prophet-mosque-library
收藏官方服务:
资源简介:
Prophet's Mosque Library是一个包含超过48,000本伊斯兰书籍的数据集,书籍被分为74个类别,涵盖从伊斯兰教义到历史、文化、法律等多个领域。数据集中的每本书都有PDF、TXT和DOCX三种格式,方便用户阅读和使用。
创建时间:
2025-05-05
原始信息汇总
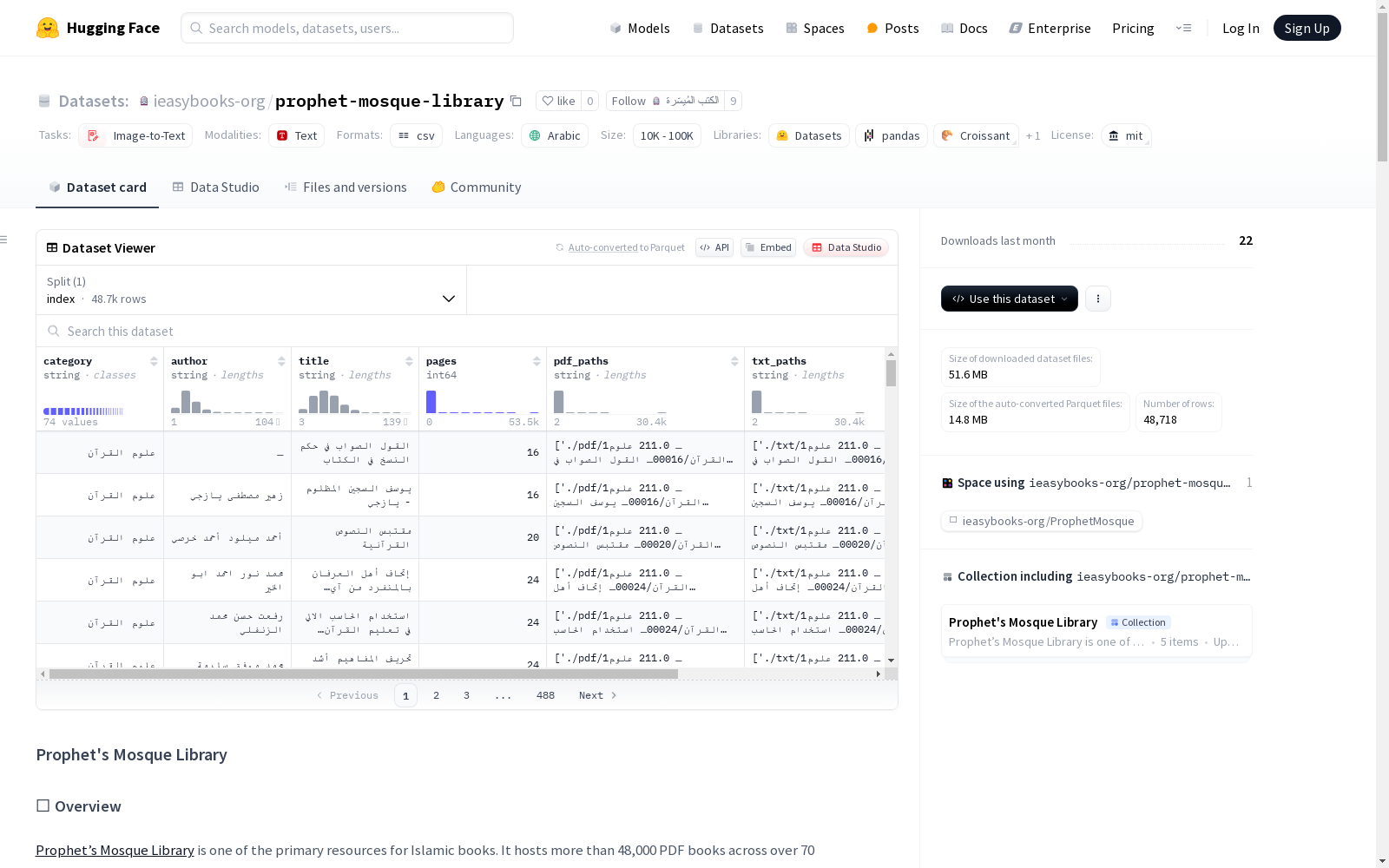
Prophets Mosque Library 数据集概述
📖 数据集简介
- 来源:Prophet’s Mosque Library是伊斯兰书籍的主要资源之一,包含超过48,000本PDF书籍,涵盖70多个类别。
- 处理方式:使用Google Document AI API处理原始PDF文件,提取内容为TXT和DOCX格式。
📊 数据集内容
- 文件数量:70,884个PDF文件(共23,494,042页),代表48,717本伊斯兰书籍。
- 文件格式:
- PDF文件位于
pdf目录。 - TXT文件位于
txt目录。 - DOCX文件位于
docx目录。
- PDF文件位于
- 目录结构:三个目录共享相同的文件夹结构。
📑 索引文件
- 文件路径:
index.tsv - 包含字段:
category:书籍类别(共74类)。author:作者。title:书名。pages:总页数。volumes:卷数。pdf_paths:PDF文件路径数组。txt_paths:TXT文件路径数组。docx_paths:DOCX文件路径数组。
📂 类别分布
- 总类别数:74类。
- 主要类别:
- 伊斯兰教法(6.48%)。
- 信仰与教义(6.26%)。
- 道德与礼仪(5.91%)。
- 文学(5.75%)。
- 教育(4.15%)。
📄 文件格式详情
TXT格式
- 内容:通过Google Document AI提取的原始文本。
- 分页标记:
PAGE_SEPARATOR。
DOCX格式
- 内容:通过Google Document AI提取的文本。
- 格式处理:连续空白字符替换为单个空格字符(
搜集汇总
数据集介绍
构建方式
该数据集源自先知清真寺图书馆的丰富伊斯兰文献资源,通过系统化的数字化流程构建而成。原始48,717册PDF书籍经过Google Document AI API处理,实现了从图像到结构化文本的转换,并衍生出TXT和DOCX两种格式。数据处理过程中严格保持原书籍的74类学科分类体系,每册文献的元数据(包括作者、标题、页数等)通过TSV索引文件进行系统编目,形成多格式、多维度关联的文献数据库。
特点
数据集最显著的特征在于其多模态文献呈现方式,同一文献同时提供PDF、TXT和DOCX三种格式,满足不同研究场景需求。TXT格式采用PAGE_SEPARATOR标记实现页面级文本定位,DOCX格式则通过空格规范化保持与原文的版面对齐。文献覆盖伊斯兰教经典研究、教法学、历史传记等74个学科门类,其中教义学(6.26%)、通用教法学(6.48%)和道德修养(5.91%)构成核心类别,形成了具有鲜明学科分布特征的宗教文献语料库。
