philschmid/flanv2
收藏Hugging Face2023-02-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/philschmid/flanv2
下载链接
链接失效反馈资源简介:
这是Flan V2数据集的一个处理版本。Flan V2数据集包含了Flan 2021、P3、Super-Natural Instructions、Chain-of-thought和Dialog等多种任务的数据实例。数据字段包括Few Shot、Zero Shot、Options Provided in context和No Options Provided等格式,每种任务和格式的组合都保存为JSONL文件,包含输入、目标和任务信息。所有数据都保存为训练集。
This is a processed version of the Flan V2 dataset. The Flan V2 dataset includes data instances from multiple tasks such as Flan 2021, P3, Super-Natural Instructions, Chain-of-Thought, and Dialog. The data fields cover formats including Few Shot, Zero Shot, Options Provided in Context, and No Options Provided. Each combination of task and format is saved as a JSONL file that contains input, target, and task information. All data is stored as the training set.
提供机构:
philschmid
原始信息汇总
数据集概述
数据集名称
- Pretty Name: Flan v2
数据集描述
- 摘要: 这是一个Flan V2数据集的加工版本。数据集由多个任务组成,包括Flan 2021 (flan), P3 (t0), Super-Natural Instructions (niv2), Chain-of-thought (cot), 和 Dialog (dialog)。
- 处理说明: 作者建议尝试不同的任务混合比例以获得最佳的下游效果。当前版本缺少一些数据集,如cs-en WMT翻译任务和q_re_cc对话任务的数据预处理问题。
数据集结构
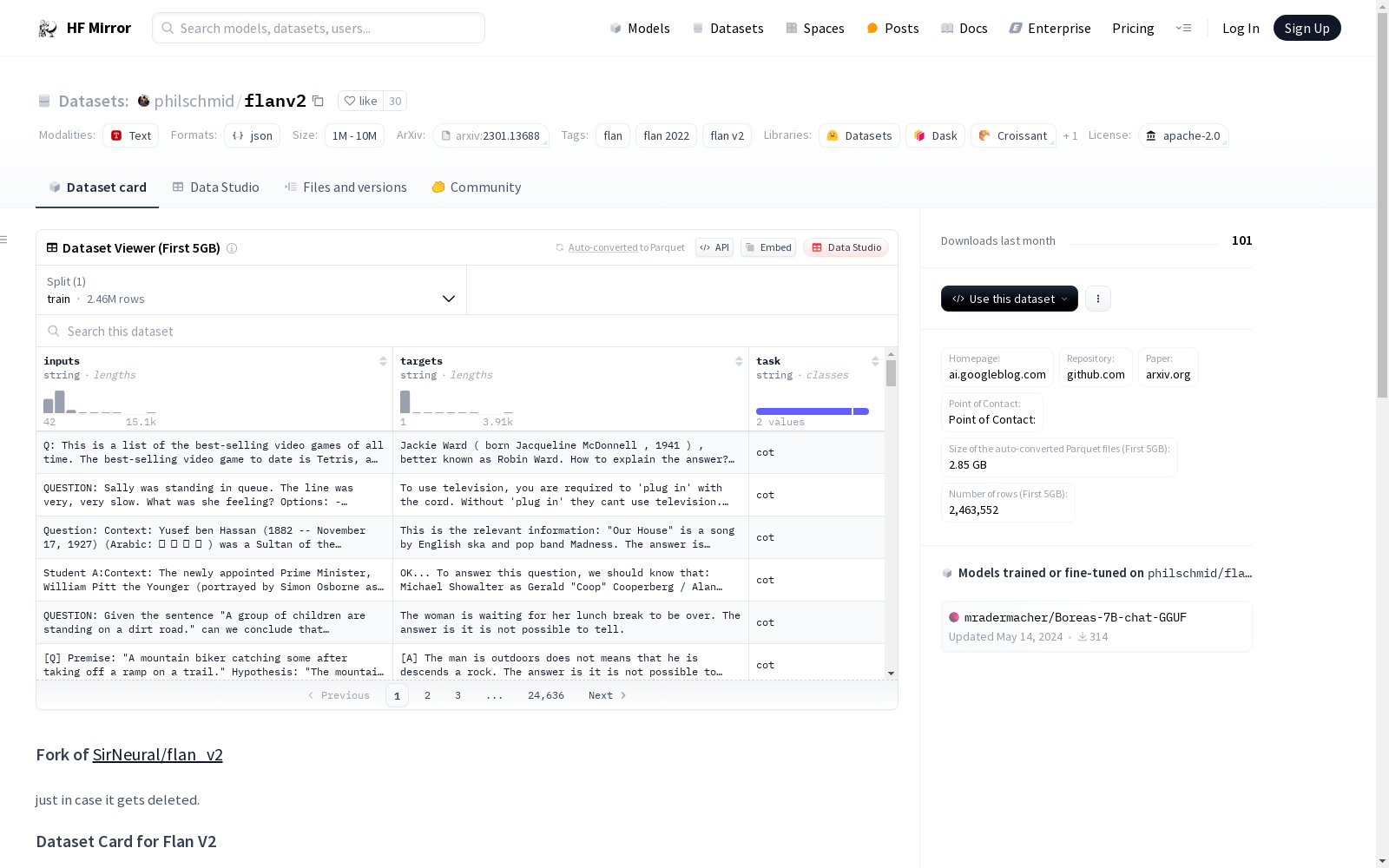
数据实例
- 包含Flan 2021 (flan), P3 (t0), Super-Natural Instructions (niv2), Chain-of-thought (cot), 和 Dialog (dialog)等任务。
数据字段
- 指令数据格式包括:
- Few Shot (fs)
- Zero Shot (zs)
- 上下文中的选项提供(即多项选择,选一个)(opt)
- 无选项提供 (noopt)
- 每个任务+格式的组合以JSONL格式保存,遵循以下模式:
