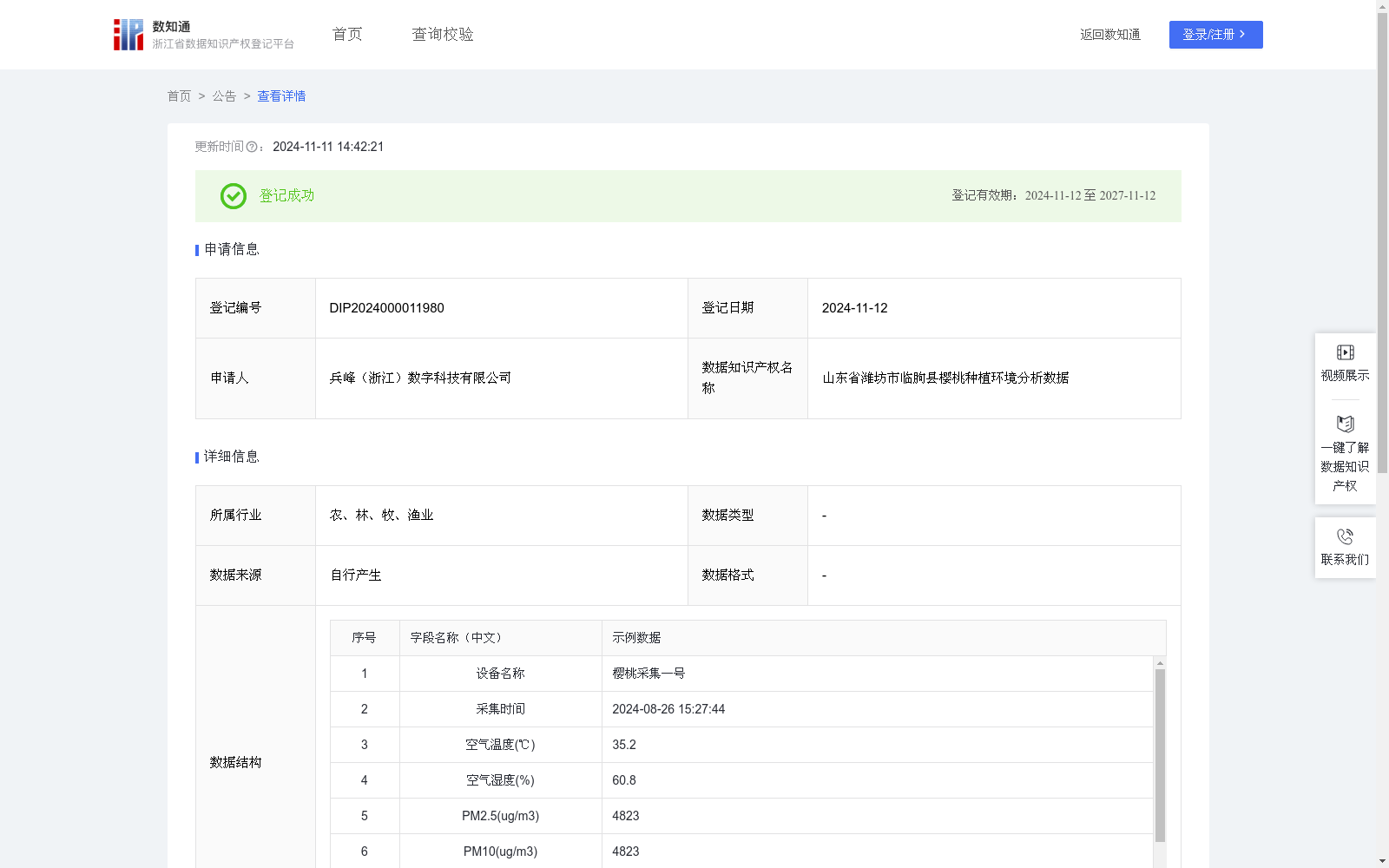
山东省潍坊市临朐县樱桃种植环境分析数据
收藏浙江省数据知识产权登记平台2024-11-11 更新2024-11-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/83072
下载链接
链接失效反馈官方服务:
资源简介:
采集樱桃种植的空气温湿度、光照强度、PM10、PM2.5 等数据,全面评估不同环境条件对樱桃生长的具体影响。准确确定适宜的空气温湿度区间,以促进樱桃果实的顺利发育和成熟,避免果实开裂或萎缩。明确合适的光照强度和时长,确保樱桃进行高效的光合作用,使果实色泽鲜艳、甜度增加。分析不同水平的 PM10 和 PM2.5 对樱桃树叶和果实的潜在损害,防止空气污染影响樱桃的品质和产量。进而为樱桃的健康生长提供坚实保障。利用这些数据构建樱桃品质与环境参数关联的深度网络模型,深入探索何种环境条件组合可以使樱桃具有更大的果实尺寸、更高的甜度、更优的口感和更好的耐储运性等,为显著提升樱桃品质奠定基础。基于数据驱动的方式,为樱桃种植环境的智能调控提供有效的支持。依据实时数据自动调整灌溉策略、通风设置以及防护措施等,为樱桃创造适宜的生长环境,提高种植效率和产量。将优化后的环境调控经验推广应用至不同地区的樱桃种植中,形成多维度细粒度的感知与控制模式,有力推动樱桃种植产业朝着科学、高效、模式可移植的方向发展,全面提升整个樱桃产业的竞争力。1.数据采集:本系统通过空气湿温度传感器、光照传感器、PM传感器等物联网设备,结合4G/5G、Wi-Fi与有线网络,实时采集种植环境中的空气湿温度、光照、PM10、PM2.5等多维数据。
2.算法规则:系统采用环境参数评分算法,对环境数据进行评分。基于作物生长理想条件(如温度、湿度、光照、PM值等),并通过以下公式计算:环境参数评分=100-Σ(w_i×|当前值_i-理想值_i|/容差_i)其中,Σ表示对所有参数的累加,w_i是第i个参数的权重。当前值_i是第i个参数的实际测量值,理想值_i是第i个参数的理想值。容差_i是第i个参数的允许波动范围。权重、理想值和容差范围设定基于历史数据分析以及实际种植经验的确定。对作物生长影响较大的参数获得较高的权重。容差范围则考虑到环境因素的波动性,针对作物对不同环境变化的耐受性设定进行适当设定,环境参数偏离理想值越多,扣分越大,以空气温度为例,其权重为0.45,理想值设定为25℃,容差范围为±4℃,扣分计算如下:空气温度扣分=0.45×|35.2-25|/4=0.45×2.55=11.475。根据这些评分生成具体的环境优化方案。
Collect multi-dimensional data including air temperature and humidity, light intensity, PM10, PM2.5, etc. from cherry orchards, to comprehensively evaluate the specific impacts of different environmental conditions on cherry growth. Accurately determine the optimal air temperature and humidity ranges to facilitate the smooth development and ripening of cherry fruits, and prevent fruit cracking or shriveling. Clarify appropriate light intensity and duration to ensure efficient photosynthesis in cherry trees, thereby enhancing fruit coloration and sugar content. Analyze the potential damage of different PM10 and PM2.5 levels to cherry leaves and fruits, so as to prevent air pollution from impairing cherry quality and yield. These efforts will provide a solid guarantee for the healthy growth of cherries.
Using the collected data, a deep network model correlating cherry quality and environmental parameters will be constructed to deeply explore which environmental condition combinations can yield cherries with larger fruit size, higher sugar content, better taste, and improved storability and transportability, laying a foundation for significantly improving cherry quality. This data-driven approach will provide effective support for intelligent regulation of cherry planting environments. By automatically adjusting irrigation strategies, ventilation settings, and