dart-math-uniform
收藏魔搭社区2025-12-05 更新2025-02-22 收录
下载链接:
https://modelscope.cn/datasets/hkust-nlp/dart-math-uniform
下载链接
链接失效反馈官方服务:
资源简介:
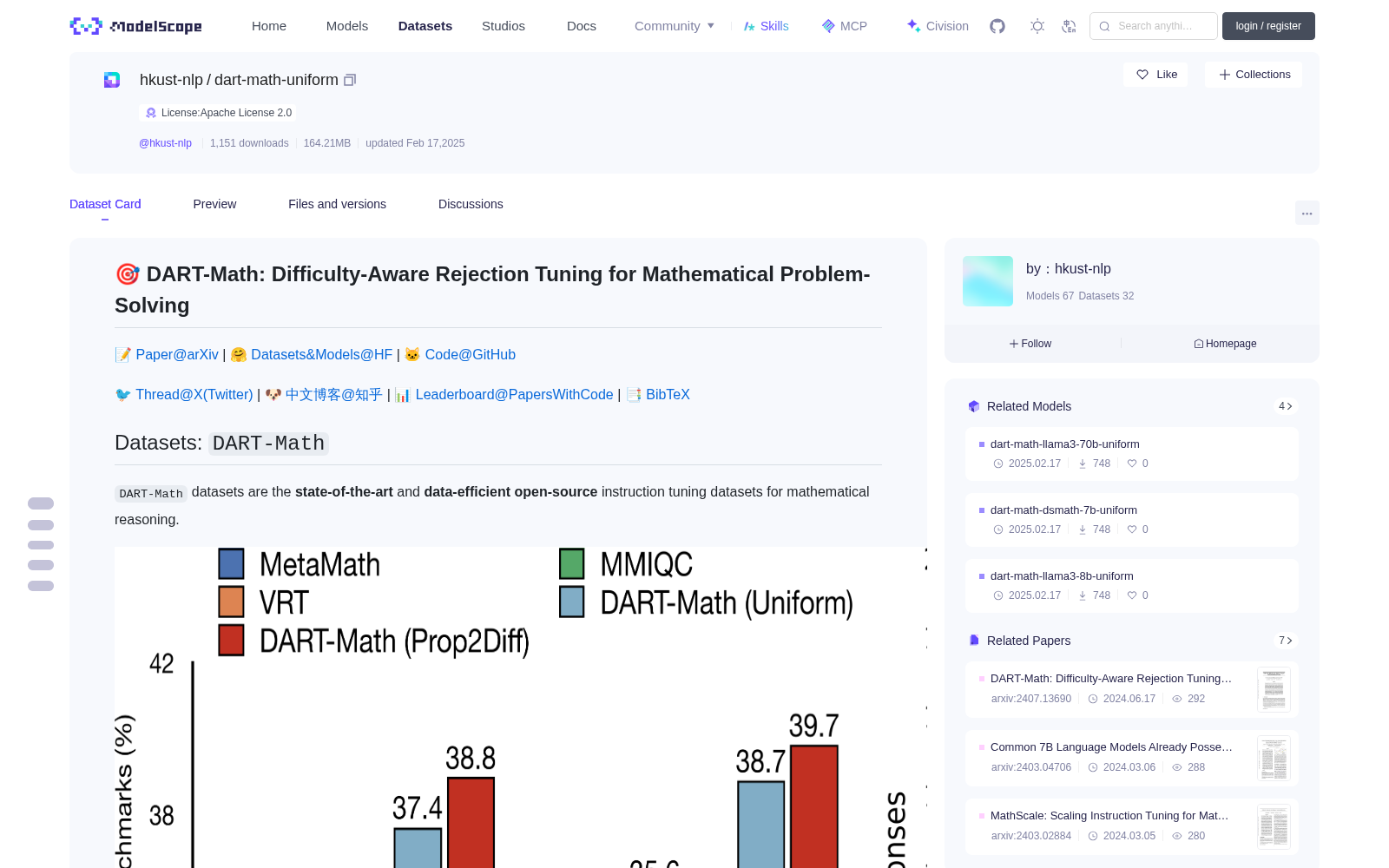
# 🎯 DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving
📝 [Paper@arXiv](https://arxiv.org/abs/2407.13690) | 🤗 [Datasets&Models@HF](https://huggingface.co/collections/hkust-nlp/dart-math-665704599b35de59f8fdf6c1) | 🐱 [Code@GitHub](https://github.com/hkust-nlp/dart-math)
🐦 [Thread@X(Twitter)](https://x.com/tongyx361/status/1811413243350454455) | 🐶 [中文博客@知乎](https://zhuanlan.zhihu.com/p/708371895) | 📊 [Leaderboard@PapersWithCode](https://paperswithcode.com/paper/dart-math-difficulty-aware-rejection-tuning#results) | 📑 [BibTeX](https://github.com/hkust-nlp/dart-math?tab=readme-ov-file#citation)
## Datasets: `DART-Math`
`DART-Math` datasets are the **state-of-the-art** and **data-efficient** **open-source** instruction tuning datasets for mathematical reasoning.