{"input": ..., "target": ..., "task": ...}
数据分割
- 所有数据保存为训练分割。
搜集汇总
数据集介绍
构建方式
Philschmid所构建的Flan V2数据集,是基于原始Flan V2数据集的二次处理版本。该数据集在保留原始数据集结构的基础上,通过筛选和格式化,使其更加易于访问和使用。它涵盖了多种任务类型和格式,包括Few Shot、Zero Shot、带有选项的上下文以及无选项的格式,并以JSONL文件形式存储,每条记录包含输入、目标和任务类型等信息。此数据集在构建过程中,因部分数据集获取权限限制或预处理问题,暂缺少数据集,但整体不影响数据集的使用和研究价值。
使用方法
使用Flan V2数据集时,用户可以直接访问其提供的train split,数据以JSONL格式存储,便于读取和处理。用户可以根据具体的研究需求,选择不同类型和格式的数据样例进行训练。针对数据集中缺失的部分,建议关注数据集维护者的更新,以获取完整版本。此外,数据集的使用者应遵循Apache-2.0开源协议,合理使用和分享数据集成果。
背景与挑战
背景概述
Flan v2数据集,作为Flan Collection的重要组成部分,是在2023年由Google Research团队推出的一种先进的人工智能指令数据集。该数据集的创建旨在推进开放域指令微调技术的发展,通过提供多样化的任务和格式,以实现更好的下游任务表现。Flan v2数据集的发布,不仅丰富了自然语言处理领域的研究资源,也为相关技术的发展提供了强有力的数据支撑,进一步推动了人工智能领域的研究进程。
当前挑战
尽管Flan v2数据集为研究提供了便利,但在构建和应用过程中也面临一些挑战。首先,数据集在构建过程中遇到了部分数据集的手动下载和预处理问题,如cs-en WMT翻译任务和q_re_cc对话任务的数据预处理。其次,数据集在应用中的挑战在于如何根据不同的任务调整指令微调的比例,以获得最优的下游任务表现。此外,当前版本的数据集并非完整版,缺少部分数据,这限制了其研究潜力的完全发挥,亟待后续版本的完善。
常用场景
经典使用场景
在自然语言处理领域,Flan V2数据集以其丰富的任务类型和格式成为研究者的首选。该数据集支持少样本学习、零样本学习以及提供或不提供选项的上下文学习,使得研究者在探索不同学习策略时得以在该数据集上获得最佳的下游任务结果。
解决学术问题
Flan V2数据集解决了自然语言处理中跨任务学习的难题,为研究者提供了一个统一的框架,以探究不同混合比例的任务对模型性能的影响。其研究成果有助于推动开放域语言模型的进步,对学术领域产生了深远的影响。
实际应用
实际应用中,Flan V2数据集被广泛用于提升机器翻译、对话系统以及生成式文本模型的性能。通过实验不同的任务混合比例,开发者能够优化模型,使其在特定应用中表现更为出色,从而提高用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,Flan v2数据集以其创新的指令微调技术受到广泛关注。研究者们正致力于探索该数据集在不同任务混合比例下的性能优化,以期在下游任务中取得最佳效果。Flan v2的推出,不仅丰富了语言模型训练的资源,也为开放域指令微调技术提供了新的研究方向,对推动自然语言理解的进步具有重要意义。
以上内容由遇见数据集搜集并总结生成


