Qwen3-Reasoning-Distill-Q-A-Dataset
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/RefinedNeuro/Qwen3-Reasoning-Distill-Q-A-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
Qwen3推理精炼土耳其问答数据集,包含六个STEM领域的问答对,为土耳其语推理任务设计,适用于六年级到十二年级的学生。数据集由qwen3-32b模型生成,用于微调RefinedNeuro土耳其推理v2模型。
创建时间:
2025-05-11
原始信息汇总
Qwen3 Reasoning Distill Q&A Dataset 概述
基本信息
- 许可证: CC0 1.0 Universal (CC0 1.0) Public Domain Dedication
- 语言: 土耳其语 (tr), 英语 (en)
- 数据集名称: Qwen3 Reasoning Distilled Turkish Question Answer Dataset
- 大小分类: 10K<n<100K
- 标签: biology, chemistry, math, synthetic, geometry, statistics, trigonometry
- 任务分类: question-answering, text-generation
作者
- Mehmet Can Farsak
- Serhat Atayeter
数据集摘要
该数据集包含六个STEM学科的问答对,专为土耳其语推理任务设计。使用qwen3-32b模型生成,旨在用于微调RN_TR_R2(RefinedNeuro Turkish Reasoning v2)模型。
- 学科: Matematik, Fizik, Kimya, Biyoloji, Geometri, Trigonometri, İstatistik
- 年级: 6年级至12年级
- 变体(后缀提示):
- 问题应详细且长,答案仅为数字。
- 问题应简短且精确,答案仅为数字。
- 问题应长但简单,答案仅为数字。
- 问题应简短且简单,答案仅为数字。
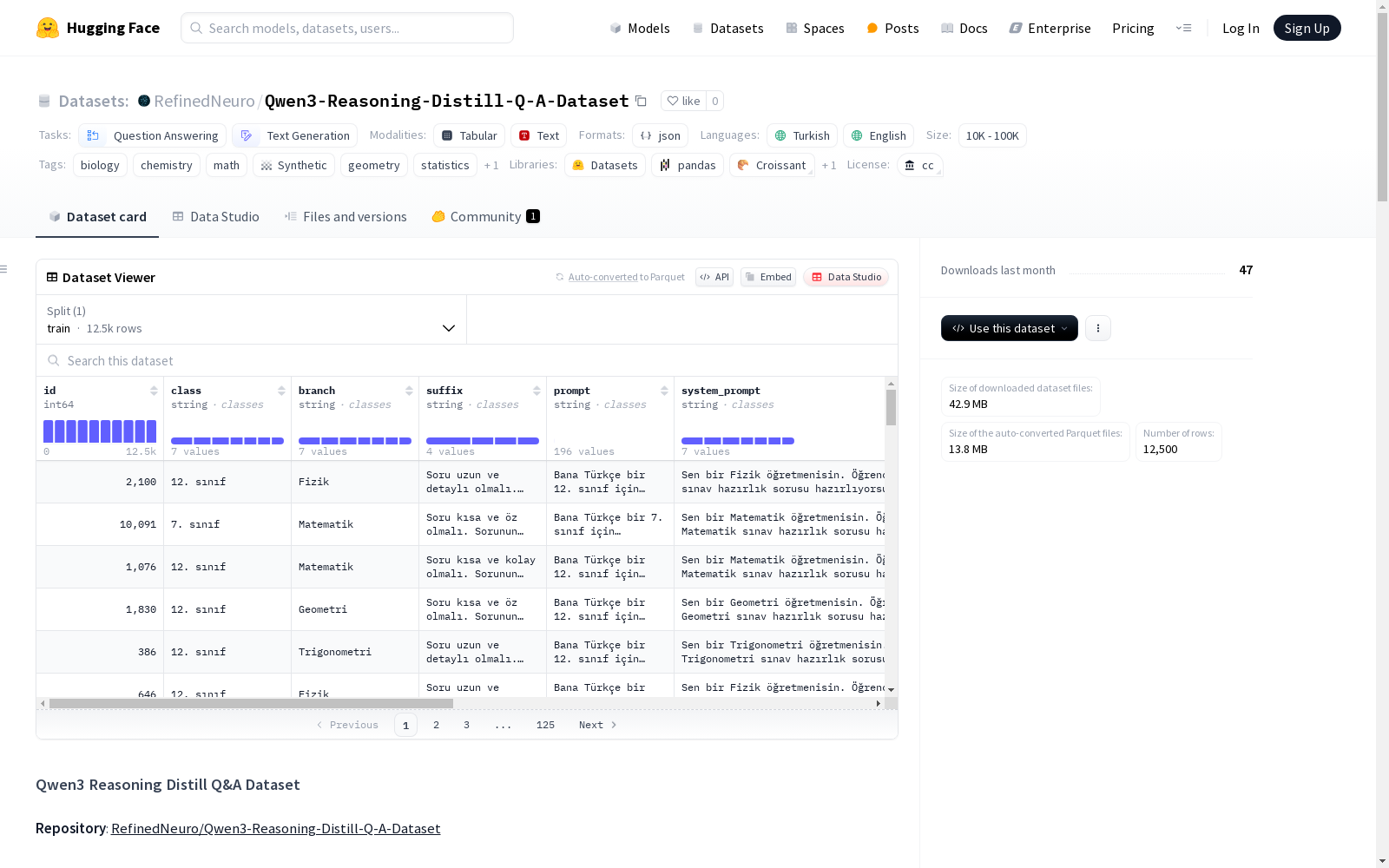
数据集统计
| 学科 | 示例数量 |
|---|---|
| Matematik | 2,500 |
| Fizik | 2,000 |
| Kimya | 1,500 |
| Biyoloji | 1,500 |
| Geometri | 2,000 |
| Trigonometri | 1,500 |
| İstatistik | 1,500 |
总示例数: 12,500
注意: 数据集以单个JSONL文件提供,无预定义分割(训练/验证/测试)。
数据字段
JSONL文件中的每一行包含以下字段:
class: 年级(如"6th grade", "12th grade")branch: 学科(如"Matematik", "Fizik")suffix: 变体提示标识或文本prompt: 提供给qwen3-32b的原始生成提示system_prompt: 系统级提示上下文(如有)generated_question: 生成的问题文本generated_answer: 数字答案generated_answer_unit: 答案单位(如适用;否则为空)generated_question_thinking_part: 模型的链式思考或推理笔记(如有)
生成过程
所有示例均使用qwen3-32b模型生成。提示模板和系统提示包含在数据集中。除基本JSONL格式化和去重外,未应用其他后处理。
预期用途
- 微调土耳其语LLMs以进行STEM问答和推理
- 作为RN_TR_R2模型(RefinedNeuro Turkish Reasoning v2)的蒸馏训练数据
RN_TR_R2模型通过进一步微调ytu-ce-cosmos/Turkish-Llama-8b-DPO-v0.1并使用此数据集创建。
引用
