Natural-Reasoning-gpt-oss-120B-S1
收藏魔搭社区2026-01-07 更新2025-09-27 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/Natural-Reasoning-gpt-oss-120B-S1
下载链接
链接失效反馈官方服务:
资源简介:
### **Dataset Card: Natural-Reasoning-gpt-oss-120B-S1**
---
#### **📜 Dataset Overview**
This is a meticulously curated instruction fine-tuning dataset designed specifically for efficient knowledge distillation tasks. Built upon the first 100,000 questions from the large-scale reasoning corpus **facebook/natural_reasoning** (s1, I will process the remaining parts later), it aims to transfer the advanced, multi-step reasoning capabilities of the teacher model **gpt-oss-120-high** to a student model with high fidelity through a Supervised Fine-Tuning (SFT) paradigm.
**facebook/natural_reasoning** itself is a comprehensive dataset containing 2.8 million challenging questions derived from real-world scenarios, covering multiple domains such as STEM, economics, and social sciences. It is renowned for its high quality, difficulty, and diversity.

---
#### **🚀 Curation into a Reasoning Dataset**
* **State-of-the-Art Teacher Model** The answers in the original paper were generated by **Llama-3.3-70B-Instruct**. This dataset, however, utilizes one of the current most powerful open-source models, **gpt-oss-120b-high**, for answer generation. This means the quality, reasoning depth, and accuracy of the answers in this dataset have reached new heights, providing a superior learning template for student models.

* **Chain-of-Thought Distillation** This dataset provides not only the final answers but also explicitly includes the complete **CoT_reasoning (Chain-of-Thought)** field from the teacher model. This enables "Chain-of-Thought distillation," where the student model learns not just "what" (the answer) but also "why" (the reasoning process). This method is crucial for developing the model's intrinsic logical abilities to solve complex problems and can more effectively stimulate its long-chain reasoning capabilities.
* **Systematic Integration of Reference Answers** This dataset systematically organizes and integrates the reference answers provided in the original `natural_reasoning` dataset. According to the original paper, approximately **81.7%** of the questions in the base dataset come with reference answers. This dataset includes these valuable "ground truth" answers. For questions without a reference answer, the corresponding field is left empty, ensuring a clear and consistent data structure. This integration significantly enriches the application scenarios of the dataset, allowing it to be directly used for more complex training paradigms such as answer validation and preference pair construction (e.g., DPO).
---
