IAM 50个最常见的作家手写数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-26394.html
下载链接
链接失效反馈官方服务:
资源简介:
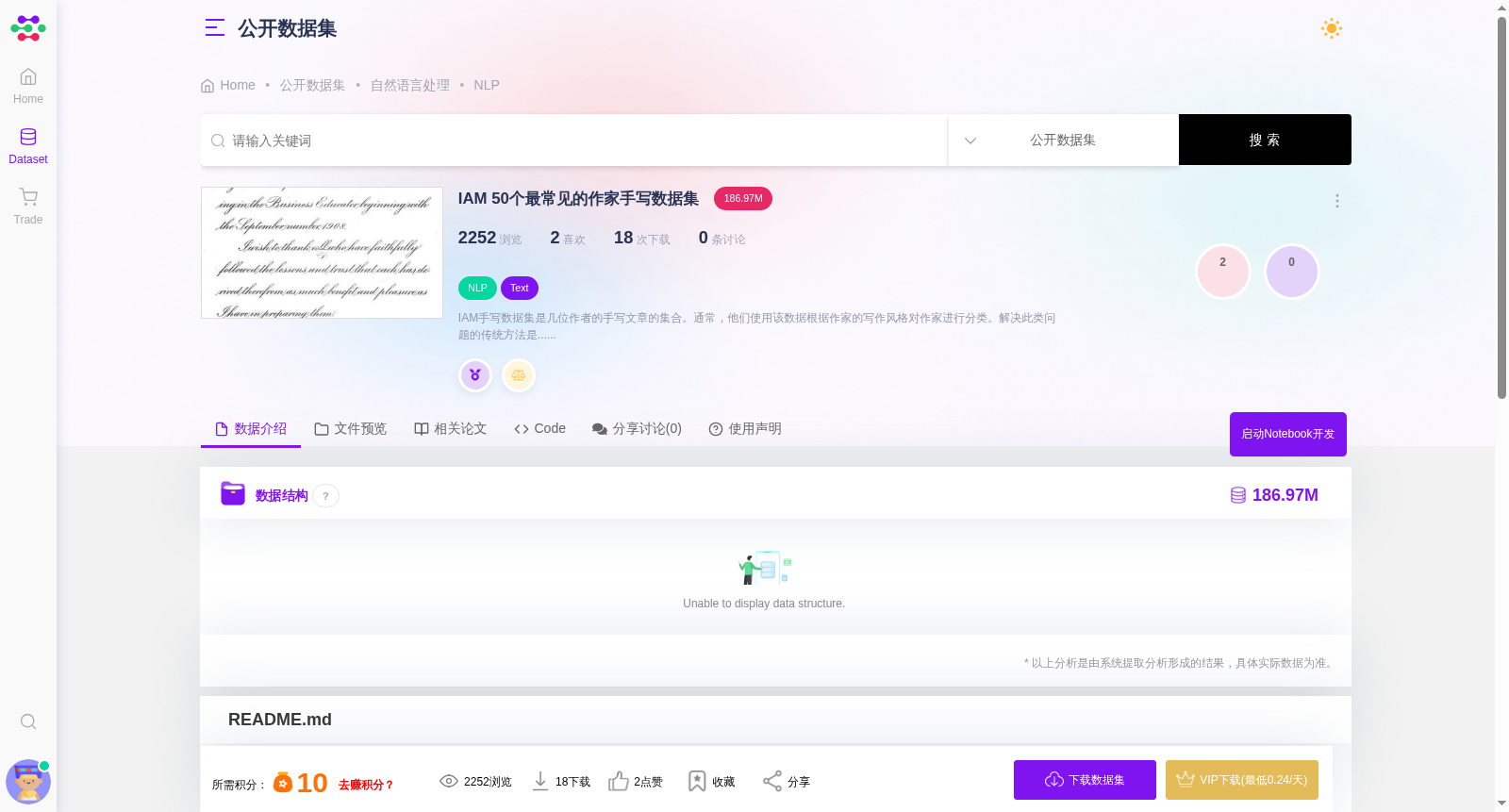
IAM手写数据集是几位作者的手写文章的集合。通常,他们使用该数据根据作家的写作风格对作家进行分类。解决此类问题的传统方法是提取特征(例如字母,曲率等之间的间距)并将其输入支持向量机。但是,我想通过使用Keras和Tensorflow进行深度学习来解决此问题。为此,我们不需要完整的IAM手写数据集,但可以使用一些可靠的子集来进行训练,例如对数据集贡献最大的前50名人员的图像子集。 该数据集包含每个手写句子的图像,并使用短划线分隔的文件名格式。第一个字段代表测试代码,第二个字段代表作者ID,第三个字段ID,第四个字段代表句子ID。
The IAM Handwriting Dataset is a collection of handwritten articles from multiple authors. Typically, researchers use this dataset to classify authors based on their unique writing styles. Traditional approaches to solve such tasks extract handcrafted features (e.g., spacing between letters, curvature, etc.) and feed them into Support Vector Machines (SVMs). However, this study aims to solve this problem using deep learning with Keras and TensorFlow. For this training purpose, the full IAM Handwriting Dataset is unnecessary. Instead, a reliable subset can be employed for training, such as the image subset consisting of the top 50 contributors with the most samples to the dataset. This dataset contains images of each handwritten sentence, with filenames following a hyphen-separated format. The first field represents the test code, the second denotes the author ID, the third is the ID, and the fourth represents the sentence ID.
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
IAM 50个最常见的作家手写数据集是IAM手写数据集的子集,包含前50名贡献最大的作者的手写句子图像,用于根据写作风格进行作家分类。该数据集适用于传统机器学习方法(如特征提取和支持向量机)以及深度学习方法(如使用Keras和TensorFlow),图像文件名以短划线分隔,包括测试代码、作者ID、ID和句子ID等字段。
以上内容由遇见数据集搜集并总结生成