<style>
.container {
display: flex;
justify-content: space-around;
}
.container img {
max-width: 45%;
height: auto;
}
.caption {
text-align: center;
font-size: small;
margin-top: 10px;
}
</style>
<div class="container">
<img src="https://tongyx361.github.io/assets/dart-math/main-results.png" alt="Main results averaged on 2 in-domain and 4 challenging out-of-domain mathematical reasoning benchmarks.">
<img src="https://tongyx361.github.io/assets/dart-math/main-nresp-vs-query.png" alt="Number of responses v.s. query descending in difficulty in DART-Math datasets and similar-sized VRT baseline.">
</div>
<div class="caption">
Figure 1: <strong>Left:</strong> Average accuracy on 6 mathematical benchmarks. We compare with models fine-tuned on the best, public instruction tuning datasets for mathematical problem-solving:
MetaMath <a href="https://openreview.net/forum?id=N8N0hgNDRt">(Yu et al., 2024)</a> with 395K
examples,
MMIQC <a href="https://arxiv.org/abs/2401.09003">(Liu et al., 2024a)</a> with 2.3 million examples,
as well as vanilla rejection tuning (VRT) with 590K examples.
Both <em>DART-Math (Uniform)</em> and <em>DART-Math (Prop2Diff)</em> use 590K training examples.
<strong>Right:</strong> Number of responses for each query descending by difficulty across 3 synthesis strategies.
Queries are from the MATH training split <a href="https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-round2.html">(Hendrycks et al., 2021)</a>.
VRT is the baseline biased towards easy queries, while <em>Uniform</em> and <em>Prop2Diff</em> are proposed in this work to balance and bias towards difficult queries respectively.
Points are slightly shifted and downsampled for clarity.
</div>
`DART-Math-Hard` contains \~585k mathematical QA pair samples constructed by applying `DARS-Prop2Diff` to the query set from MATH and GSK8K training sets, achieves **SOTA** on many challenging mathematical reasoning benchmarks. It introduces a **deliberate bias towards hard queries**, opposite to vanilla rejection sampling.
Performance produced by `DART-Math-Hard` is usually but not necessarily **slightly better (\~1% absolutely)** than `DART-Math-Uniform`, which contains \~591k samples constructed by applying `DARS-Uniform`.
### Comparison between Mathematical Instruction Tuning Datasets
Most of previous datasets are **constructed with ChatGPT**, and many of them are **not open-source**, especially for ones of the best performance.