#### **📊 Dataset Specifications**
* **Dataset Name**: `Natural-Reasoning-gpt-oss-120B-S1`
* **Base Dataset**: `facebook/natural_reasoning`
* **Teacher Model**: `gpt-oss-120-high`
* **Language**: English
* **Data Format**: JSON format suitable for Supervised Fine-Tuning, including `question` 、`answer` and `reference_answer` fields.
---
#### **🛠️ Genesis & Curation Process**
The construction process of this dataset is divided into two core stages:
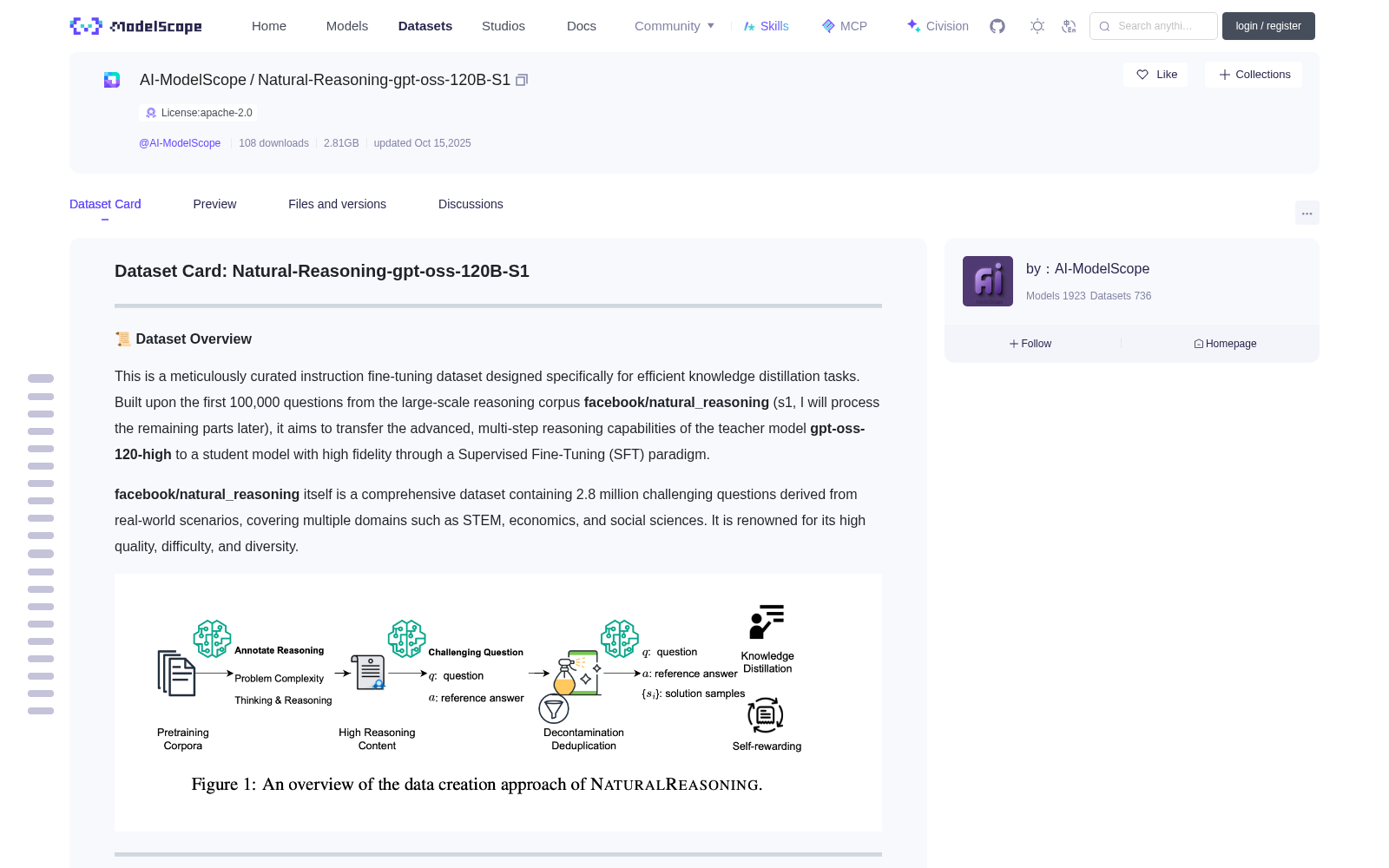
**Stage One: Generation of the Base Dataset (`facebook/natural_reasoning`)**
This stage is entirely driven by large language models, achieving a fully automated data production pipeline without manual annotation.
* **Source Corpora**: Data was mined from high-quality public pre-training corpora `DCLM-baseline` and `FineMath`.
* **Reasoning Annotation**: LLMs were used to evaluate source documents across multiple dimensions (e.g., question complexity, technical depth, reasoning) to accurately filter for high-value content containing complex reasoning logic.
* **QA Synthesis**: For the selected high-quality documents, LLMs were prompted to create new, independent, and challenging reasoning questions and their reference answers. This method ensures the novelty of the questions, rather than simple extraction from the original text.
* **Decontamination**: Strict deduplication and decontamination strategies were implemented, removing samples highly similar to mainstream reasoning benchmarks (such as MATH, GPQA, MMLU-Pro) to ensure the purity of the dataset and the fairness of evaluations.
**Stage Two: Generation of This Distillation Dataset**
* **Question Sampling**: Sequentially selected the first 100,000 high-quality questions from the `facebook/natural_reasoning` dataset.
* **Reasoning Chain Generation**: Used `gpt-oss-120-high` as the teacher model to generate a detailed thought process (Chain-of-Thought) and the final answer for each question, forming the training samples for distillation.
---
#### **🧬 Data Structure & Fields**
Each sample is a JSON object containing the following fields:
* `generator`: Identifies the name of the teacher model that generated the answer, which is `gpt-oss-120-high` here.
* `question`: A challenging reasoning question from the `facebook/natural_reasoning` dataset.
* `CoT_reasoning`: The detailed, raw "Chain-of-Thought" process generated by the teacher model. This field records the internal logic and reasoning steps the model took to solve the problem, which is crucial for analyzing the model's thought process.
* `anwser`: The final, formatted answer generated by the teacher model. This is the core content for distillation and the target output for the student model to learn.
