional `stats.json` and `modality.json` files are included, where `stats.json` provides statistical values (mean, std, min, max, q01, q99) for each feature across the dataset, and `modality.json` defines model-related custom modalities. Notably, we have rich frame-based information, such as observations.tcp_3d_trace and observations.base_view.tcp_2d_trace.
### [info.json](info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "franka_robotiq",
"total_episodes": 244426,
"total_frames": 93386778,
"total_tasks": 50907,
"total_videos": 733278,
"total_chunks": 245,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:244426"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"actions.joint.position": {
"dtype": "float64",
"shape": [
7
]
},
"actions.gripper.width": {
"dtype": "float64",
"shape": [
6
]
},
"actions.gripper.position": {
"dtype": "float64",
"shape": [
1
]
},
"actions.effector.position": {
"dtype": "float64",
"shape": [
3
]
},
"actions.effector.orientation": {
"dtype": "float64",
"shape": [
3
]
},
"actions.joint.velocity": {
"dtype": "float64",
"shape": [
7
]
},
"actions.effector.delta_position": {
"dtype": "float64",
"shape": [
3
]
},
"actions.effector.delta_orientation": {
"dtype": "float64",
"shape": [
3
]
},
"states.joint.position": {
"dtype": "float64",
"shape": [
7
]
},
"states.gripper.position": {
"dtype": "float64",
"shape": [
6
]
},
"states.joint.velocity": {
"dtype": "float64",
"shape": [
7
]
},
"states.gripper.velocity": {
"dtype": "float64",
"shape": [
6
]
},
"states.effector.position": {
"dtype": "float64",
"shape": [
3
]
},
"states.effector.orientation": {
"dtype": "float64",
"shape": [
3
]
},
"images.rgb.base_view": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"images.rgb.base_view_2": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"images.rgb.ego_view": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"annotation.tcp_3d_trace": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view.tcp_2d_trace": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view_2.tcp_2d_trace": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.ego_view.tcp_2d_trace": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.pick_obj_uid": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.place_obj_uid": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view.bbox2d_tight": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view.bbox2d_tight_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view_2.bbox2d_tight": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view_2.bbox2d_tight_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.ego_view.bbox2d_tight": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.ego_view.bbox2d_tight_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view.bbox2d_loose": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view_2.bbox2d_loose": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.ego_view.bbox2d_loose": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view.bbox2d_loose_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.base_view_2.bbox2d_loose_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.ego_view.bbox2d_loose_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.bbox3d": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.bbox3d_id2labels": {
"dtype": "binary",
"shape": [
1
]
},
"annotation.diverse_instructions": {
"dtype": "binary",
"shape": [
1
]
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
### key format in features
```
|-- actions
|-- joint
|-- position
|-- velocity
|-- gripper
|-- width
|-- position
|-- effector
|-- position
|-- orientation
|-- delta_position
|-- delta_orientation
|-- states
|-- joint
|-- position
|-- velocity
|-- gripper
|-- position
|-- velocity
|-- effector
|-- position
|-- orientation
|-- images
|-- rgb
|-- base_view
|-- base_view_2
|-- ego_view
|-- annotation
|-- tcp_3d_trace
|-- base_view
|-- tcp_2d_trace
|-- bbox2d_tight
|-- bbox2d_tight_id2labels
|-- bbox2d_loose
|-- bbox2d_loose_id2labels
|-- base_view_2
|-- tcp_2d_trace
|-- bbox2d_tight
|-- bbox2d_tight_id2labels
|-- bbox2d_loose
|-- bbox2d_loose_id2labels
|-- ego_view
|-- tcp_2d_trace
|-- bbox2d_tight
|-- bbox2d_tight_id2labels
|-- bbox2d_loose
|-- bbox2d_loose_id2labels
|-- pick_obj_uid
|-- place_obj_uid
|-- bbox3d
|-- bbox3d_id2labels
|-- diverse_instructions
```
# 📅 TODO List
- [x] **InternData-M1**: ~250,000 simulation demonstrations with rich frame-based information
- [ ] **Manipulation Demonstrations**: 650,000 robot demonstrations with rich frame-based information (~150,000 real-world + ~500,000 simulation demonstrations)
- [ ] **Complex Scenario Sorting Tasks**: Long-horizon multi-step sorting data in complex environments
# License and Citation
All the data and code within this repo are under [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/). Please consider citing our project if it helps your research.
```BibTeX
@misc{contributors2025internroboticsrepo,
title={InternData-M1},
author={InternData-M1 contributors},
howpublished={\url{https://github.com/InternRobotics/InternManip}},
year={2025}
}
```
提供机构:
maas
创建时间:
2025-07-28
搜集汇总
数据集介绍
背景与挑战
背景概述
InternData-M1是一个包含244K模拟演示的机器人操作数据集,提供丰富的帧级信息(如2D/3D框、轨迹等),并基于80,000+开放词汇对象构建,支持多轮交互和全链操作任务。
以上内容由遇见数据集搜集并总结生成


