atlasia/MoulSot-Full
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/atlasia/MoulSot-Full
下载链接
链接失效反馈官方服务:
资源简介:
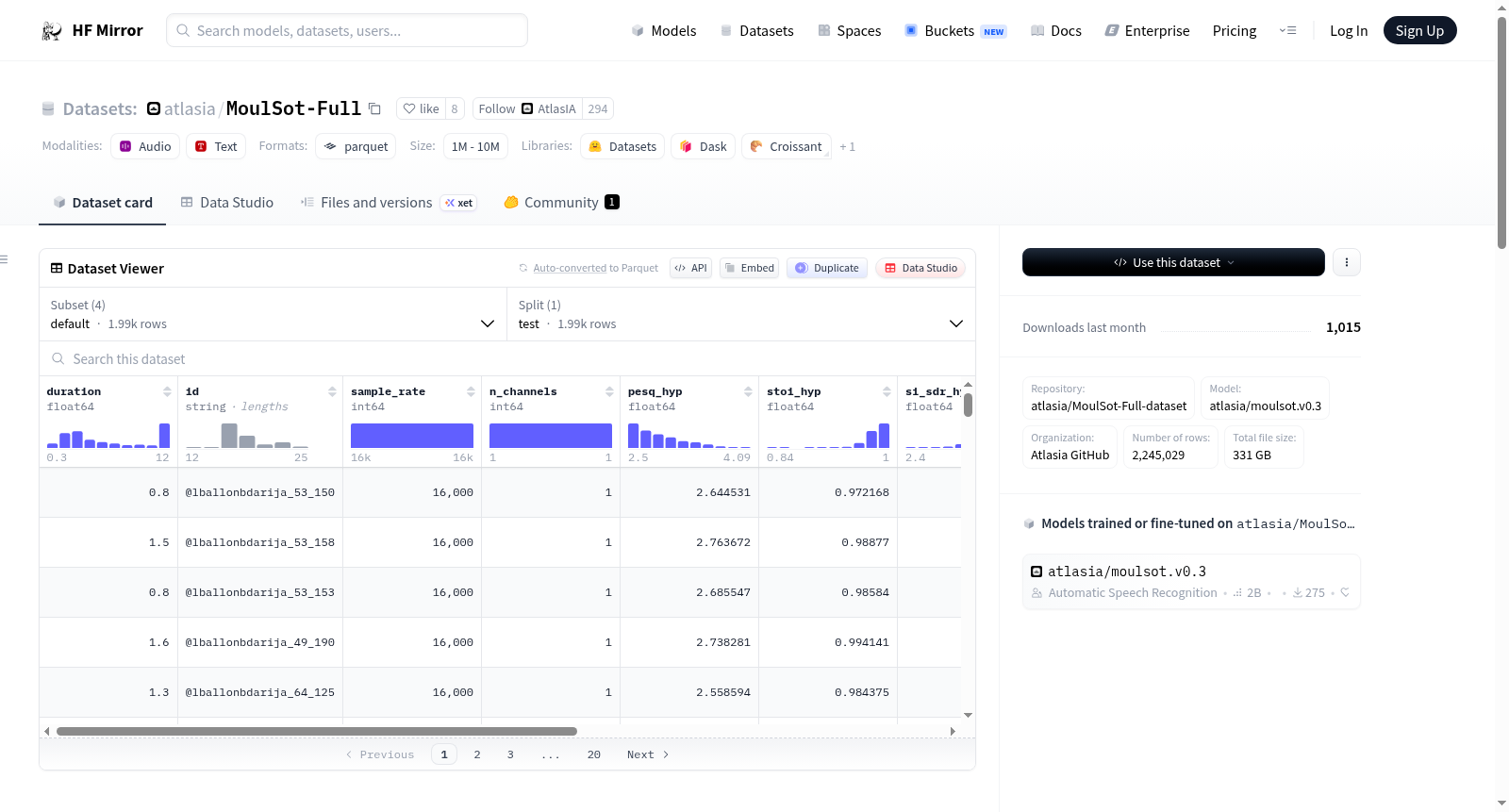
MoulSot-Full是一个大规模的摩洛哥达里贾语(Darija)语音数据集,包含总计1500小时的语音音频。其中约80小时是经过精心筛选和转录的高质量子集。数据集构建自公开的YouTube内容,涵盖51个不同频道(包括vlog、播客、访谈和评论等),以捕捉真实的摩洛哥达里贾语使用情况,包括与法语的自然代码转换、各种地区方言和不同的声学条件。数据集处理使用了自动化的流程,包括语音活动检测、音频质量评分、语音增强和自动转录。该数据集用于微调MoulSot.0.3模型以进行摩洛哥达里贾语语音识别。
MoulSot-Full is a large-scale Moroccan Darija speech dataset containing in total 1,500 hours of speech audio. From this extensive corpus, a high-quality subset of approximately 80 hours has been carefully curated and transcribed. It was built entirely from publicly available YouTube content across 51 diverse channels (including vlogs, podcasts, interviews, and commentary) to capture real-world Moroccan Darija, including natural code-switching with French, various regional dialects, and diverse acoustic conditions. The dataset was processed using an automated pipeline involving voice activity detection, audio quality scoring, speech enhancement, and automated transcription. This dataset was used to fine-tune the MoulSot.0.3 model for Moroccan Darija speech recognition.
提供机构:
atlasia
搜集汇总
数据集介绍
构建方式
