LiveRAG Benchmark
收藏arXiv2025-11-18 更新2025-11-20 收录
下载链接:
https://huggingface.co/datasets/LiveRAG/Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
LiveRAG基准数据集由技术创新研究所研发,专为评估检索增强生成系统而设计的高质量问答语料库。该数据集包含895个合成问答对,源自SIGIR 2025 LiveRAG挑战赛,数据源采用FineWeb-10BT网络文档库,并利用DataMorgana工具通过多阶段流程生成,涵盖事实型、比较型等八类问题范畴。本数据集核心应用于RAG系统效能评估,通过集成难度系数与区分度参数,为人工智能问答系统的性能校准与渐进式训练提供标准化测评框架。
The LiveRAG benchmark dataset, developed by the Institute of Technological Innovation, is a high-quality question-answering (QA) corpus specifically designed for evaluating retrieval-augmented generation (RAG) systems. Comprising 895 synthetic QA pairs, this dataset originates from the SIGIR 2025 LiveRAG Challenge. Its data source is the FineWeb-10BT web document corpus, and it was generated via a multi-stage pipeline using the DataMorgana tool, covering eight categories of question types including factual and comparative questions. The core application of this dataset is to evaluate the effectiveness of RAG systems. By integrating difficulty coefficient and discriminability parameters, it provides a standardized evaluation framework for performance calibration and incremental training of AI-powered question-answering systems.
提供机构:
技术创新研究所
创建时间:
2025-11-18
原始信息汇总
LiveRAG2025 Benchmark 数据集概述
数据集基本信息
- 许可证: odc-by
- 任务类别: 问答系统
- 语言: 英语
- 标签: LiveRAG, DataMorgana
- 数据集名称: LiveRAG2025 Benchmark
- 规模类别: n<1K
数据集描述
LiveRAG基准测试包含895个问题:
- 第一阶段包含500个问题,第二阶段包含500个问题
- 两个阶段共享105个问题
- 总计895个唯一问题
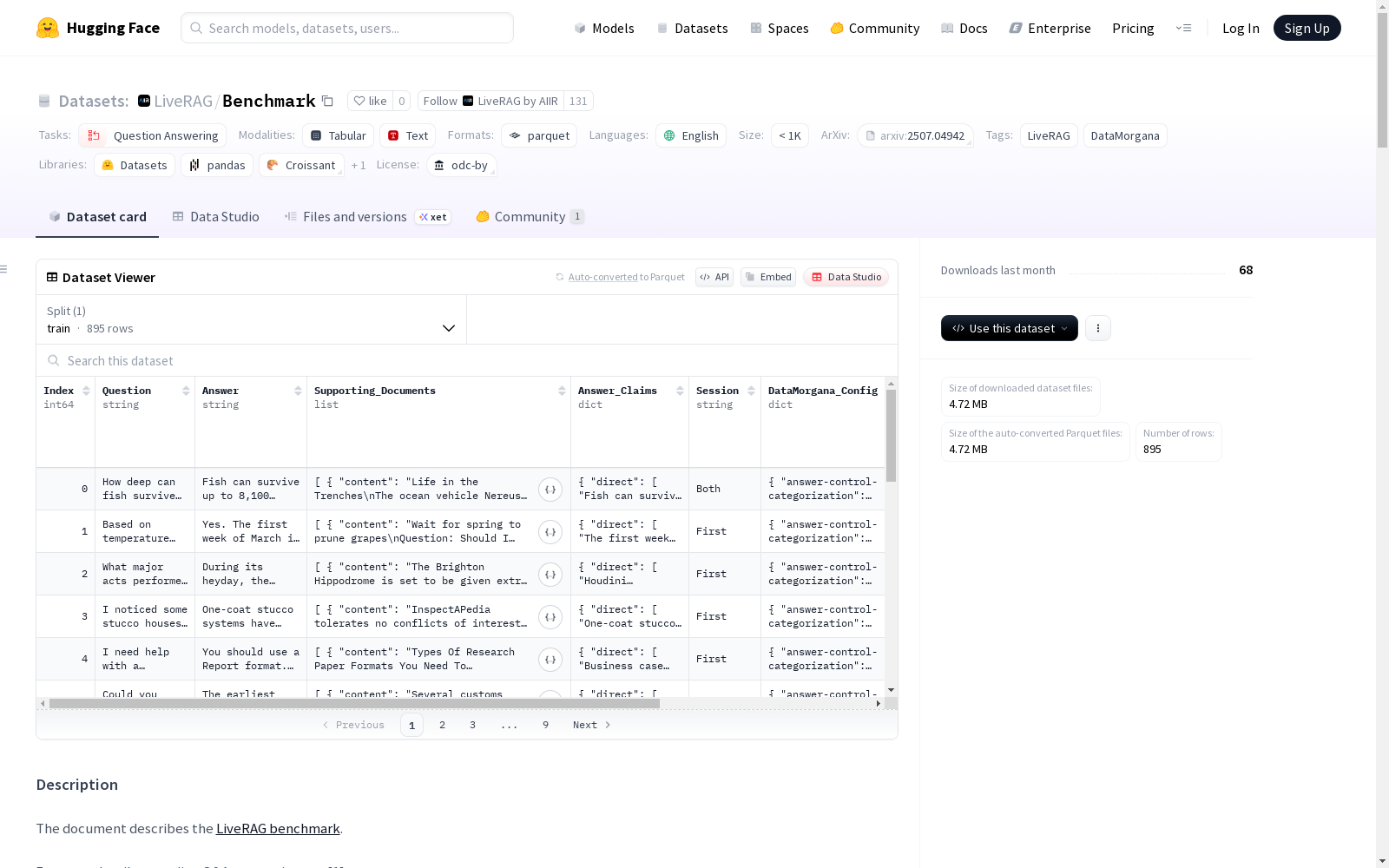
基准字段说明
核心字段
| 字段名称 | 描述 | 类型 | 备注 |
|---|---|---|---|
Index |
基准索引 | int64 [0,1,...,894] | |
Question |
DataMorgana生成的问题 | String | |
Answer |
DataMorgana真实答案 | String | |
Supporting_Documents |
支持文档列表 | List of comma separated JSON objects | 使用FineWeb-10BT文档 |
Answer_Claims |
答案声明分类 | JSON object | 包含direct、useful、useless三类 |
Session |
问题出现阶段 | String | 取值:"First"、"Second"、"Both" |
评估指标字段
| 字段名称 | 描述 | 类型 | 备注 |
|---|---|---|---|
DataMorgana_Config |