* `reference_answer`: The reference answer provided by the base `facebook/natural_reasoning` dataset. This field can be used for various purposes, such as:
* Validating or evaluating the correctness of the answers generated by the teacher model.
* Constructing preference pairs for preference learning (e.g., DPO).
* Serving as an alternative training target.
* **Please note**: The original paper mentions that the reference answers may contain a small amount of noise.
---
#### **🎯 Intended Use & Applications**
* **Core Application**: To serve as the core data for a knowledge distillation pipeline, injecting the capabilities of a powerful teacher model into smaller or more efficient student models through supervised fine-tuning.
* **Capability Enhancement**: Focused on improving a model's general reasoning abilities on complex problems across multiple domains 🧠.
* **High Sample Efficiency**: The original paper for `facebook/natural_reasoning` demonstrated that training with this dataset is highly sample-efficient, achieving excellent performance improvements with a smaller amount of data.
* **Stimulating Long-Chain Thinking**: The questions in the dataset are complex enough to effectively stimulate the model to produce longer and deeper reasoning paths (CoT), which is crucial for solving difficult problems.
---
#### **✅ Core Attributes & Quality**
This dataset inherits all the excellent characteristics of `facebook/natural_reasoning`:
* **High Quality & High Difficulty**: The base dataset contains up to 93% high-quality questions and received the highest scores in human expert evaluations. The complexity of the questions is reflected in their extremely long median answer length (434 words), far exceeding other similar datasets.
* **Thematic Diversity**: The coverage extends far beyond traditional mathematics, showing a denser and more diverse distribution in non-mathematical subjects such as physics, computer science, and law.
* **Question Depth**: The average question length is 55 words, containing rich contextual information and multi-step requirements that compel the model to perform deeper semantic understanding and reasoning.
---
#### **⚠️ Limitations & Ethical Considerations**
* **Bias Inheritance**: The dataset may inherit potential biases present in the source pre-training corpora or the LLMs used to generate the data.
* **Answer Reliability**: Although the reference answers in the base dataset have been shown to be useful in experiments, they may still contain a small amount of noise.
* **Downstream Evaluation**: It is strongly recommended to conduct comprehensive and responsible safety and bias evaluations before deploying any model trained on this dataset.
