asia-climate-all
收藏Hugging Face2026-05-04 更新2026-05-05 收录
下载链接:
https://huggingface.co/datasets/electricsheepasia/asia-climate-all
下载链接
链接失效反馈官方服务:
资源简介:
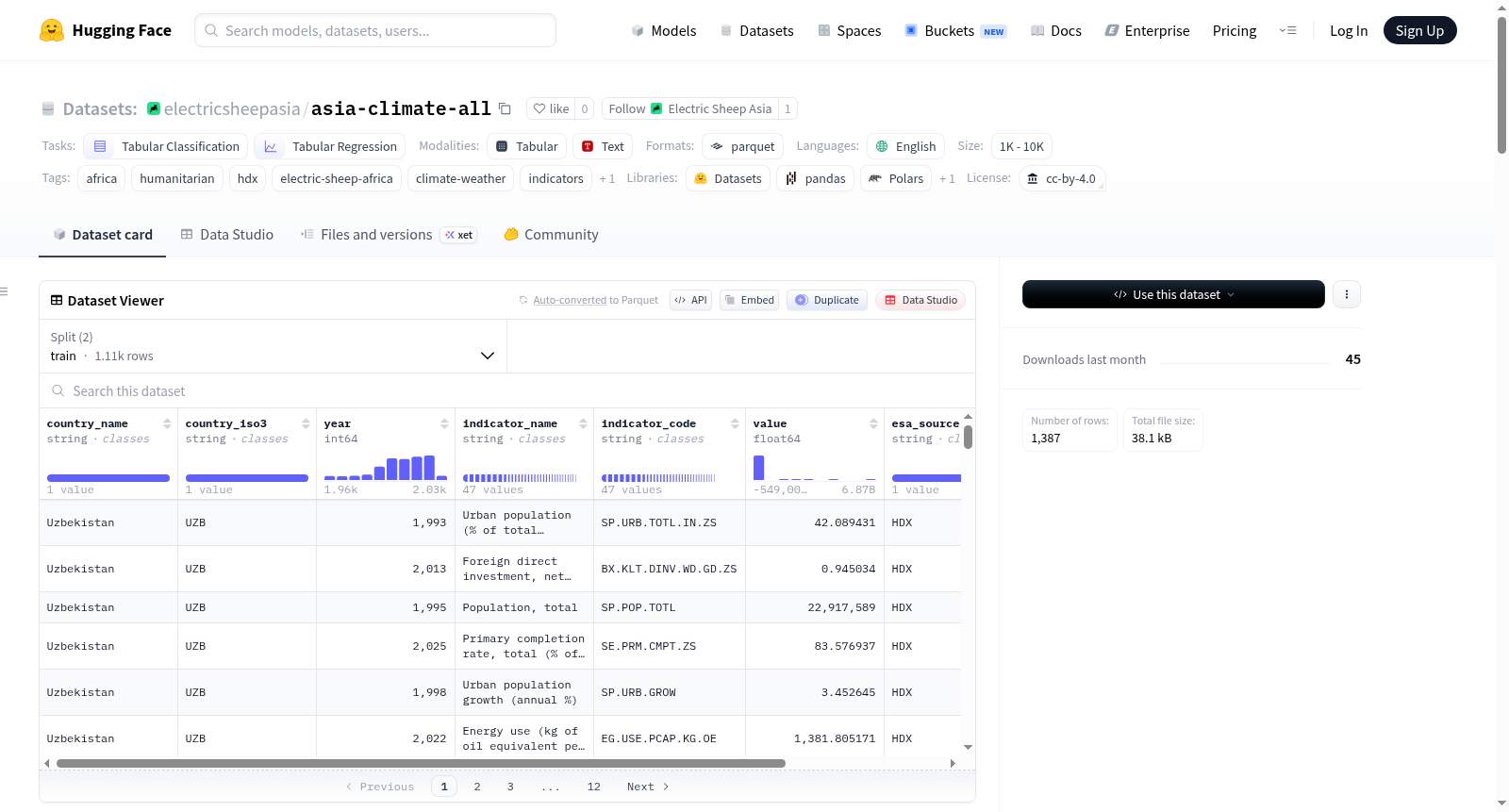
该数据集名为Korea, Rep. - Climate Change,由世界银行集团发布,旨在提供韩国气候变化相关指标的聚合数据。数据集包含气候系统、气候影响暴露度、恢复力、温室气体排放和能源使用等方面的信息,适用于粮食安全和营养领域的研究。数据集以国家级别聚合数据为观察单位,包含1,625行数据,分为1,300行的训练集和325行的测试集。数据涵盖1960年至2025年的时间范围,包含8个列(2个数值型,6个类别型),具体包括国家名称、ISO3代码、年份、指标名称、指标代码、数值、数据来源和处理日期等。数据集经过Electric Sheep Africa的整理,转换为Parquet格式,并进行了标准化处理,如列名小写、缺失值统一等。数据集适用于表格分类和回归任务,但需注意数据来源于世界银行集团,未经独立验证,可能存在报告错误或定义不一致的问题。
创建时间:
2026-05-04
原始信息汇总
数据集概述
- 数据集名称:Korea, Rep. - Climate Change(韩国 - 气候变化)
- 数据集地址:https://huggingface.co/datasets/electricsheepasia/asia-climate-all
- 发布方:World Bank Group(世界银行集团)
- 原始来源:HDX
- 许可证:CC-BY 4.0
- 最近更新日期:2026-04-28
- 地理范围:韩国(KOR)
- 语言:英语
数据集内容
该数据集包含世界银行集团提供的韩国气候变化相关指标数据,涵盖气候系统、气候影响暴露、韧性、温室气体排放和能源使用等方面。每一行代表一个国家层面的汇总数据。
数据集规模与划分
- 总行数:1,625 行
- 列数:8 列(2 个数值型,6 个分类型,0 个日期时间型)
- 训练集:1,300 行
- 测试集:325 行
变量说明
| 变量名 | 类型 | 说明 |
|---|---|---|
country_name |
object | 国家名称(Korea, Rep.) |
country_iso3 |
object | 国家 ISO3 代码(KOR) |
year |
int64 | 年份(范围:1960.0 – 2025.0) |
indicator_name |
object | 指标名称(如人口、死亡率等) |
indicator_code |
object | 指标代码(如 EN.URB.MCTY.TL.ZS) |
value |
float64 | 指标数值(范围:-2508000000.0 – 34538010000.0) |
esa_source |
object | 数据来源(HDX) |
esa_processed |
object | 处理日期(2026-05-04) |
数值型变量统计摘要
| 列名 | 最小值 | 最大值 | 均值 | 中位数 |
|---|---|---|---|---|
year |
1960.0 | 2025.0 | 1998.8246 | 2001.0 |
value |
-2508000000.0 | 34538010000.0 | 97416161.0874 | 29.9653 |
数据预处理说明
- 原始数据通过 HDX 的 CKAN API 下载,并转换为 Parquet 格式