protective measures based on real-time data, suitable growing environments for cherries can be created, thereby improving planting efficiency and yield. The optimized environmental regulation experience will be promoted and applied to cherry planting in different regions, forming a multi-dimensional and fine-grained perception and control model, which will effectively promote the development of the cherry planting industry towards scientific, efficient, and transplantable models, and comprehensively enhance the competitiveness of the entire cherry industry.
1. Data Collection: This system collects real-time multi-dimensional environmental data from cherry orchards, including air temperature and humidity, light, PM10, PM2.5, etc., via IoT devices such as air temperature and humidity sensors, light sensors, and PM sensors, combined with 4G/5G, Wi-Fi and wired networks.
2. Algorithm Rules: The system adopts an environmental parameter scoring algorithm to evaluate environmental data. Based on the ideal growth conditions of crops (such as temperature, humidity, light, PM values, etc.), the scoring is calculated using the following formula:
Environmental Parameter Score = 100 - Σ(w_i × |Current Value_i - Ideal Value_i| / Tolerance_i)
Where Σ represents the summation over all parameters, w_i is the weight of the i-th parameter, Current Value_i is the actual measured value of the i-th parameter, Ideal Value_i is the ideal value of the i-th parameter, and Tolerance_i is the allowable fluctuation range of the i-th parameter. The weights, ideal values and tolerance ranges are determined based on historical data analysis and actual planting experience. Parameters with greater impacts on crop growth are assigned higher weights. The tolerance ranges are appropriately set considering the volatility of environmental factors and the crop's tolerance to different environmental changes. The greater the deviation of an environmental parameter from its ideal value, the larger the score deduction. Taking air temperature as an example, its weight is 0.45, the ideal value is set to 25℃, and the tolerance range is ±4℃. The score deduction for air temperature is calculated as:
Air Temperature Score Deduction = 0.45 × |35.2 - 25| / 4 = 0.45 × 2.55 = 11.475.
Specific environmental optimization schemes are generated based on these scores.
提供机构:
兵峰(浙江)数字科技有限公司
创建时间:
2024-10-18
搜集汇总
数据集介绍
特点
该数据集包含山东省潍坊市临朐县樱桃种植环境的801条数据,每日更新,涵盖空气温湿度、光照、PM值等多维参数,并采用环境参数评分算法生成调控方案,旨在优化樱桃种植环境并提升果实品质。
以上内容由遇见数据集搜集并总结生成