MoulSot-Full数据集是面向摩洛哥阿拉伯语(Darija)的大规模语音语料库,总计约1500小时的音频数据。其构建起始于从51个YouTube公开频道(涵盖播客、访谈、评论等)收集的约3570个视频作为原始素材。随后,通过一系列自动化流程对数据进行清洗与增强:利用Silero VAD进行语音活动检测,去除静音与非语音片段;运用SQUIM工具计算PESQ与STOI等音质评分,并结合Meta的Audiobox Aesthetics评估生产质量与内容有用性,筛选出单个说话人片段且时长在3至25秒之间的优质段落;针对低质量音频调用DNS64进行增强。最终,从高质量子集中严格挑出PESQ评分大于2.5的片段,共计约80小时,并借助Gemini 2.5 Pro模型自动生成阿拉伯语转录文本,保留法语等代码转换词的拉丁原文。
特点
该数据集最显著的特点在于其规模与多样性的有机融合。1500小时的原始音频覆盖了真实世界中的复杂声学环境与多种地域变体,而精细筛选出的80小时高质量子集则保证了作为监督训练基准的纯净度。数据集中不仅包含语音信号本身,还附有PESQ、STOI、SI-SDR等多维音质指标,为研究者提供了灵活选择子集的可能性。尤为特殊的是,转录文本刻意保留了摩洛哥日常会话中与法语、英语、西班牙语自然混用的代码转换现象,将拉丁字母原样穿插于阿拉伯文之间,这一设计精准捕捉了Darija的语用实态,使其区别于仅聚焦单语种的常规语音库。数据分割为训练集(约79857条)与测试集(约1993条),并额外提供了未转录的1500小时全集,便于无监督或半监督学习探索。
使用方法
该数据集与HuggingFace Datasets库原生兼容,用户可通过指定配置名称灵活调用不同子集。对于监督学习场景,推荐加载'100-gt-2.5'配置下的训练与测试分割,其中每条样本均包含16kHz单声道音频、对应文本以及PESQ等质量元数据,可直接用于端到端语音识别模型的训练与评估。若需利用海量未标注数据,则可选用'extra-gt-2.5'或'extra-lt-2.5'配置,它们分别提供千小时级别的音频及对应的音质评分,适合预训练、自监督学习或弱监督训练。在使用时,开发者可依据自身的质量偏好,基于'pesq_hyp'等字段进行二次过滤,构建定制化子集。该数据集已成功用于微调MoulSot.v0.3模型,并为摩洛哥Darija语音研究社区提供了可复现的基准。
背景与挑战
背景概述
MoulSot-Full 数据集由 Atlasia 团队于2026年创建,旨在解决摩洛哥阿拉伯语(Darija)这一低资源语言的语音识别难题。尽管摩洛哥阿拉伯语拥有超过3000万使用者,但长期以来缺乏大规模、高质量的语音数据集,严重限制了该语言自动语音识别(ASR)技术的发展。该数据集从51个YouTube频道中收集了约1500小时的公开音频内容,涵盖博客、播客、访谈及评论等真实场景,并特别保留了与法语、英语、西班牙语的代码转换现象。其中约80小时的高质量子集经过精心筛选与自动标注,用于微调MoulSot.0.3模型,为达里加语ASR领域提供了首个大规模、多样化的基准资源。