- 列名统一为小写和下划线命名(snake_case)
- 常见缺失值标记(N/A、null、none、-、unknown、no data、#N/A)统一为 NaN
- 数据集按 80/20 比例随机拆分为训练集和测试集(固定随机种子为 42)
- 存储为 Snappy 压缩的 Parquet 文件
局限性
- 数据来源于世界银行集团,未经 Electric Sheep Africa(ESA)独立验证
- 自动化清洗无法纠正原始数据中的误报值、定义不一致或采样偏差
- 建议查阅 原始 HDX 数据集页面 了解发布方的方法说明和注意事项
快速使用示例
python from datasets import load_dataset
ds = load_dataset("electricsheepafrica/asia-climate-all") train = ds["train"].to_pandas() test = ds["test"].to_pandas()
print(train.shape) train.head()
引用格式
bibtex @dataset{hdx_asia_climate_all, title = {Korea, Rep. - Climate Change}, author = {World Bank Group}, year = {2026}, url = {https://data.humdata.org/dataset/world-bank-climate-change-indicators-for-korea-rep}, note = {Repackaged for machine learning by Electric Sheep Africa (https://huggingface.co/electricsheepafrica)} }
搜集汇总
数据集介绍
构建方式
在全球气候治理与可持续发展议程日益紧迫的背景下,世界银行集团依托其权威数据门户与HDX平台,系统整合了韩国在气候变化领域的核心宏观指标。该数据集以国家层面为观测单元,采集了1960年至2025年间涵盖城市人口集聚度、总人口规模、五岁以下儿童死亡率等多维度的面板数据。在数据工程层面,原始资料经由CKAN接口批量获取后,被统一转换为Parquet格式,并执行了列名蛇形化、缺失值标准化等清洗流程。最终通过固定随机种子以80/20比例划分为训练集与测试集,并以Snappy压缩格式持久化存储,构建出一个结构规整、可直接用于机器学习建模的表格型数据集。
特点
该数据集以紧凑而高密度的特征空间见长,仅包含8个字段却覆盖了地理标识、时序维度与核心指标三大信息层。其数值型变量'value'的取值范围横跨负值到百亿量级,反映了气候经济指标中复杂的正负向波动特征。尤为突出的是,数据集中不存在任何缺失值,所有字段均保持100%的填充率,极大地降低了预处理负担。此外,'year'字段的时间跨度长达65年,为时间序列分析与趋势建模提供了丰富的纵贯观察窗口,而分类变量如'indicator_name'则囊括了人口、健康、城市化等多主题标签,赋予数据集多维交叉分析的可能性。
使用方法
使用者可借助HuggingFace生态的datasets库一键加载,简洁的API调用即可将训练与测试分区转化为Pandas DataFrame格式,无缝衔接主流机器学习工作流。数据集兼容分类与回归两类任务范式,可根据'indicator_name'或'indicator_code'字段筛选特定指标进行单目标预测,亦可基于'year'、'country_iso3'等特征构建混合效应模型或时序预测模型。由于数据均为国家层面的聚合统计值,特别适合用于跨国比较分析、气候政策影响评估以及发展经济学的实证研究。建议在建模时对'value'列进行适当的尺度变换或离群值处理,以适配不同模型的数值敏感性。
