StyleExpert-500K
收藏arXiv2026-03-17 更新2026-03-19 收录
下载链接:
https://hh-lg.github.io/StyleExpert-Page/
下载链接
链接失效反馈官方服务:
资源简介:
StyleExpert-500K是由南开大学与vivo蓝心实验室联合构建的大规模风格迁移数据集,包含50万组内容-风格-风格化三元组。该数据集通过精选209个Hugging Face社区的优质风格LoRA模型,结合2700张跨类别基础图像和OmniConsistency LoRA技术生成,显著改善了现有数据集中色彩与语义失衡的问题。数据集涵盖从像素级色彩到纹理、笔触等语义级特征的多元风格,特别强化了传统方法难以捕捉的材质与氛围表达,为语义感知的风格迁移研究提供了高质量基准。
StyleExpert-500K is a large-scale style transfer dataset jointly constructed by Nankai University and vivo Blue Heart Laboratory. It contains 500,000 triplets of content-style-stylized pairs. The dataset is generated by selecting 209 high-quality style LoRA models from the Hugging Face community, combining 2,700 cross-category base images and the OmniConsistency LoRA technology, which significantly alleviates the color and semantic imbalance issues in existing datasets. It covers diverse styles ranging from pixel-level color details to semantic-level features such as textures and brushstrokes, and specially enhances the expression of materials and atmospheres that are difficult to capture with traditional methods. This dataset provides a high-quality benchmark for semantic-aware style transfer research.
提供机构:
南开大学·计算机科学与技术学院; 深圳福田·南开大学人工智能研究院; 天津大学; vivo蓝心实验室
创建时间:
2026-03-17
原始信息汇总
StyleExpert数据集概述
数据集名称
StyleExpert-500K
数据集规模
包含约500,000个内容-风格-风格化三元组。
数据集构建目的
克服现有数据集中颜色与语义不平衡的问题,构建一个高度连贯的三元组数据集,优先考虑语义信息(如纹理和材质)而非表面的颜色特征。
数据来源与构建方法
- 从Hugging Face社区利用了209个高质量、以风格为中心的LoRA模型。
- 使用大型视觉语言模型(Qwen)仔细重写图像描述,以去除混杂的风格信息,确保提示仅描述客观内容。
- 应用严格的基于VLM的过滤流程,以剔除风格化效果差或布局退化的结果。
数据集特点
- 包含内容-风格-风格化三元组。
- 强调语义信息(如纹理和材质)优先于浅层颜色特征。
- 经过严格筛选,确保高度连贯性。
