DeepScores
收藏arXiv2018-05-27 更新2024-06-21 收录
下载链接:
https://tuggeluk.github.io/deepscores/
下载链接
链接失效反馈官方服务:
资源简介:
DeepScores是一个专为小对象识别优化的大型公共数据集,由苏黎世应用科技大学数据实验室与大学创建。该数据集包含30万张高质量的音乐乐谱图像,总计近百亿个小对象,涵盖不同形状和大小。数据集通过合成音乐XML文件生成,提供对象分类、检测和语义分割的基准真相。DeepScores不仅为光学音乐识别(OMR)研究提供挑战,也适用于开发新一代计算机视觉方法,解决高分辨率图像中大量微小对象的问题。
DeepScores is a large public dataset optimized for small-object recognition, created by the Data Lab of the Zurich University of Applied Sciences and partner universities. This dataset contains 300,000 high-quality musical score images, totaling nearly 10 billion small objects with diverse shapes and sizes. Generated from synthesized MusicXML files, the dataset provides ground truth for object classification, detection, and semantic segmentation. DeepScores not only poses challenges for optical music recognition (OMR) research, but also serves as a valuable testbed for developing next-generation computer vision methods to tackle the issue of abundant tiny objects in high-resolution images.
提供机构:
苏黎世应用科技大学数据实验室与大学
创建时间:
2018-03-27
搜集汇总
数据集介绍
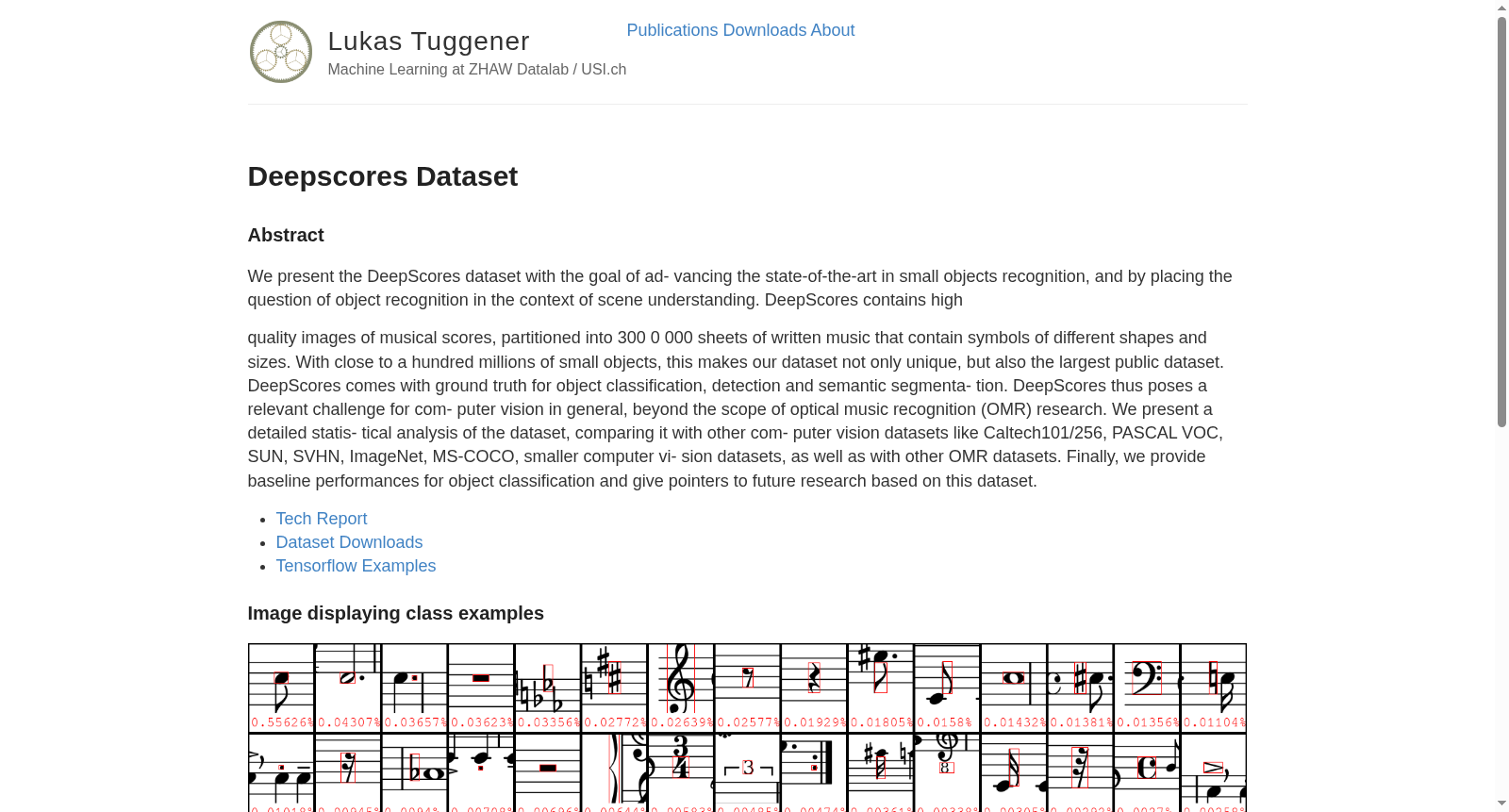
构建方式
在光学音乐识别领域,数据集的构建往往受限于真实乐谱的稀缺性与标注复杂性。DeepScores数据集通过创新性的合成方法,从MuseScore平台公开的MusicXML数字乐谱档案中,精心渲染出高质量图像。研究团队将代码注入LilyPond的SVG后端,使每个音符符号的路径携带元数据,进而映射到预定义的123个类别,并生成对应的边界框坐标与像素级语义分割标注。为确保数据的多样性与真实性,尽管所有图像均为数字渲染,团队采用了五种不同的音乐字体进行呈现,模拟了乐谱符号在形态上的细微差异。
特点
DeepScores数据集在计算机视觉领域展现出独特的数据特性,其核心在于处理高分辨率图像中密集分布的微小对象。该数据集包含约30万张乐谱页面,图像分辨率高达1894×2668像素,共标注近8000万个音乐符号,平均每页包含243个对象,远超PASCAL VOC、MS-COCO等传统数据集的对象密度。符号尺寸差异显著,面积从不足百像素到数千像素不等,且类别分布极不均衡,前10%的类别涵盖了85%以上的符号实例。更为复杂的是,符号的类别判定高度依赖于上下文环境,相同视觉形态的对象可能因周围符号的不同而归属不同类别,这为对象检测任务带来了严峻挑战。
使用方法