---
#### **🙏 Citation**
Thanks to the original authors of `facebook/natural_reasoning` for their outstanding contributions.
```bibtex
@misc{yuan2025naturalreasoning,
title={NATURALREASONING: Reasoning in the Wild with 2.8M Challenging Questions},
author={Weizhe Yuan and Ilia Kulikov and Jane Yu and Song Jiang and Karthik Padthe and Yang Li and Yuandong Tian and Xian Li and Kyunghyun Cho and Dong Wang and Jason Weston},
year={2025},
eprint={2502.13124},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
>中文翻译
### **Dataset Card: Natural-Reasoning-gpt-oss-120B-S1**
---
#### **📜 数据集概览 (Dataset Overview)**
这是一个精心策划的指令微调数据集,专为高效的知识蒸馏任务而设计。该数据集基于大规模推理语料库 **facebook/natural_reasoning** 的前10万个问题构建(s1,后续我会做剩下的部分),旨在将教师模型 **gpt-oss-120-high** 的高级、多步骤推理能力,通过监督式微调(SFT)范式,高保真地迁移至学生模型。
**facebook/natural_reasoning** 本身是一个包含280万个挑战性问题的综合性数据集,其问题源于真实世界场景,覆盖STEM、经济学、社会科学等多个领域,以其高质量、高难度和多样性而著称。
---
#### **🚀 整理成为推理数据集**
* **更强的教师模型 (State-of-the-Art Teacher Model)**
原始论文中的答案由 **Llama-3.3-70B-Instruct** 生成,本数据集则采用了当前性能最强的开源模型之一 **gpt-oss-120b-high** 进行答案生成。这意味着本数据集中的答案质量、推理深度和准确性都达到了新的高度,为学生模型提供了一个更优质的学习范本。
* **思维链蒸馏 (Chain-of-Thought Distillation)**
本数据集不仅提供了最终答案,还显式包含了教师模型完整的 `CoT_reasoning`(思维链)字段。这使得“思维链蒸馏”成为可能,即学生模型不仅学习“是什么”(答案),更学习“为什么”(推理过程)。这种方法对于培养模型解决复杂问题的内在逻辑能力至关重要,能够更有效地激发其长链思维能力。
* **参考答案的系统性整合 (Systematic Integration of Reference Answers)**
本数据集系统性地整理并集成了 `natural_reasoning` 原始数据集中提供的参考答案。根据原始论文,基础数据集中约有 **81.7%** 的问题附带了参考答案,本数据集将这些宝贵的“标准答案”一并提供。对于没有参考答案的问题,相应字段会留空,数据结构清晰一致。这一整合极大地丰富了数据集的应用场景,使其可以直接用于答案校验、偏好对构建(如 DPO)等更复杂的训练范式中。
---
#### **📊 数据集规格 (Dataset Specifications)**
* **数据集名称**: `Natural-Reasoning-gpt-oss-120B-S1`
* **基础数据集**: `facebook/natural_reasoning`
* **教师模型**: `gpt-oss-120-high`
* **语言**: 英语 (English)
* **数据格式**: 适用于监督式微调的JSON格式,包含 `question` 和 `answer` 字段。
---
#### **🛠️ 构建流程 (Genesis & Curation Process)**
本数据集的构建流程分为两个核心阶段:
**阶段一:基础数据集的生成 (`facebook/natural_reasoning`)**
该阶段完全由大型语言模型驱动,实现了无人工标注的全自动化数据生产管线 。
* **源语料 (Source Corpora)**: 数据挖掘自高质量的公开预训练语料库 `DCLM-baseline` 和 `FineMath`。
* **推理内容标注 (Reasoning Annotation)**: 利用LLM对源文档进行多维度评估(如问题复杂度、技术深度、思维推理等),以精准筛选出蕴含复杂推理逻辑的高价值内容。
* **问答合成 (QA Synthesis)**: 针对筛选出的高质量文档,驱动LLM创作全新的、独立的、有挑战性的推理问题及其参考答案。此方法确保了问题的新颖性,而非简单地从原文中提取。
* **数据净化 (Decontamination)**: 实施严格的去重和去污染策略,移除了与主流推理基准(如MATH, GPQA, MMLU-Pro)高度相似的样本,保证了数据集的纯净度和评估的公正性。
**阶段二:本蒸馏数据集的生成**
* **问题抽样**: 从 `facebook/natural_reasoning` 数据集中顺序选取前100,000个高质量问题。
* **推理链生成**: 利用 `gpt-oss-120-high` 作为教师模型,为每个问题生成详尽的思考过程(Chain-of-Thought)和最终答案,构成用于蒸馏的训练样本。
---
#### **🧬 数据结构与字段说明 (Data Structure & Fields)**
每个样本都是一个JSON对象,包含以下字段:
