Shamela_Books_info
收藏Hugging Face2025-04-20 更新2025-04-21 收录
下载链接:
https://huggingface.co/datasets/MoMonir/Shamela_Books_info
下载链接
链接失效反馈官方服务:
资源简介:
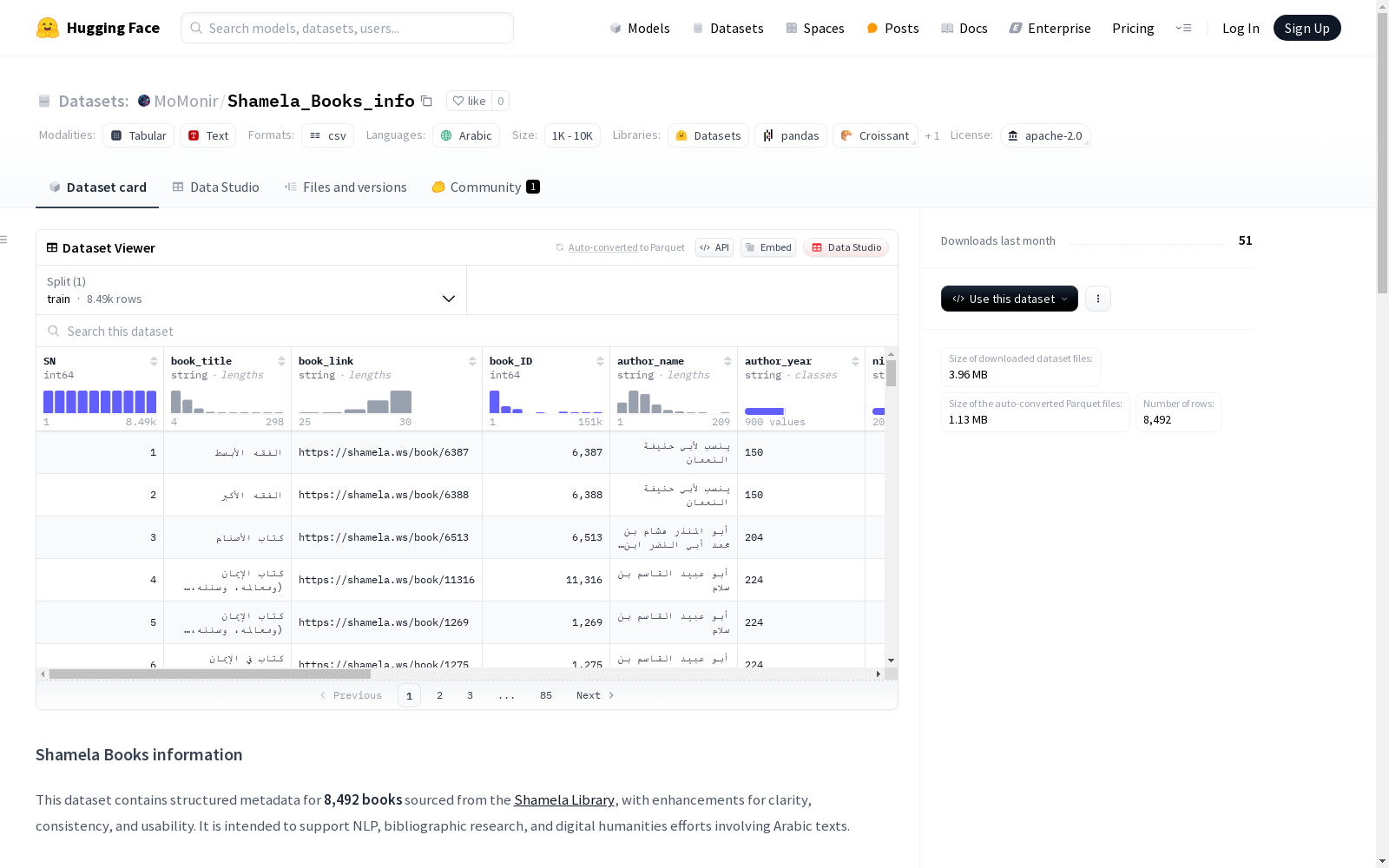
该数据集包含了来自Shamela图书馆的8,492本书的元数据结构化信息,经过了清晰度、一致性和可用性的增强。它旨在支持阿拉伯文本的自然语言处理、书目研究和数字人文工作。
创建时间:
2025-04-18
搜集汇总
数据集介绍
构建方式
该数据集基于著名的阿拉伯语数字图书馆Shamela Library,精心整理了8,492本阿拉伯语书籍的结构化元数据。通过系统化的数据清洗流程,对作者姓名、生卒年份等关键字段进行了标准化处理,确保数据的一致性和可用性。特别针对阿拉伯语文献的特点,将编者、注释者等角色信息单独标注,为学术研究提供了规范的底层数据支持。
特点
作为阿拉伯语文献研究的珍贵资源,该数据集最显著的特点是实现了作者姓名的统一标准化,并创新性地将作者卒年、别名等关键信息单独成列。多维度分类体系覆盖了书籍版本、页数、卷册等详细元数据,其独特的'编者/注释者'字段设计,有效解决了阿拉伯古籍中多重贡献者身份辨识的难题,为数字人文研究提供了精准的语义标注基础。
使用方法
在阿拉伯语自然语言处理领域,该数据集可作为预训练模型的优质语料来源,其丰富的元数据特别适合构建书籍推荐系统。研究人员可通过作者卒年字段进行历时性分析,或利用标准化的分类体系开展文献计量研究。使用时应结合Hugging Face平台提供的API接口,注意数据版本标注为2025年3月的快照,建议定期核查与源网站的同步更新情况。
背景与挑战
背景概述