bibtex @misc{farsak2025qwen3reasoning, title = {Qwen3 Reasoning Distill Q&A Dataset}, author = {Farsak, Mehmet Can and Atayeter, Serhat}, year = {2025}, publisher = {Refined Neuro}, howpublished = {url{https://huggingface.co/datasets/RefinedNeuro/Qwen3-Reasoning-Distill-Q-A-Dataset}} }
搜集汇总
数据集介绍
构建方式
在STEM教育领域,高质量的本土化教学资源对非英语国家的知识传授至关重要。该数据集采用qwen3-32b大语言模型生成,通过精心设计的提示模板系统化构建了覆盖数学、物理、化学等七大学科的土耳其语问答对。生成过程中严格遵循年级分层(6-12年级)和问题类型规范(长/短题、难/易题),每个问题均要求数值型答案并保留模型推理过程,最终形成包含12,500条样本的未标注数据集。
特点
作为土耳其首个专注于STEM推理的生成式数据集,其显著特点体现在学科覆盖的系统性和问题设计的多样性。数据集不仅包含常规学科如数学、物理,还涵盖几何学、三角学等专业领域,每类问题均提供四种结构化变体。每条数据记录均完整保留生成提示、系统指令、问题思考链等元信息,为研究者分析模型推理过程提供透明窗口。数值型答案配合计量单位的标准化设计,特别适合训练机器理解定量推理任务。
使用方法
该数据集主要服务于土耳其语教育科技领域的研究与应用。通过HuggingFace标准接口加载后,可直接用于微调类似Turkish-Llama-8b-DPO-v0.1的本地化大语言模型。实践应用中建议结合RN_TR_R2模型的训练范式,重点关注系统提示与生成问题的映射关系。由于数据集未预设标准划分,使用者需根据具体场景按学科或年级进行分层抽样,同时可利用generated_question_thinking_part字段优化模型的思维链推理能力。
背景与挑战
背景概述
Qwen3-Reasoning-Distill-Q-A-Dataset是由Mehmet Can Farsak和Serhat Atayeter于2025年创建的土耳其语STEM领域问答数据集,旨在支持土耳其语语言模型在科学、技术、工程和数学领域的推理能力。该数据集覆盖数学、物理、化学、生物、几何、三角学和统计学等七个学科,涵盖6至12年级的教育内容。作为RefinedNeuro Turkish Reasoning v2模型的核心训练数据,该数据集通过qwen3-32b模型生成,并基于ytu-ce-cosmos/Turkish-Llama-8b-DPO-v0.1模型进行微调,为土耳其语自然语言处理领域提供了重要的教育资源。
当前挑战
该数据集面临双重挑战:在领域问题层面,需要解决土耳其语STEM教育中复杂概念的多粒度表示问题,特别是如何准确捕捉不同年级学生对抽象科学概念的理解差异;在构建过程中,需克服生成式模型产生的语义一致性问题,确保自动生成的12,500个问答对在学科准确性和语言流畅性方面达到教育标准。此外,数值型答案的单元统一性维护以及思维链注释的完整性,都对数据质量控制提出了较高要求。
常用场景
经典使用场景
在STEM教育领域,Qwen3-Reasoning-Distill-Q-A-Dataset为土耳其语教学提供了丰富的资源。该数据集覆盖数学、物理、化学等多个学科,适用于6至12年级的教学场景。通过精心设计的问答对,教师可以利用这些数据生成课堂练习或考试题目,学生则能通过解答这些问题巩固知识点。数据集中的问题设计遵循不同难度和长度要求,能够满足多样化的教学需求。
解决学术问题
该数据集有效解决了土耳其语STEM教育资源匮乏的学术问题。通过大规模生成高质量的问答对,研究者可以深入探究语言模型在特定语言环境下的推理能力。同时,数据集为跨学科知识整合研究提供了实验基础,特别是在非英语语种的数理逻辑表达方面填补了空白。其标准化的问题格式也为自动化评估模型的性能提供了可靠基准。
衍生相关工作
围绕该数据集已经产生了一系列重要研究。最典型的是RN_TR_R2模型的开发,这是在土耳其-Llama模型基础上的重要改进。许多学者利用该数据集探索小语种模型的知识蒸馏技术,相关成果发表在机器学习和教育技术领域的顶级会议上。数据集还启发了针对其他非英语语种的类似资源建设项目。
以上内容由遇见数据集搜集并总结生成