使用方法
研究者可通过TSV索引文件快速定位目标文献,三种格式文件采用统一的目录结构实现跨格式关联。对于文本分析任务,建议优先使用TXT格式的页面分隔标记进行篇章级处理;需要保持原始排版信息时则可选择DOCX格式。该数据集特别适用于伊斯兰文献数字化研究、阿拉伯语自然语言处理以及宗教知识图谱构建,跨格式的设计允许研究者在保持文献原貌的同时进行机器可读的文本挖掘。
背景与挑战
背景概述
Prophet's Mosque Library数据集作为伊斯兰文献数字化的重要成果,由沙特阿拉伯先知清真寺图书馆官方授权发布,旨在为全球研究者提供结构化的伊斯兰学术资源。该数据集收录了超过48,000册阿拉伯语典籍,涵盖74个学科门类,时间跨度从古典时期延续至现代,涉及古兰经研究、圣训学、伊斯兰法学等核心领域。通过Google Document AI技术对原始PDF文件进行智能解析,衍生出TXT和DOCX两种结构化文本格式,为数字人文研究提供了高质量的语料基础。
当前挑战
该数据集面临双重技术挑战:在领域层面,阿拉伯语复杂的形态学特征和古典宗教文本特有的修辞结构,对自然语言处理模型的理解能力提出极高要求;在构建过程中,古籍文献的版面多样性(如多栏排版、装饰性元素)导致文档解析准确率下降,而多卷本著作的文件分割问题也增加了元数据标注的复杂度。此外,如何保持原始PDF与转换格式间的文本对齐精度,特别是在处理阿拉伯语右向书写和连字符规则时,成为技术实现的关键难点。
常用场景
经典使用场景
在伊斯兰研究领域,Prophet's Mosque Library数据集为学者提供了丰富的原始文本资源,涵盖古兰经注释、圣训研究、伊斯兰法学等多个子领域。研究者可通过跨格式的文本数据(PDF、TXT、DOCX)进行对比分析,尤其适用于伊斯兰文献的数字化保护与文本挖掘研究。其多卷本处理机制和分类体系为大规模宗教文献分析提供了结构化基础。
解决学术问题
该数据集有效解决了伊斯兰学术研究中的三大核心问题:一是碎片化宗教文献的数字化整合问题,通过标准化处理实现23万余页文本的结构化存储;二是跨时代伊斯兰学术思想的比较研究难题,覆盖从中世纪经典注释到现代法学研究的全谱系文献;三是多语言伊斯兰文本分析的技术瓶颈,原始阿拉伯语文本与衍生格式的对应关系为自然语言处理模型训练提供了优质语料。
衍生相关工作
该数据集已催生多个标志性研究成果,包括基于层次分类的伊斯兰文献自动标注系统、阿拉伯语古籍OCR精度提升方案,以及伊斯兰法学概念的知识图谱构建。在数字人文领域,学者利用其多卷本特性开发了跨世纪伊斯兰思想演变可视化工具,相关成果发表于《Journal of Islamic Manuscripts》等权威期刊。
以上内容由遇见数据集搜集并总结生成


