annotators
收藏Hugging Face2026-01-19 更新2026-01-20 收录
下载链接:
https://huggingface.co/datasets/just-dna-seq/annotators
下载链接
链接失效反馈官方服务:
资源简介:
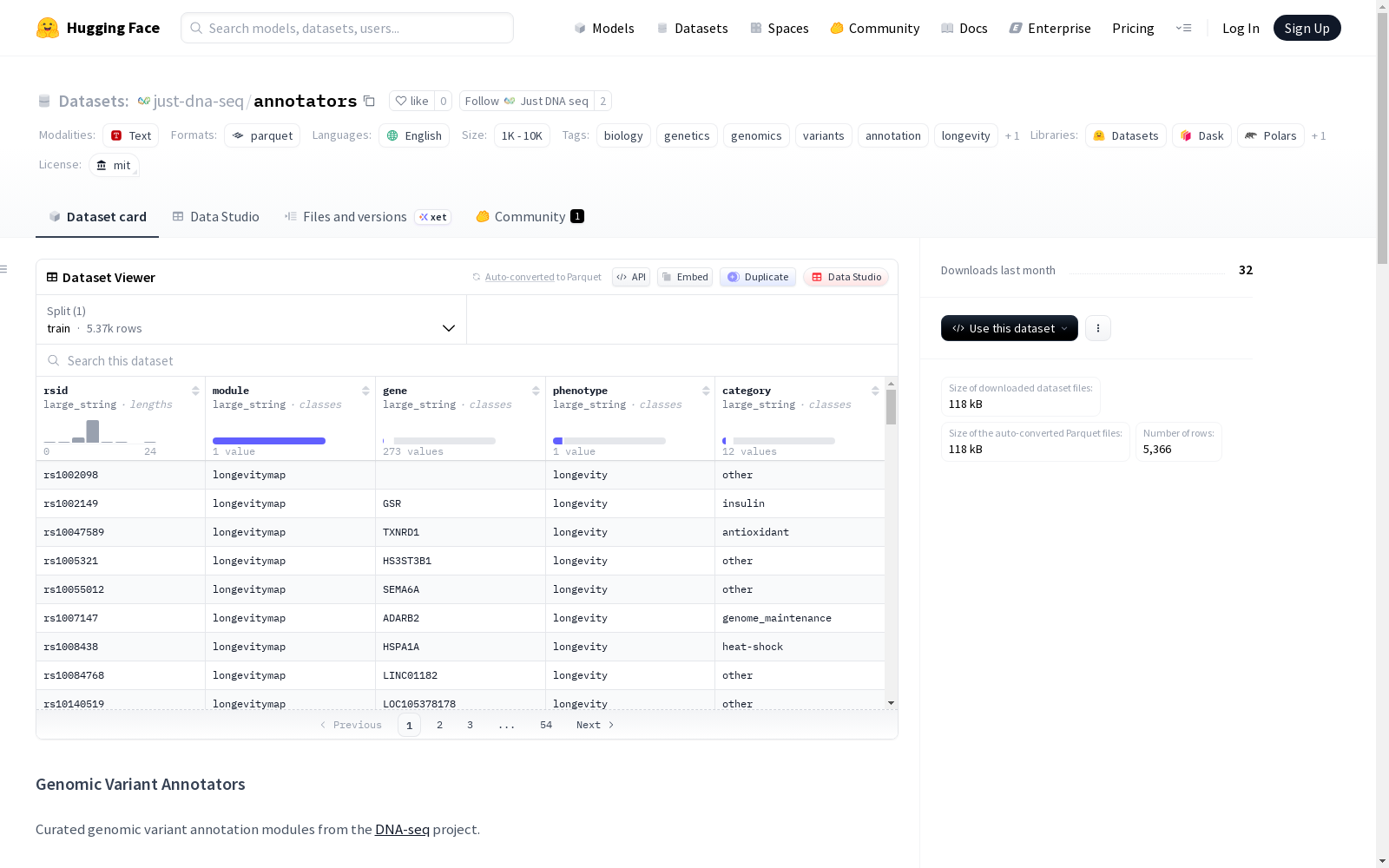
该数据集包含预计算的遗传变异注释数据,由DNA-seq项目整理。具体包含一个名为'longevitymap'的模块,涉及与长寿相关的变异。数据集包含三个文件:annotations.parquet(记录变异级别的事实,如rsID、基因、表型等)、studies.parquet(记录科学出版物中的研究证据,如PubMed ID、研究人群、统计显著性等)和weights.parquet(记录变异影响的评分,如基因型、权重、状态等)。数据集适用于生物学、遗传学、基因组学、变异注释、长寿和药物基因组学等领域的研究。
创建时间:
2026-01-15
原始信息汇总
Genomic Variant Annotators 数据集概述
数据集基本信息
- 数据集名称: Genomic Variant Annotators
- 发布者/组织: just-dna-seq
- 许可证: MIT License
- 领域标签: 生物学、遗传学、基因组学、变异、注释、长寿、药物基因组学
- 语言: 英语
- 数据规模: 1K<n<10K
- 总文件数: 3
- 总大小: 0.11 MB
数据集内容概述
本数据集包含来自 DNA-seq 项目的预计算遗传变异注释数据,按模块组织。目前包含一个模块:
- 模块名称: longevitymap
- 模块描述: 长寿相关变异
- 包含文件:
annotations.parquet,studies.parquet,weights.parquet
数据模式与结构
annotations.parquet
包含变异水平的事实信息,将rsID与基因和表型关联。
rsid: dbSNP参考IDmodule: 源模块名称gene: 相关基因符号phenotype: 相关表型/性状category: 功能类别
studies.parquet
包含来自科学文献的每项研究证据。
rsid: dbSNP参考IDmodule: 源模块名称pmid: PubMed IDpopulation: 研究人群p_value: 统计显著性conclusion: 研究结论study_design: 研究类型
weights.parquet
包含策展人定义的变异影响评分。
rsid: dbSNP参考IDgenotype: 基因型(列表形式,例如 ["C", "T"])module: 源模块名称weight: 数值权重state: "protective"(保护性)、"risk"(风险)或"neutral"(中性)priority: 优先级conclusion: 策展人结论curator: 策展人姓名method: 策展方法
使用方式
可以使用Polars库从HuggingFace加载数据: python import polars as pl weights = pl.read_parquet("hf://datasets/just-dna-seq/annotators/data/longevitymap/weights.parquet") studies = pl.read_parquet("hf://datasets/just-dna-seq/annotators/data/longevitymap/studies.parquet") annotations = pl.read_parquet("hf://datasets/just-dna-seq/annotators/data/longevitymap/annotations.parquet")
引用要求
