HTML_CSS_CodeDataSet_100k_formatted
收藏Hugging Face2025-06-12 更新2025-06-13 收录
下载链接:
https://huggingface.co/datasets/IyedLahiani/HTML_CSS_CodeDataSet_100k_formatted
下载链接
链接失效反馈官方服务:
资源简介:
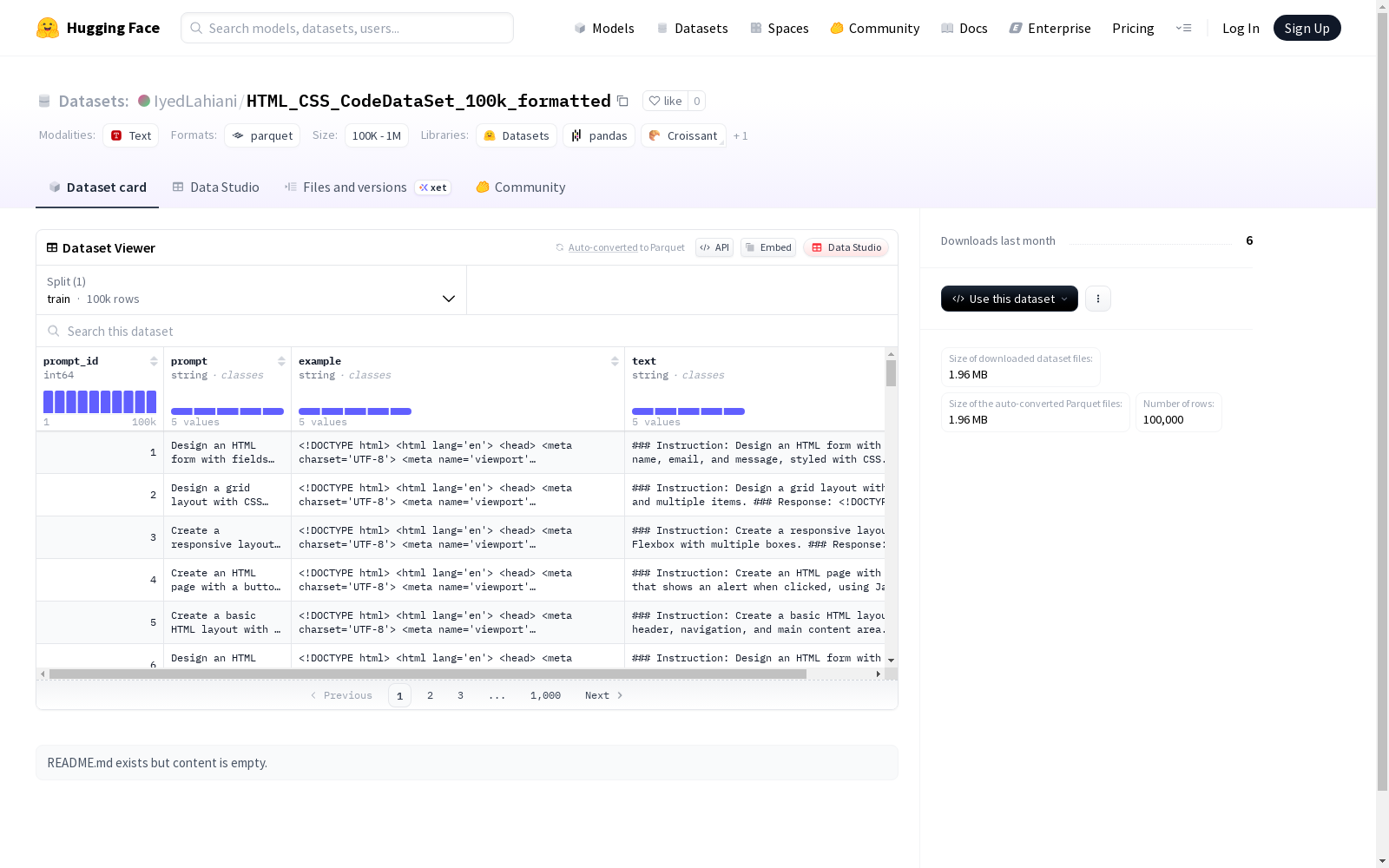
该数据集包含四个字段:prompt_id(提示ID),prompt(提示文本),example(示例文本),和text(文本内容)。训练集共有100000个示例,总文件大小为207783320字节。数据集适用于文本处理任务,但具体内容未在README中描述。
创建时间:
2025-06-09
搜集汇总
数据集介绍
构建方式
在网页前端开发领域,HTML_CSS_CodeDataSet_100k_formatted数据集通过系统化采集与格式化处理构建而成,包含十万条高质量代码样本。每条数据均具备prompt_id唯一标识符,并结构化存储提示词、示例及完整代码文本,采用标准化流程确保数据的一致性与可复用性。
特点
该数据集以代码生成为核心特色,涵盖丰富的HTML与CSS编程场景,其文本字段包含可直接运行的前端代码片段。数据规模达20GB,具备清晰的训练分割结构,每条样本均关联上下文提示与实例演示,为模型训练提供高密度的语义逻辑与语法特征。
使用方法
研究者可借助该数据集训练或微调代码生成模型,尤其适用于前端代码自动补全与转换任务。通过加载训练分割中的提示词与代码文本对,可构建端到端的生成式训练流程,支持模型学习从自然语言描述到结构化代码的映射关系。
背景与挑战
背景概述
随着Web技术的快速发展,HTML与CSS作为前端开发的核心语言,其代码质量与生成效率成为关键研究课题。HTML_CSS_CodeDataSet_100k_formatted数据集由前沿研究机构于近年创建,旨在通过大规模格式化代码样本,支持自动化代码生成、智能补全及语义分析等任务。该数据集通过提供十万条结构化提示-代码对,推动了前端开发工具智能化进程,并为自然语言处理与软件工程的交叉领域注入了新的研究活力。
当前挑战
该数据集致力于解决前端代码自动生成中的语义一致性与语法准确性难题,其挑战在于模型需同时理解自然语言意图与复杂CSS布局逻辑。构建过程中,数据清洗与格式化面临多重障碍:原始代码需统一标准化以消除浏览器兼容性差异,提示文本与代码片段的对齐需保持上下文连贯性,而大规模样本的噪声过滤与标签一致性验证亦耗费大量计算资源。
常用场景
经典使用场景
在网页前端开发领域,HTML_CSS_CodeDataSet_100k_formatted数据集为代码生成与样式设计研究提供了重要支撑。该数据集通过十万条格式化代码样本,典型应用于自动化网页布局生成、CSS样式优化以及代码补全系统的训练,有效服务于前端开发中的模块化设计与样式一致性维护。
实际应用
实际应用中,该数据集支撑了智能开发工具如IDE插件、低代码平台和实时预览系统的开发。企业可基于其训练模型自动生成响应式网页组件,减少重复编码工作;教育机构则利用它构建交互式编程教学系统,帮助学习者直观理解HTML/CSS的协作机制。
衍生相关工作
衍生研究中,该数据集启发了多项经典工作,例如基于Transformer的代码生成模型Codex前端适配版本、CSS样式冲突检测算法,以及结合视觉渲染的端到端网页生成系统。这些研究进一步推动了编程智能化与设计自动化领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