Shamela_Books_info数据集由MoMonir于2025年构建,旨在为阿拉伯语文本的自然语言处理、文献目录研究及数字人文领域提供结构化元数据支持。该数据集源自著名的Shamela图书馆,涵盖8,492本阿拉伯语书籍的标准化元信息,包括作者姓名统一化、作者卒年及昵称提取等关键特征。作为伊斯兰与阿拉伯文学传统研究的重要资源,该数据集通过系统化整理古籍文献的元数据,显著提升了阿拉伯语文本挖掘的可行性与效率,为相关学术研究奠定了坚实基础。
当前挑战
该数据集面临的挑战主要体现在两个维度:在领域问题层面,阿拉伯语古籍文献存在大量异体字、历史拼写变体及非标准化命名现象,对作者消歧与文本分类任务构成显著障碍;在构建过程中,原始数据的异构性导致编者角色与作者信息混杂,需通过人工规则与算法结合实现角色字段的精准分离,而部分古籍的残缺元数据则迫使研究者采用跨文献推理等复杂方法填补字段缺失。动态更新的源图书馆内容亦要求数据集版本持续同步以维持时效性。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,Shamela_Books_info数据集为研究者提供了丰富的结构化元数据资源。该数据集最经典的使用场景在于支持阿拉伯语文本的深度分析与建模,特别是针对伊斯兰文学和古典阿拉伯语文献的研究。学者们可以基于标准化的作者信息、书籍分类和年代数据,构建跨世纪的阿拉伯文学发展脉络分析框架。
实际应用
在实际应用层面,该数据集支撑了多个阿拉伯文化传承项目。图书馆利用其元数据构建智能检索系统,使读者能通过作者别称或历史时期精确查找古籍。教育机构则基于书籍分类体系开发伊斯兰文学课程推荐工具,同时出版界借助标准化信息优化了阿拉伯古籍的数字化工作流程。
衍生相关工作
该数据集已催生多项重要研究,包括基于作者社交网络的古典知识传播分析、结合逝世年份的文学断代研究等。在技术应用方面,衍生出针对阿拉伯古籍的命名实体识别模型和自动分类系统,其中部分成果已整合到伊斯兰数字图书馆的核心检索架构中。
以上内容由遇见数据集搜集并总结生成