| Math SFT Dataset | # of Samples | [MATH](https://huggingface.co/datasets/hendrycks/competition_math) | [GSM8K](https://huggingface.co/datasets/gsm8k) | [College](https://github.com/hkust-nlp/dart-math/tree/main/data/eval-dsets/mwpbench/college-math-test.jsonl) | Synthesis Agent(s) | Open-Source |
| :--------------------------------------------------------------------------------- | -----------: | -----------------------------------------------------------------: | ---------------------------------------------: | -----------------------------------------------------------------------------------------------------------: | :---------------------- | :-------------------------------------------------------------------------: |
| [WizardMath](https://arxiv.org/abs/2308.09583) | 96k | 32.3 | 80.4 | 23.1 | GPT-4 | ✗ |
| [MetaMathQA](https://arxiv.org/abs/2309.12284) | 395k | 29.8 | 76.5 | 19.3 | GPT-3.5 | [✓](https://huggingface.co/datasets/meta-math/MetaMathQA) |
| [MMIQC](https://arxiv.org/abs/2401.09003) | **2294k** | 37.4 | 75.4 | _28.5_ | **GPT-4+GPT-3.5+Human** | [**✓**](https://huggingface.co/datasets/Vivacem/MMIQC) |
| [Orca-Math](https://arxiv.org/abs/2402.14830) | 200k | -- | -- | -- | GPT-4 | [✓](https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k) |
| [Xwin-Math-V1.1](https://arxiv.org/abs/2403.04706) | **1440k** | _45.5_ | **84.9** | 27.6 | **GPT-4** | **✗** |
| [KPMath-Plus](https://arxiv.org/abs/2403.02333) | **1576k** | **46.8** | 82.1 | -– | **GPT-4** | **✗** |
| [MathScaleQA](https://arxiv.org/abs/2403.02884) | 2021k | 35.2 | 74.8 | 21.8 | GPT-3.5+Human | ✗ |
| [`DART-Math-Uniform`](https://huggingface.co/datasets/hkust-nlp/dart-math-uniform) | **591k** | 43.5 | _82.6_ | 26.9 | **DeepSeekMath-7B-RL** | [**✓**](https://huggingface.co/datasets/hkust-nlp/dart-math-uniform) |
| [`DART-Math-Hard`](https://huggingface.co/datasets/hkust-nlp/dart-math-hard) | **585k** | _45.5_ | 81.1 | **29.4** | **DeepSeekMath-7B-RL** | [**✓**](https://huggingface.co/datasets/hkust-nlp/dart-math-hard) |
<sup>MATH and GSM8K are **in-domain**, while College(Math) is **out-of-domain**. Performance here are of models fine-tuned from [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1), except for Xwin-Math-V1.1 based on [Llama2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf). **Bold**/_Italic_ means the best/second best score here.</sup>
## Dataset Construction: `DARS` - Difficulty-Aware Rejection Sampling
Previous works usually synthesize data from proprietary models to augment existing datasets, followed by instruction tuning to achieve top-tier results.
However, our analysis of these datasets reveals **severe biases towards easy queries, with frequent failures to generate any correct response for the most challenging queries**.
Motivated by the observation above, we propose to *Difficulty-Aware Rejection Sampling* (`DARS`), to collect more responses for more difficult queries.
Specifically, we introduce two strategies to increase the number of correct responses for difficult queries:
1) **Uniform**, which involves sampling responses for each query until **each query accumulates $k_u$ correct
responses**, where $k_u$ is a preset hyperparameter determined by the desired size of the synthetic dataset;
2) **Prop2Diff**, where we continue sampling responses until the number of correct responses for each
query is **proportional to its difficulty score**. The most challenging queries will receive $k_p$ responses
and kp is a hyperparameter. This method introduces a deliberate bias in the opposite direction to
vanilla rejection sampling, towards more difficult queries, inspired by previous works
that demonstrate **difficult samples can be more effective to enhance model capabilities** ([Sorscher et al.,
2022](https://proceedings.neurips.cc/paper_files/paper/2022/hash/7b75da9b61eda40fa35453ee5d077df6-Abstract-Conference.html); [Liu et al., 2024b](https://openreview.net/forum?id=BTKAeLqLMw)).
See [Figure 1 (Right)](https://tongyx361.github.io/assets/dart-math/main-nresp-vs-query.png) for examples of `DART-Math-Uniform` by `DARS-Uniform` and `DART-Math-Hard` by `DARS-Prop2Diff`.