使用本数据时,请引用原始来源:
- LongevityMap: https://longevitymap.org/
搜集汇总
数据集介绍
构建方式
在基因组学领域,精准的变异注释对于理解遗传变异与表型关联至关重要。该数据集源自DNA-seq项目,通过系统化整合LongevityMap等权威数据库,构建了结构化的变异注释模块。其构建过程涉及从科学文献中提取长寿相关变异,并依据dbSNP参考ID进行标准化映射,最终形成涵盖基因关联、表型信息和功能分类的注释体系。数据以Parquet格式存储,确保了高效的数据压缩与快速查询能力。
特点
该数据集的核心特点在于其模块化设计,专注于长寿相关遗传变异的注释。每个模块包含三个关键文件:annotations.parquet提供变异与基因、表型的基础关联;studies.parquet整合了来自PubMed的文献证据,包括研究人群、统计显著性和结论;weights.parquet则引入了人工策展的权重评分,明确标注变异的风险、保护或中性状态。这种分层结构不仅支持多维度分析,还通过策展结论和优先级设置增强了数据的可解释性。
使用方法
利用该数据集时,研究人员可通过Polars库直接加载Parquet文件进行高效分析。典型工作流程包括:首先加载权重文件以评估变异的功能影响,随后结合研究证据文件验证统计显著性,最后通过注释文件关联特定基因与表型。数据集支持基于rsID的快速检索,便于整合到基因组学管道中,用于长寿遗传机制探索或药物基因组学应用。其轻量级设计和标准化格式也适合大规模生物信息学平台的集成。
背景与挑战
背景概述
随着基因组学研究的深入,遗传变异的功能注释成为连接基因型与表型的关键桥梁。annotators数据集由DNA-seq项目团队构建,专注于整合长寿相关遗传变异的注释信息,其核心研究问题在于系统化地关联单核苷酸多态性(SNP)与特定基因、表型及科学证据,以支持衰老生物学和药物基因组学领域的探索。该数据集通过结构化模块(如longevitymap)提供预计算的注释、研究证据和权重评分,为研究人员解析遗传变异在复杂性状中的作用机制提供了标准化资源,显著提升了数据可及性与分析效率。
当前挑战
在基因组变异注释领域,主要挑战在于如何准确、全面地解读海量遗传变异的功能意义,特别是在长寿等复杂性状中,变异效应往往受多基因和环境因素交互影响,导致注释的准确性与一致性难以保证。构建annotators数据集时,团队面临数据整合的复杂性,需从异构的科学文献(如PubMed)和数据库(如dbSNP)中提取并标准化证据,同时依赖人工策展来定义变异权重和状态,这一过程易受策展者主观判断和知识更新滞后的限制,且当前模块覆盖范围较为有限,扩展至更多疾病或性状模块仍需大量策展努力。
常用场景
经典使用场景
在基因组学研究中,annotators数据集为长寿相关遗传变异提供了标准化的注释框架。研究人员利用其预计算的变异注释数据,能够快速识别与长寿表型关联的基因位点,如通过rsID链接基因和表型信息,从而支持大规模遗传关联分析。该数据集通过模块化结构整合了变异事实、研究证据和权重评分,为探索复杂性状的遗传基础提供了高效工具。
实际应用
在实际应用中,annotators数据集被广泛用于生物信息学流水线和临床基因组解读。例如,在药物基因组学中,研究人员利用其权重评分模块评估变异对药物反应的潜在影响,辅助个性化治疗策略的制定。同时,该数据集支持健康风险评估工具的开发,通过整合保护性或风险性变异状态,为预防医学和健康管理提供数据支撑。
衍生相关工作
基于annotators数据集,衍生出多项经典研究工作。例如,在长寿遗传学领域,研究者利用其注释模块构建了多基因风险评分模型,以预测个体长寿倾向。此外,该数据集促进了整合多组学数据的分析流程开发,如将变异注释与表达定量性状位点信息结合,深入解析基因调控网络。这些工作显著拓展了基因组注释在复杂性状研究中的应用边界。
以上内容由遇见数据集搜集并总结生成


