OpenDCAI/FlipVQA
收藏Hugging Face2026-04-04 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/OpenDCAI/FlipVQA
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
configs:
- config_name: Multimodal
data_files:
- split: train
path: Multimodal/train-*
- split: test
path: Multimodal/test-*
- config_name: Text_base
data_files:
- split: train
path: Text_base/train-*
task_categories:
- question-answering
language:
- zh
- en
size_categories:
- 10K<n<100K
dataset_info:
config_name: Text_base
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: solution
dtype: string
- name: type
dtype: string
- name: subject
dtype: string
- name: images
dtype: 'null'
- name: generated_cot
dtype: string
- name: answer_match_result
dtype: bool
splits:
- name: train
num_bytes: 662976117
num_examples: 72126
download_size: 289871745
dataset_size: 662976117
---
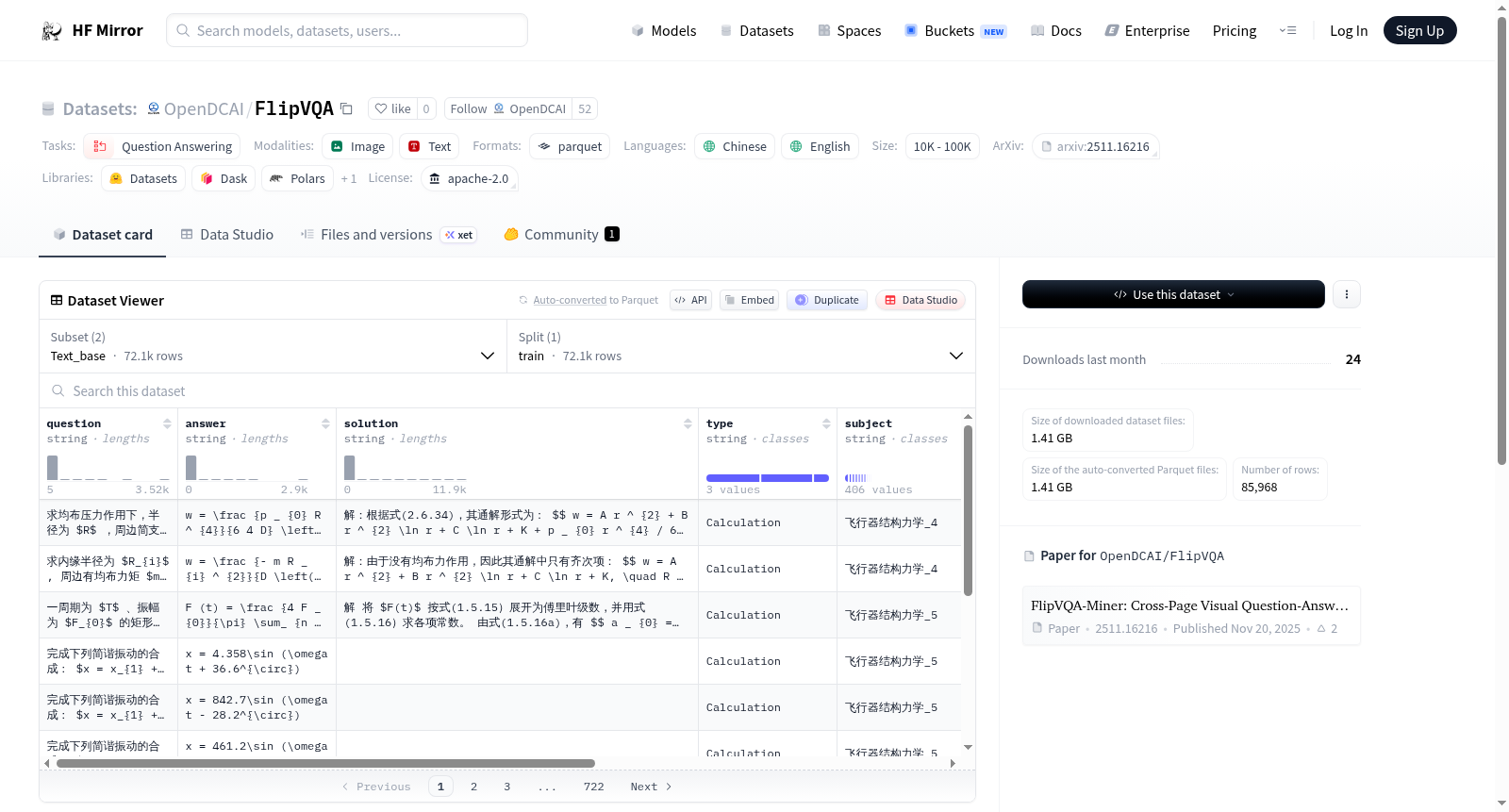
# FlipVQA-85K
FlipVQA-85k is a high-fidelity reasoning benchmark curated from a corpus of 544 college-level educational PDF documents, including expert-authored textbooks and exercise sets.