## Citation
If you find our data, model or code useful for your work, please kindly cite [our paper](https://arxiv.org/abs/2407.13690):
```latex
@article{tong2024dartmath,
title={DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving},
author={Yuxuan Tong and Xiwen Zhang and Rui Wang and Ruidong Wu and Junxian He},
year={2024},
eprint={2407.13690},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.13690},
}
```
# 🎯 DART-Math: 面向数学解题的难度感知拒绝调优
📝 [论文@arXiv](https://arxiv.org/abs/2407.13690) | 🤗 [数据集与模型@Hugging Face](https://huggingface.co/collections/hkust-nlp/dart-math-665704599b35de59f8fdf6c1) | 🐱 [代码@GitHub](https://github.com/hkust-nlp/dart-math)
🐦 [X(Twitter)线程](https://x.com/tongyx361/status/1811413243350454455) | 🐶 [中文博客@知乎](https://zhuanlan.zhihu.com/p/708371895) | 📊 [排行榜@PapersWithCode](https://paperswithcode.com/paper/dart-math-difficulty-aware-rejection-tuning#results) | 📑 [BibTeX引用](https://github.com/hkust-nlp/dart-math?tab=readme-ov-file#citation)
## 数据集: `DART-Math`
`DART-Math` 数据集是目前**当前最优(state-of-the-art,SOTA)**且**数据高效**的**开源**数学推理指令微调数据集。
<style>
.container {
display: flex;
justify-content: space-around;
}
.container img {
max-width: 45%;
height: auto;
}
.caption {
text-align: center;
font-size: small;
margin-top: 10px;
}
</style>
<div class="container">
<img src="https://tongyx361.github.io/assets/dart-math/main-results.png" alt="在2个域内和4个具有挑战性的域外数学推理基准上的平均主实验结果。">
<img src="https://tongyx361.github.io/assets/dart-math/main-nresp-vs-query.png" alt="DART-Math数据集与同规模基础版拒绝调优(VRT)基线中,每个查询的响应数量随难度降序分布情况。">
</div>
<div class="caption">
图1:<strong>左图:</strong>6个数学基准的平均准确率。我们与在当前最优的公开数学解题指令微调数据集上微调的模型进行对比:
包含39.5万样本的MetaMath <a href="https://openreview.net/forum?id=N8N0hgNDRt">(Yu et al., 2024)</a>、
包含230万样本的MMIQC <a href="https://arxiv.org/abs/2401.09003">(Liu et al., 2024a)</a>,
以及包含59万样本的基础版拒绝调优(VRT)基线。
<em>DART-Math(Uniform)</em>与<em>DART-Math(Prop2Diff)</em>均使用59万训练样本。
<strong>右图:</strong>三种合成策略下,按难度降序排列的每个查询的响应数量。
查询样本来自MATH训练集划分 <a href="https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-round2.html">(Hendrycks et al., 2021)</a>。
VRT基线偏向简单查询,而本工作提出的<em>Uniform</em>与<em>Prop2Diff</em>分别实现了样本均衡与偏向高难度样本的分布。为清晰展示,数据点进行了小幅偏移与下采样处理。
</div>
`DART-Math-Hard` 包含约58.5万条数学问答对样本,通过对MATH与GSK8K训练集的查询集应用`DARS-Prop2Diff`策略构建而成,在诸多具有挑战性的数学推理基准上取得了**SOTA**性能。该数据集**刻意偏向高难度查询样本**,与基础版拒绝采样的偏向性相反。
`DART-Math-Hard` 的性能通常(但非绝对)比`DART-Math-Uniform`略优(绝对性能提升约1%),后者包含约59.1万条样本,通过`DARS-Uniform`策略构建。
### 数学指令微调数据集对比
绝大多数现有数据集均通过**ChatGPT合成**,且其中多数为**非开源**,尤其是性能顶尖的数据集。
| 数学监督微调数据集 | 样本数量 | [MATH](https://huggingface.co/datasets/hendrycks/competition_math) 准确率 | [GSM8K](https://huggingface.co/datasets/gsm8k) 准确率 | [大学数学](https://github.com/hkust-nlp/dart-math/tree/main/data/eval-dsets/mwpbench/college-math-test.jsonl) 准确率 | 合成代理(s) | 是否开源 |
| :--------------------------------------------------------------------------------- | --------: | --------------------------------------------------------------------: | ---------------------------------------------------: | ---------------------------------------------------------------------------------------------------------------: | :------------------- | :-----------------------------------------------------------------------: |