* `generator`: 标识生成答案的教师模型的名称,此处为 `gpt-oss-120-high`。
* `question`: 具有挑战性的推理问题,源自 `facebook/natural_reasoning` 数据集。
* `CoT_reasoning`: 由教师模型生成的详细、原始的“思考链”(Chain-of-Thought)过程。此字段记录了模型解决问题的内部逻辑和推理步骤,对于分析模型思维过程至关重要。
* `anwser`: 教师模型生成的最终格式化答案。这是用于蒸馏的核心内容,是学生模型需要学习的目标输出。
* `reference_answer`: 源自 `facebook/natural_reasoning` 基础数据集提供的参考答案。此字段可用于多种目的,例如:
* 对教师模型生成的答案进行正确性校验或评估。
* 在偏好学习(如DPO)中构建优劣对比对。
* 作为备选的训练目标。
* **请注意**: 原始论文提到参考答案可能含有少量噪音。
---
#### **🎯 预期用途与应用 (Intended Use & Applications)**
* **核心应用**: 作为知识蒸馏流水线的核心数据,通过监督式微调,将强大的教师模型能力注入到更小或更高效的学生模型中。
* **能力提升**: 专注于提升模型在多领域复杂问题上的通用推理能力 🧠。
* **高样本效率**: `facebook/natural_reasoning` 的原始论文证明,使用该数据集进行训练具有极高的样本效率,能以更少的数据量实现卓越的性能提升。
* **激发长链思维**: 数据集中的问题足够复杂,能够有效激发模型产生更长、更深入的推理路径(CoT),这对于解决难题至关重要。
---
#### **✅ 核心属性与质量 (Core Attributes & Quality)**
本数据集继承了 `facebook/natural_reasoning` 的全部优良特性:
* **高质量与高难度**: 基础数据集包含高达93%的高质量问题,并在人类专家评估中获得最高分。问题的复杂性体现在其极长的中位答案长度(434个词),远超其他同类数据集。
* **主题多样性**: 覆盖面远超传统的数学领域,在物理、计算机科学、法律等非数学主题上展现出更密集和多样化的分布。
* **问题深度**: 平均问题长度为55个词,包含了丰富的上下文信息和多步骤要求,迫使模型进行更深层次的语义理解和推理。
---
#### **⚠️ 限制与道德考量 (Limitations & Ethical Considerations)**
* **偏见遗传**: 数据集可能继承了源预训练语料库或用于生成数据的LLM中存在的潜在偏见。
* **答案可靠性**: 尽管基础数据集中的参考答案在实验中被证明是有用的,但它们仍可能包含少量噪音。
* **评估**: 强烈建议在部署任何基于此数据集训练的模型之前,进行全面、负责任的安全与偏见评估。
---
#### **🙏 引用信息 (Citation)**
`facebook/natural_reasoning` 感谢原作者的卓越贡献。
```bibtex
@misc{yuan2025naturalreasoning,
title={NATURALREASONING: Reasoning in the Wild with 2.8M Challenging Questions},
author={Weizhe Yuan and Ilia Kulikov and Jane Yu and Song Jiang and Karthik Padthe and Yang Li and Yuandong Tian and Xian Li and Kyunghyun Cho and Dong Wang and Jason Weston},
year={2025},
eprint={2502.13124},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### **数据集卡片:Natural-Reasoning-gpt-oss-120B-S1**
---
#### **📜 数据集概览**
本数据集为专为高效知识蒸馏任务打造的精心打磨的指令微调数据集,基于大规模推理语料库**facebook/natural_reasoning**的前10万个问题构建(注:s1版本后续将补充剩余内容),旨在通过监督式微调(Supervised Fine-Tuning, SFT)范式,将教师模型**gpt-oss-120-high**的高级多步推理能力高保真地迁移至学生模型。
**facebook/natural_reasoning**本身是一个包含280万个源自真实场景的挑战性问题的综合性数据集,覆盖STEM、经济学、社会科学等多个领域,以其高质量、高难度与多样性而闻名。

---
#### **🚀 推理数据集整理流程**
* **顶尖教师模型** 原始论文中的答案由**Llama-3.3-70B-Instruct**生成,而本数据集则采用当前最强开源模型之一的**gpt-oss-120b-high**生成答案。这使得本数据集的答案质量、推理深度与精度均达到新高度,为学生模型提供了更优质的学习范本。

* **思维链蒸馏(Chain-of-Thought Distillation)** 本数据集不仅提供最终答案,还显式包含教师模型生成的完整**思维链推理(CoT_reasoning)**字段。这使得“思维链蒸馏”成为可能:学生模型不仅能学习“是什么”(答案),更能掌握“为什么”(推理过程)。该方法对培养模型解决复杂问题的内在逻辑能力至关重要,可更有效地激发其长链推理能力。
* **参考答案系统化整合** 本数据集系统性整理并整合了原始`natural_reasoning`数据集中的参考答案。根据原始论文,基础数据集中约**81.7%**的问题配有参考答案,本数据集保留了这些宝贵的“标准答案”。对于无参考答案的问题,对应字段留空,确保数据结构清晰统一。此次整合极大丰富了数据集的应用场景,可直接用于答案校验、偏好对构建(如DPO)等更复杂的训练范式。
---