问题和用户分类配置 | JSON object | |
ACS |
平均正确率得分 | float64 [-1:2] | 得分越低表示问题越难 |
ACS_std |
ACS标准差 | float64 [0:1.5] | |
IRT-diff |
IRT模型难度参数 | float64 [-6.0:6.0] | |
IRT-disc |
IRT-2PL模型区分度参数 | float64 [-0.6:1.4] |
数据结构定义
文档JSON结构
json { "content": "文档完整文本内容", "doc_id": "文档唯一标识符" }
声明JSON结构
json { "direct": ["直接回答问题的声明"], "useful": ["提供有用上下文或支持信息的声明"], "useless": ["对回答问题无用的声明"] }
分类JSON结构
包含8个必需分类字段:
- 答案控制分类
- 答案类型分类
- 表述分类
- 语言正确性分类
- 语言变异分类
- 礼貌程度分类
- 前提分类
- 用户分类
参考文献
D. Carmel等人,"SIGIR 2025 - LiveRAG Challenge Report",arXiv,2025
搜集汇总
数据集介绍
构建方式
在检索增强生成技术日益成为生成式人工智能解决方案核心组件的背景下,LiveRAG Benchmark通过DataMorgana合成数据生成工具构建而成。该工具采用主题驱动的文档采样流程,从FineWeb-10BT语料库中筛选具有事实性、趣味性和可信度的文档,并通过多维度分类体系随机组合生成问题。每个问题基于单文档或双文档生成,其中双文档问题通过互补文档检索机制确保信息完整性,最终形成包含895个问答对的标准化数据集。
特点
该数据集显著特点在于其多维度的难度分布与丰富的语言学特征。通过项目反应理论模型量化每个问题的难度值与区分度参数,使得问题难度呈现连续谱系分布。数据集涵盖事实型、比较型、多维度等八类问题范畴,并融合了不同语言风格、礼貌程度及用户画像特征。语言学分析表明,该数据集在词汇多样性和句法复杂性上超越传统问答基准,其语义嵌入的异质性评分进一步验证了问题内容的广泛覆盖性。
使用方法
作为评估检索增强生成系统的基准工具,该数据集支持多层次性能验证流程。研究者可通过提供的标准答案与支撑文档进行检索精度检验,利用答案主张分类体系实施生成质量评估。难度参数支持课程学习策略,允许按难度梯度训练系统。数据集配套的会话标识与正确率统计支持横向性能对比,而IRT参数则为系统能力差异化分析提供理论依据,助力构建更稳健的问答系统。
背景与挑战
背景概述
随着检索增强生成技术在生成式人工智能领域的广泛应用,系统化评估其效能的需求日益凸显。LiveRAG基准数据集由以色列技术创新研究院团队于2025年主导创建,源自SIGIR'2025 LiveRAG挑战赛的竞赛数据,包含895组通过DataMorgana工具生成的合成问答对。该数据集通过项目反应理论模型量化每个问题的难度与区分度参数,为RAG系统的性能评估提供了标准化度量框架,显著推进了开放领域问答系统的可解释性研究进程。
当前挑战
在解决领域问题层面,该数据集需应对多文档推理问题的复杂性,例如比较型与多维度问题要求系统具备跨文档信息整合能力;同时需克服语义变异带来的理解障碍,包括术语转换与语言错误对模型理解的干扰。在构建过程中,数据生成面临文档质量控制的挑战,需通过多级过滤机制确保源文档的事实性、可信度与时效性;此外,合成问答与真实用户需求的表征差异,以及基于特定模型架构的IRT参数泛化性,均为基准效度的潜在制约因素。
常用场景
经典使用场景
在检索增强生成技术评估领域,LiveRAG Benchmark作为标准化测试集,通过895个合成问答对系统评估RAG模型的综合能力。该数据集通过DataMorgana工具构建,涵盖事实型查询、比较分析、多维度问题等八种分类,其题目难度分布广泛,从简单事实检索到需要跨文档推理的复杂问题,为模型性能对比提供了统一尺度。
实际应用
在实际工业场景中,该数据集被广泛应用于智能客服、知识库问答等系统的性能调优。企业可依据题目难度分层进行渐进式测试,针对高难度问题优化检索策略与生成逻辑。其提供的会话场景标注与用户角色设定,尤其适用于个性化问答系统的现实需求验证。
衍生相关工作
基于该数据集衍生的经典研究包括SIGIR 2025 LiveRAG挑战赛的参赛系统对比分析,以及多项针对多文档推理机制的改进模型。后续工作通过结合题目难度参数开发课程学习策略,并利用其语言多样性特征开展跨领域泛化研究,持续推动RAG技术在前沿学术与工业应用中的创新发展。
以上内容由遇见数据集搜集并总结生成