背景与挑战
背景概述
在全球气候变化日益严峻的背景下,世界银行集团于2026年发布了面向韩国的气候变迁数据集(Korea, Rep. - Climate Change),旨在为发展中国家应对气候变化提供关键数据支撑。该数据集由世界银行集团下属机构整理,并经Electric Sheep Africa团队加工为机器学习就绪格式,涵盖气候系统、气候冲击暴露度、韧性、温室气体排放及能源利用等多个维度。其核心研究问题聚焦于量化气候变化对农业、粮食安全、水资源及减贫成果的潜在威胁,并服务于全球气候合作与政策制定。该数据集的发布为气候科学与机器学习交叉领域注入了结构化数据资源,有助于推动发展中国家在气候适应与减缓策略上的精准建模与实证研究。
当前挑战
该数据集所解决的领域问题在于为气候变迁影响评估与政策建模提供高质量的训练样本,但原始数据来自世界银行官方统计,存在报告值误差、定义不一致及采样偏差等固有局限。在构建过程中,团队需面对自动化清洗无法完全校正这些系统性问题,同时需处理指标类别多样(如城镇化人口、死亡率、总人口等)带来的异构数据融合挑战。此外,数据仅覆盖1960至2025年间韩国单个国家的国家级聚合记录,样本量有限(1625行),且价值范围跨度极大(从-25亿到345亿),这对其在跨区域泛化或细粒度时空分析中的适用性构成了显著约束。
常用场景
经典使用场景
在气候科学与可持续发展交叉领域,asia-climate-all数据集通常被用于构建基于时间序列的回归与分类模型,以揭示韩国在近数十年间气候指示因子与社会经济指标之间的内在关联。研究人员常借助该数据集探究城市化程度、人口结构变动与温室气体排放趋势之间的耦合关系,尤其关注城镇化率与碳排放强度在时间轴上的动态演化特征。此外,该数据集也为多指标联合分析提供了标准化基准,通过对诸如儿童死亡率、总人口规模、城市集聚人口比例等多元变量进行建模,有助于提炼出气候变化对不同发展阶段国家带来的差异化影响。其清洗完备、切分清晰的特性,使其成为验证统计学习方法与机器学习算法在气候数据上适应性的理想平台。
解决学术问题
该数据集切入了一个极具现实意义的学术命题——如何基于国家尺度的宏观数据,构建可量化、可迁移的气候变化影响评估框架。传统气候研究往往受限于数据碎片化与口径不一,而asia-climate-all通过整合世界银行权威指标,并以统一结构呈现,为探索气候暴露度、适应能力与社会经济脆弱性之间的因果关系提供了坚实的数据基础。它的出现有效缓解了机器学习领域长期缺乏高质量、标准化的气候变化面板数据集的困境,使得研究者可专注于设计解释性强、泛化性能优越的预测模型。更重要的是,该数据集为验证‘气候变化是否加剧了公共卫生风险’或‘城镇化进程是否与碳排放脱钩’等关键假说提供了可复现的实证支撑,推动了环境经济学与公共政策研究的量化转向。
衍生相关工作
围绕asia-climate-all数据集所代表的标准化国家气候指标集合,学术界已衍生出一系列具有深远影响的研究工作。基于类似结构的世界银行气候面板数据,研究者发展出深度时序模型(如LSTM与Transformer架构)用以捕捉气候因子与社会变量的非线性延迟效应,相关成果常见于《Nature Climate Change》与《Environmental Research Letters》等高水平期刊。此外,若干前沿工作将此与高分辨率卫星影像数据融合,构建多模态系统以识别气候极端事件带来的农业减产风险。在开源社区中,围绕该数据集的基准测试(Benchmark)也催生了一批专用预测工具与特征工程库,推动气象与公共健康交叉领域的可复现研究文化。这些衍生贡献不仅提升了数据本身的影响力,更实质性地拓展了机器学习在气候适应科学中的应用疆界。
以上内容由遇见数据集搜集并总结生成