DeepScores为研究者提供了多任务学习的基础设施,支持对象分类、检测与语义分割。对于分类任务,数据集提供了以符号为中心的图像块,可直接用于训练卷积神经网络。在检测任务中,每张图像附带的XML文件详细记录了每个符号实例的类别与边界框信息,适用于评估区域提议网络等检测模型。语义分割任务则通过等尺寸的PNG标注文件实现,每个像素被赋予对应的类别标签。鉴于数据集中对象微小且密集的特性,传统检测模型如Faster R-CNN表现不佳,因此该数据集常被用于开发专注于微小对象识别的新一代全卷积网络架构,并可作为预训练源,通过迁移学习提升其他高分辨率图像分析任务的性能。
背景与挑战
背景概述
DeepScores数据集由ZHAW Datalab、USI及威尼斯大学的研究团队于2018年联合创建,旨在推动小物体识别技术在场景理解背景下的前沿发展。该数据集聚焦于光学音乐识别领域,通过合成高质量乐谱图像,提供了包含约30万张乐谱页、近8000万个微小音乐符号的标注资源,涵盖分类、检测与语义分割三大任务。其规模远超同期PASCAL VOC、MS-COCO等经典数据集,不仅为OMR研究填补了大规模训练数据的空白,更成为计算机视觉中高分辨率图像多目标检测的重要基准,促进了文档分析与通用物体识别方法的交叉创新。
当前挑战
DeepScores所针对的核心领域问题在于光学音乐识别中微小物体的密集检测与分类挑战。乐谱符号通常呈现尺寸差异显著、空间分布密集且类别高度不均衡的特性,加之符号语义常依赖上下文环境判断,这导致主流检测模型如YOLO、Faster R-CNN在此类场景下性能急剧下降。在数据集构建过程中,研究团队面临多重挑战:需从MusicXML数字乐谱中精确渲染并标注原子级音乐符号,涉及复杂字体适配与元数据映射;同时需平衡符号类别的定义粒度,在合成数据与现实乐谱多样性之间取得权衡,并确保标注体系兼顾音乐学规范与计算机视觉任务需求。
常用场景
经典使用场景
在计算机视觉领域,DeepScores数据集以其高分辨率图像和密集小对象特性,成为研究微小物体识别与场景理解的经典平台。该数据集包含30万张乐谱图像,涵盖近八千万个音乐符号实例,每个图像平均承载243个对象,对象尺寸从数十像素到数千像素不等,呈现出极高的空间密度与尺寸多样性。这一特性使得DeepScores成为评估和开发针对密集小对象检测与分割算法的理想测试床,尤其在光学音乐识别(OMR)研究中,它模拟了真实乐谱中符号堆叠与上下文依赖的复杂二维结构,为模型处理高密度、小尺寸对象提供了标准化挑战。
衍生相关工作
基于DeepScores数据集,衍生了一系列专注于密集小对象检测与光学音乐识别的经典研究工作。例如,研究者利用该数据集开发了适应高密度小对象的全卷积检测架构,克服了传统YOLO、Faster R-CNN等方法在微小物体集群上的局限。在OMR领域,DeepScores促进了端到端神经网络模型的发展,实现了从乐谱图像到符号序列的直接映射,提升了识别效率与准确率。同时,该数据集也被用于跨领域迁移学习研究,作为预训练源提升模型在医疗影像、卫星图像等其他密集小对象场景的性能,形成了从基础算法创新到跨学科应用拓展的研究脉络。
数据集最近研究
最新研究方向
在光学音乐识别与计算机视觉领域,DeepScores数据集以其高分辨率图像与海量微小对象标注,正推动着微小目标检测与场景理解的前沿研究。当前,该数据集主要聚焦于开发适应高密度、小尺寸对象分布的深度学习模型,以应对传统检测算法如YOLO、Faster R-CNN在密集小对象场景下的性能局限。研究热点包括基于全卷积网络的检测架构优化、上下文感知的符号分类方法,以及跨领域迁移学习应用,如自动驾驶、医学影像分析等。这些探索不仅提升了光学音乐识别的精度,也为通用计算机视觉任务中高分辨率图像处理提供了新的基准与理论支撑,具有重要的学术与工程意义。
相关研究论文
- 1DeepScores -- A Dataset for Segmentation, Detection and Classification of Tiny Objects苏黎世应用科技大学数据实验室与大学 · 2018年
以上内容由遇见数据集搜集并总结生成