#### **📊 数据集规格**
* **数据集名称**:`Natural-Reasoning-gpt-oss-120B-S1`
* **基础数据集**:`facebook/natural_reasoning`
* **教师模型**:`gpt-oss-120-high`
* **语言**:英语
* **数据格式**:适用于监督式微调的JSON格式,包含`question`(问题)、`answer`(答案)与`reference_answer`(参考答案)字段。
---
#### **🛠️ 数据集构建与整理流程**
本数据集的构建流程分为两个核心阶段:
**第一阶段:基础数据集(`facebook/natural_reasoning`)构建**
该阶段完全由大语言模型(Large Language Model, LLM)驱动,实现了无人工标注的全自动化数据生产流水线。
* **源语料**:数据挖掘自高质量公开预训练语料库`DCLM-baseline`与`FineMath`。
* **推理标注**:利用大语言模型从多维度(如问题复杂度、技术深度、推理逻辑)评估源文档,精准筛选出蕴含复杂推理逻辑的高价值内容。
* **问答合成**:针对筛选出的高质量文档,通过提示大语言模型生成全新、独立且具有挑战性的推理问题及其参考答案。该方法确保了问题的新颖性,而非简单从原文中提取。
* **数据净化**:实施严格的去重与去污染策略,移除与主流推理基准(如MATH、GPQA、MMLU-Pro)高度相似的样本,确保数据集纯净度与评估公平性。
**第二阶段:本蒸馏数据集构建**
* **问题抽样**:从`facebook/natural_reasoning`数据集中按序选取前10万个高质量问题。
* **推理链生成**:以`gpt-oss-120-high`作为教师模型,为每个问题生成详尽的思考过程(思维链,Chain-of-Thought)与最终答案,构成蒸馏训练样本。
---
#### **🧬 数据结构与字段说明**
每个样本为一个JSON对象,包含以下字段:
* `generator`:标识生成答案的教师模型名称,本数据集为`gpt-oss-120-high`。
* `question`:源自`facebook/natural_reasoning`数据集的挑战性推理问题。
* `CoT_reasoning`:教师模型生成的详细原始“思维链”过程。该字段记录了模型解决问题的内部逻辑与推理步骤,对分析模型思维过程至关重要。
* `anwser`:教师模型生成的最终格式化答案,为蒸馏的核心内容与学生模型学习的目标输出。
* `reference_answer`:源自基础数据集`facebook/natural_reasoning`的参考答案。该字段可用于多种场景,例如:
* 校验或评估教师模型生成答案的正确性
* 为偏好学习(如DPO)构建偏好对
* 作为备选训练目标
* **注意**:原始论文提及参考答案可能包含少量噪声。
---
#### **🎯 预期用途与应用场景**
* **核心用途**:作为知识蒸馏流水线的核心数据,通过监督式微调将强大教师模型的能力注入更小或更高效的学生模型。
* **能力增强**:专注于提升模型在多领域复杂问题上的通用推理能力 🧠。
* **高样本效率**:`facebook/natural_reasoning`的原始论文表明,使用本数据集训练具有极高的样本效率,可通过更少的数据量实现优异的性能提升。
* **激发长链思维**:数据集中的问题复杂度足够高,可有效激发模型生成更长、更深的推理路径(思维链,CoT),这对解决难题至关重要。
---
#### **✅ 核心属性与质量特性**
本数据集继承了`facebook/natural_reasoning`的全部优良特性:
* **高质量与高难度**:基础数据集包含高达93%的高质量问题,在人类专家评估中获得最高分。问题的复杂性体现在其极长的中位答案长度(434词),远超其他同类数据集。
* **主题多样性**:覆盖范围远超传统数学领域,在物理、计算机科学、法学等非数学学科上的分布更为密集与多样。
* **问题深度**:平均问题长度为55词,包含丰富的上下文信息与多步骤要求,迫使模型进行更深层次的语义理解与推理。
---
#### **⚠️ 局限性与伦理考量**
* **偏见继承**:本数据集可能继承源预训练语料库或用于生成数据的大语言模型中存在的潜在偏见。
* **答案可靠性**:尽管基础数据集中的参考答案在实验中被证明具有实用性,但仍可能包含少量噪声。
* **下游评估建议**:强烈建议在部署基于本数据集训练的模型前,开展全面且负责任的安全与偏见评估。
---
#### **🙏 引用信息**
感谢`facebook/natural_reasoning`的原作者所做出的卓越贡献。
bibtex
@misc{yuan2025naturalreasoning,
title={NATURALREASONING: Reasoning in the Wild with 2.8M Challenging Questions},
author={Weizhe Yuan and Ilia Kulikov and Jane Yu and Song Jiang and Karthik Padthe and Yang Li and Yuandong Tian and Xian Li and Kyunghyun Cho and Dong Wang and Jason Weston},
year={2025},
eprint={2502.13124},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
maas
创建时间:
2025-09-21
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专为知识蒸馏设计的指令微调数据集,基于facebook/natural_reasoning的前10万个问题,利用教师模型gpt-oss-120-high生成答案和思维链,以通过监督式微调提升学生模型的复杂推理能力。
以上内容由遇见数据集搜集并总结生成