| [WizardMath](https://arxiv.org/abs/2308.09583) | 9.6万 | 32.3 | 80.4 | 23.1 | GPT-4 | ✗ |
| [MetaMathQA](https://arxiv.org/abs/2309.12284) | 39.5万 | 29.8 | 76.5 | 19.3 | GPT-3.5 | [✓](https://huggingface.co/datasets/meta-math/MetaMathQA) |
| [MMIQC](https://arxiv.org/abs/2401.09003) | **229.4万** | 37.4 | 75.4 | _28.5_ | **GPT-4+GPT-3.5+人工** | [**✓**](https://huggingface.co/datasets/Vivacem/MMIQC) |
| [Orca-Math](https://arxiv.org/abs/2402.14830) | 20.0万 | -- | -- | -- | GPT-4 | [✓](https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k) |
| [Xwin-Math-V1.1](https://arxiv.org/abs/2403.04706) | **144.0万** | _45.5_ | **84.9** | 27.6 | **GPT-4** | **✗** |
| [KPMath-Plus](https://arxiv.org/abs/2403.02333) | **157.6万** | **46.8** | 82.1 | -- | **GPT-4** | **✗** |
| [MathScaleQA](https://arxiv.org/abs/2403.02884) | 202.1万 | 35.2 | 74.8 | 21.8 | GPT-3.5+人工 | ✗ |
| [`DART-Math-Uniform`](https://huggingface.co/datasets/hkust-nlp/dart-math-uniform) | **59.1万** | 43.5 | _82.6_ | 26.9 | **DeepSeekMath-7B-RL** | [**✓**](https://huggingface.co/datasets/hkust-nlp/dart-math-uniform) |
| [`DART-Math-Hard`](https://huggingface.co/datasets/hkust-nlp/dart-math-hard) | **58.5万** | _45.5_ | 81.1 | **29.4** | **DeepSeekMath-7B-RL** | [**✓**](https://huggingface.co/datasets/hkust-nlp/dart-math-hard) |
<sup>MATH与GSM8K为**域内数据集**,大学数学为**域外数据集**。下表中的性能均基于[Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)微调得到,仅Xwin-Math-V1.1基于[Llama2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf)构建。**加粗**与*斜体*分别代表当前最优与次优得分。</sup>
## 数据集构建: `DARS` - 难度感知拒绝采样
以往的工作通常通过专有模型合成数据以扩充现有数据集,随后进行指令微调以获得顶尖性能。
然而,我们对这些数据集的分析揭示了**严重的简单样本偏向问题:对于最具挑战性的查询,模型经常无法生成任何正确响应**。
基于上述观察,我们提出了*难度感知拒绝采样*(`DARS`),旨在为高难度查询收集更多响应。具体而言,我们引入了两种策略以提升高难度查询的正确响应数量:
1) **Uniform策略**:为每个查询采样响应,直到**每个查询累计获得$k_u$个正确响应**,其中$k_u$为预设超参数,由合成数据集的目标规模决定;
2) **Prop2Diff策略**:持续采样响应,直到每个查询的正确响应数量**与其难度得分成正比**。最难的查询将获得$k_p$个响应,$k_p$为超参数。该策略刻意采用与基础版拒绝采样相反的偏向性,面向高难度查询,这一设计灵感来自先前研究,后者证明**困难样本可更有效地提升模型能力** ([Sorscher et al., 2022](https://proceedings.neurips.cc/paper_files/paper/2022/hash/7b75da9b61eda40fa35453ee5d077df6-Abstract-Conference.html); [Liu et al., 2024b](https://openreview.net/forum?id=BTKAeLqLMw)).
详见[图1(右图)](https://tongyx361.github.io/assets/dart-math/main-nresp-vs-query.png),展示了由`DARS-Uniform`构建的`DART-Math-Uniform`与由`DARS-Prop2Diff`构建的`DART-Math-Hard`的示例。
## 引用
若您的工作中使用了本项目的数据、模型或代码,请引用[我们的论文](https://arxiv.org/abs/2407.13690):
latex
@article{tong2024dartmath,
title={DART-Math: 面向数学解题的难度感知拒绝调优},
author={Tong Yuxuan and Zhang Xiwen and Wang Rui and Wu Ruidong and He Junxian},
year={2024},
eprint={2407.13690},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.13690},
}
提供机构:
maas创建时间:
2025-02-17
搜集汇总
数据集介绍
背景与挑战
背景概述
DART-Math-Uniform是一个用于数学推理的开源指令调优数据集,包含约591k个样本,采用难度感知拒绝采样(DARS-Uniform)方法构建,旨在平衡查询难度。该数据集在多个数学基准测试中表现出色,是当前最先进的数据高效型数据集之一。
以上内容由遇见数据集搜集并总结生成


