CC-OCR 文字识别数据集
收藏超神经2025-02-13 更新2025-02-15 收录
下载链接:
https://hyper.ai/cn/datasets/37806
下载链接
链接失效反馈官方服务:
资源简介:
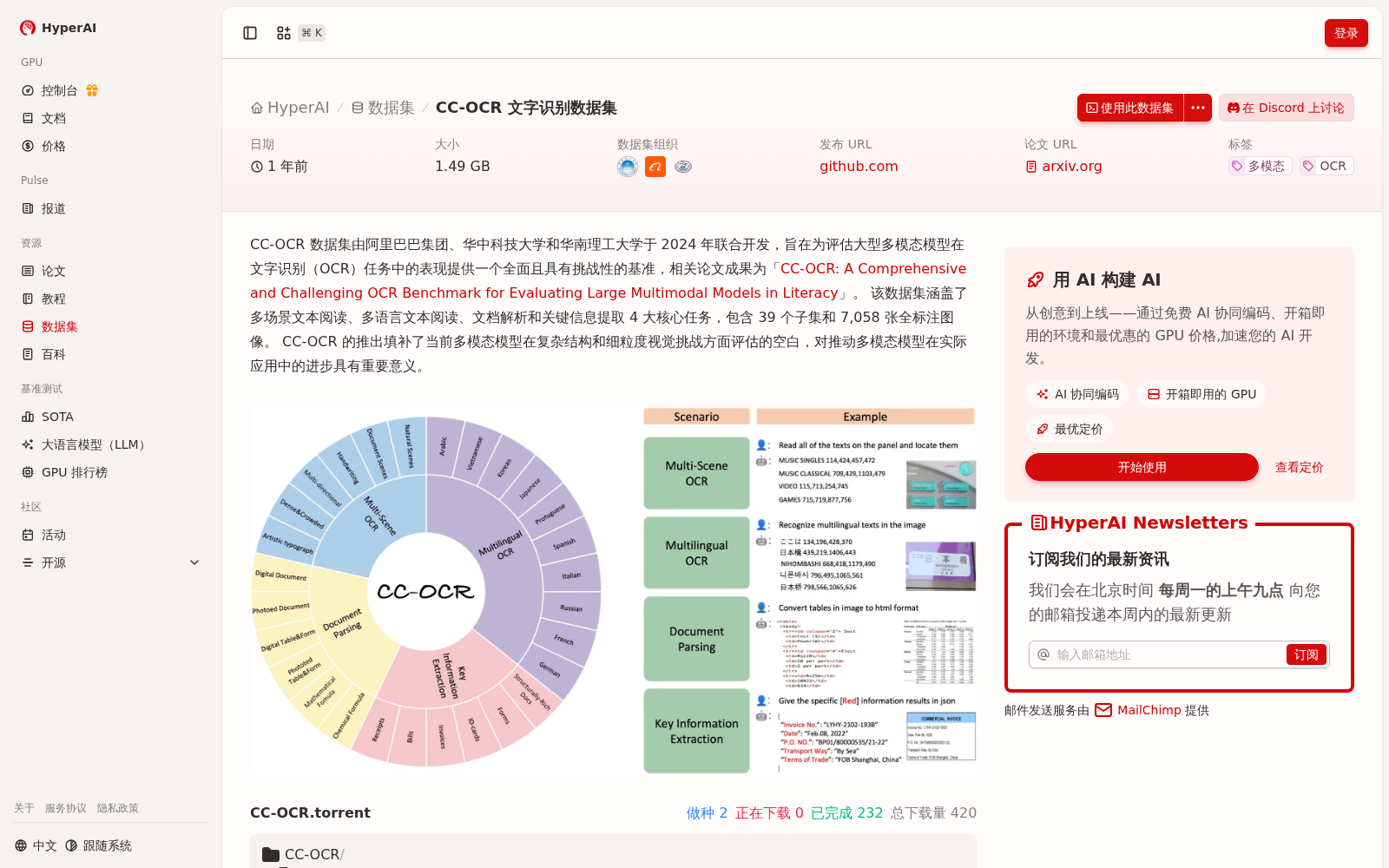
CC-OCR 数据集由阿里巴巴集团、华中科技大学和华南理工大学于 2024 年联合开发,旨在为评估大型多模态模型在文字识别(OCR)任务中的表现提供一个全面且具有挑战性的基准,相关论文成果为「CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy」。
The CC-OCR dataset was jointly developed by Alibaba Group, Huazhong University of Science and Technology, and South China University of Technology in 2024. It aims to provide a comprehensive and challenging benchmark for evaluating the performance of large multimodal models on optical character recognition (OCR) tasks. The corresponding academic paper is titled "CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy".
创建时间:
2025-02-13
搜集汇总
数据集介绍
背景与挑战
背景概述
CC-OCR文字识别数据集由阿里巴巴集团、华中科技大学和华南理工大学于2024年联合开发,旨在为评估大型多模态模型在文字识别任务中的表现提供全面且具有挑战性的基准。该数据集涵盖多场景文本阅读、多语言文本阅读、文档解析和关键信息提取四大核心任务,包含39个子集和7,058张全标注图像。
以上内容由遇见数据集搜集并总结生成