当前挑战
MoulSot-Full 面临的核心挑战在于克服低资源语料下的数据稀缺性与复杂性。领域问题层面,摩洛哥阿拉伯语缺乏标准化书写体系,且口语中存在广泛的方言差异与代码转换,传统ASR模型难以直接迁移。构建过程中,团队需从非结构化YouTube视频中分离有效语音片段,采用Voice Activity Detection、音频质量评分(PESQ、STOI)及语音增强等多步自动化流水线,处理质量参差的现场录音。此外,自动转录依赖Gemini 2.5 Pro大模型,需在保留阿拉伯脚本的同时精准保持拉丁字母拼写的法语借词,对标注一致性要求极高。数据去重、说话人分割(基于Pyannote 3.1)及单说话人片段筛选进一步增加了工程复杂度。
常用场景
经典使用场景
在低资源语言语音识别的研究领域中,MoulSot-Full数据集以其涵盖摩洛哥阿拉伯语(Darija)的1,500小时大规模语音数据脱颖而出。该数据集精心筛选了约80小时的高质量已标注子集,广泛应用于构建与微调端到端自动语音识别(ASR)模型。其经典使用场景在于,研究者能够利用其丰富多样的真实世界语音样本(涵盖博客、播客、访谈等51个频道),结合质量评分元数据(如PESQ、STOI),训练出能够稳健处理多方言、自然语码转换及复杂声学环境的语音识别系统。MoulSot-Full为资源匮乏的方言语音建模提供了标准化基准和可复现的评测平台。
实际应用
在实际产业应用中,MoulSot-Full数据集所驱动的语音识别技术已展现出显著价值。基于该数据集微调的MoulSot.0.3模型,能够高效服务于摩洛哥本土的智能客服系统,例如在银行、电信及电商领域中自动处理客户对话,准确辨识混杂法语和方言的话语。此外,新闻媒体与播客平台可借助其进行自动语音转写与字幕生成,提升内容可及性与传播效率。在语音助手和车载交互设备中,该数据集支持的ASR模型赋予机器理解摩洛哥多元口语表达的能力,从而提供更为精准的本地化服务。通过弥合标准阿拉伯语与日常方言之间的鸿沟,MoulSot-Full正逐步融入教育、医疗等关键领域的语音工具,展现出广泛的规模化落地前景。
衍生相关工作
MoulSot-Full数据集的诞生催生了一系列富有影响力的衍生研究工作。其自身便是ATLASIA团队研发的MoulSot.0.3语音识别模型的核心训练基石,该模型在摩洛哥阿拉伯语ASR任务上取得了显著性能突破。围绕该数据集,研究者们进一步探索了自动语音质量评估(SQUIM、Audiobox Aesthetics)与声学特征增强技术(DNS64)的协同优化策略,相关成果为低资源语音数据库构建提供了方法论参考。同时,基于MoulSot-Full的语料,学术界已开展关于语码转换语音识别鲁棒性、多方言联合建模以及大语言模型零样本语音标注等前沿课题的深入探讨,这些工作不仅推动了北非方言语音处理技术的进步,也丰富了跨语言迁移学习与语音-语言联合学习的理论体系。
以上内容由遇见数据集搜集并总结生成