The collection spans 11 academic disciplines, primarily in STEM domains where problems typically involve rigorous and verifiable reasoning processes.
Paper link: https://huggingface.co/papers/2511.16216
Please see https://github.com/OpenDCAI/DataFlow-VQA for detailed data curation method.
**Important**:
- The `solution` is extracted from the original textbooks, and might not be suitable to directly used for LLM training.
- The `generated_cot` consists of detailed thinking processes generated by Qwen3-235B-A22B-Thinking and Qwen3-VL-235B-A22B-Thinking, which have proven effective for LLM training.
We retain **both** correct and incorrect thinking processes in the dataset, with the `answer_match_result` key indicating whether the thinking process yielded a correct answer.
提供机构:
OpenDCAI
搜集汇总
数据集介绍
构建方式
FlipVQA-85K数据集源自544份大学教育PDF文档的精心筛选,涵盖专家编写的教材与习题集。该数据集构建过程严格遵循学科逻辑,从原始文档中提取问题与标准答案,并利用先进的大语言模型生成详细的思维链推理过程。构建中特别保留了正确与错误的推理路径,通过答案匹配结果字段进行标识,确保了数据在训练中的多样性与真实性。
使用方法
研究人员可将该数据集用于视觉问答与文本推理模型的训练与评估。使用时应区分原始标准答案与模型生成的思维链,后者更适合直接用于大语言模型的指令微调或思维链蒸馏。通过答案匹配结果字段,可构建对比学习或错误分析任务,以增强模型对推理路径的判别与生成能力。数据集支持多模态与纯文本两种配置,可根据研究需求灵活选用。
背景与挑战
背景概述
FlipVQA数据集由OpenDCAI研究团队于2024年构建,旨在应对多模态推理领域中对高质量、可验证推理过程的需求。该数据集从544份大学教育PDF文档中精心筛选,涵盖数学、物理等11个STEM学科,核心研究问题聚焦于如何通过视觉问答形式评估和提升大型语言模型在复杂学术问题上的逻辑推理能力。其构建基于严谨的学科知识体系,为多模态理解与推理研究提供了坚实的基准,显著推动了教育智能化与模型可解释性方向的发展。
当前挑战
FlipVQA数据集致力于解决多模态视觉问答中复杂推理过程的建模挑战,特别是针对STEM领域需要严格逻辑推导的问题。在构建过程中,团队面临从非结构化PDF中准确提取问题、答案及解析内容的困难,同时需确保跨学科知识的一致性与权威性。此外,生成可靠且多样化的思维链数据亦是一大难点,数据集通过保留正确与错误的推理路径,为模型训练提供了丰富的监督信号,但这也对数据质量控制提出了更高要求。
常用场景
经典使用场景
在视觉问答与多模态推理领域,FlipVQA数据集常被用于评估和训练模型在复杂学术场景下的理解能力。该数据集源自大学级别的教材与习题集,覆盖STEM等11个学科,其问题通常涉及严谨的逻辑推导与验证过程。研究者利用其中的图文结合内容,测试模型是否能够准确解析问题、结合视觉信息进行推理,并生成符合学术规范的答案。这一场景不仅检验了模型的多模态融合性能,也推动了教育智能化中自动解题系统的发展。
解决学术问题
FlipVQA数据集主要解决了多模态推理中模型缺乏高质量、可验证的学术基准的问题。传统视觉问答数据集往往侧重于日常场景,难以支撑深层次的科学推理研究。该数据集通过提供来自权威教材的精确解答与生成的思维链,使研究者能够深入探究模型在复杂学科问题上的推理能力、错误分析及知识整合机制。其意义在于为学术界提供了一个可靠的标准,促进了多模态大模型在科学教育、自动评估等方向的理论突破与应用验证。
实际应用
在实际应用中,FlipVQA数据集被广泛用于智能教育辅助系统的开发。例如,它可以支撑在线学习平台构建自动答疑引擎,帮助学生理解STEM领域的难题;同时,也为教材内容数字化、习题自动生成与批改提供了数据基础。在科研中,该数据集助力企业与机构训练更精准的多模态模型,应用于学术搜索、知识图谱构建等场景,提升了人工智能在专业领域的信息处理与决策支持能力。
数据集最近研究
最新研究方向
在视觉问答领域,FlipVQA数据集凭借其从大学教育PDF文档中提取的高保真推理问题,正推动多模态大模型在复杂STEM学科中的深度推理能力研究。该数据集涵盖11个学术领域,其独特之处在于同时提供专家撰写的标准答案与由先进模型生成的思维链,包括正确与错误的推理过程,这为探索模型的可解释性、错误分析与自我纠正机制提供了丰富素材。当前研究热点聚焦于利用此类高质量数据训练模型执行步骤化、可验证的推理,以应对科学教育、自动化解题等实际场景中的挑战,提升模型在专业领域的可靠性与泛化能力。
以上内容由遇见数据集搜集并总结生成