搜集汇总
数据集介绍
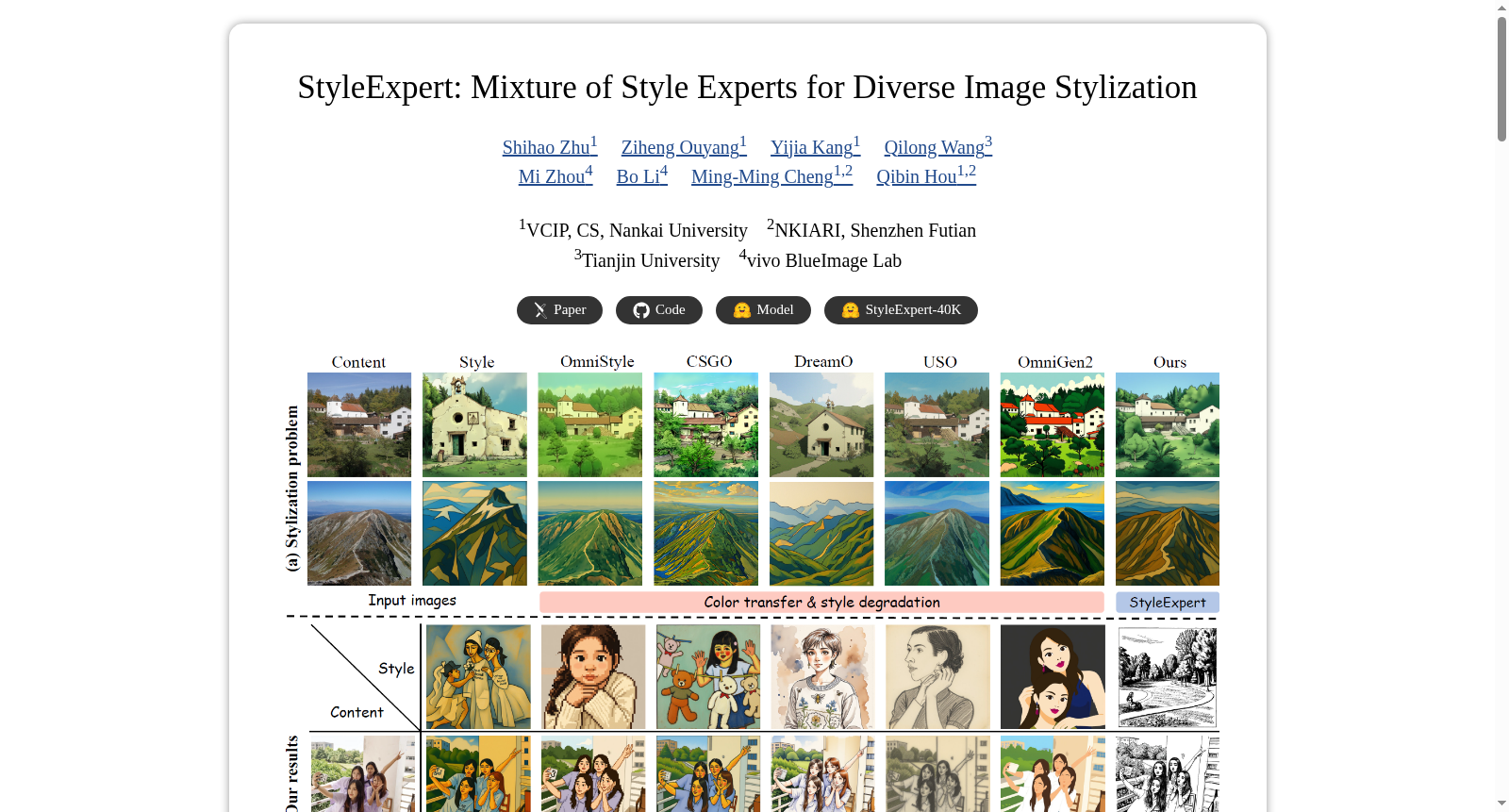
构建方式
在图像风格迁移领域,现有数据集普遍存在色彩与语义失衡的局限,StyleExpert-500K的构建旨在突破这一瓶颈。该数据集通过精心设计的流水线生成,首先从开源社区手动筛选出209个高质量风格LoRA模型,这些模型涵盖了从像素级到语义级的多样化风格表达。随后,基于约2700张涵盖人物、景观、建筑等多类别的内容图像,结合内容保持的OmniConsistency LoRA与各风格LoRA生成风格化结果。为确保数据质量,利用Qwen-VL模型对生成结果进行严格过滤,剔除存在布局退化、属性错误或伪影的样本,并通过CLIP相似度从同一风格域中为每个风格化图像选取最具代表性的风格参考图像,最终形成约50万个内容-风格-风格化三元组的高质量数据集。
特点
StyleExpert-500K的核心特征在于其卓越的风格语义多样性与平衡性。与以往侧重于简单色彩迁移的数据集不同,该数据集系统性地涵盖了色彩、线条、纹理及深层语义等多个风格层级,实现了色彩中心与语义中心风格的均衡分布。数据集中包含的209种风格均经过人工筛选与去重,确保了风格表征的独特性与高质量。此外,通过引入严格的视觉语言模型过滤与参考图像选择机制,数据集在风格保真度、内容一致性以及视觉美学质量方面均表现出显著优势,为语义感知的风格迁移研究提供了丰富而可靠的基准。
使用方法
StyleExpert-500K主要服务于基于扩散模型的高级风格迁移方法的研究与评估。在模型训练方面,该数据集可用于训练风格编码器与混合专家(MoE)架构,其中风格编码器通过InfoNCE损失学习判别性风格表示,而MoE路由机制则依据编码器提供的风格先验动态选择专家,实现多粒度风格的高效适配。在评估层面,数据集支持对模型在内容保真度、风格相似度、美学质量及语义迁移能力等多维度的定量测评,例如通过CLIP、DINO、CSD、DreamSim及专门设计的Qwen语义分数等指标进行综合衡量。此外,数据集的划分遵循90%训练与10%测试的比例,确保了模型在未见风格上的泛化能力验证。
背景与挑战
背景概述
在图像风格迁移领域,现有方法常局限于浅层的颜色映射,难以捕捉纹理、笔触等深层语义信息。为应对这一挑战,南开大学、天津大学与vivo BlueImage Lab的研究团队于2026年提出了StyleExpert-500K数据集。该数据集包含约50万个内容-风格-风格化三元组,旨在为语义感知的风格迁移提供高质量、语义多样化的训练资源。其核心研究问题在于解决现有数据集中颜色与语义风格严重失衡的缺陷,通过整合社区LoRA模型并引入严格的质量过滤流程,构建了一个覆盖从颜色、线条到材质、氛围等多层次语义风格的基准。该数据集的建立为推进扩散模型在复杂艺术风格迁移中的应用奠定了重要基础,显著提升了模型对未见风格的泛化能力。
当前挑战
StyleExpert-500K数据集旨在解决语义级图像风格迁移的核心挑战,即如何超越简单的颜色传递,实现对风格图像中纹理、线条、材质等深层语义属性的精准迁移。其构建过程面临多重困难:首要挑战在于克服现有风格数据集的严重不平衡性,它们过度侧重颜色风格而缺乏语义丰富的样本。为此,研究团队需从海量社区LoRA模型中手动筛选出209个高质量模型,并设计包含CLIP相似度匹配与Qwen-VL质量过滤的复杂流水线,以生成并净化三元组数据。另一关键挑战在于确保风格化结果在转换风格的同时,能严格保持原始图像的内容结构与空间布局,避免出现语义扭曲或视觉伪影,这对数据生成与清洗流程的鲁棒性提出了极高要求。
常用场景
经典使用场景
在图像风格迁移领域,StyleExpert-500K数据集为基于扩散模型和专家混合架构的语义感知风格迁移研究提供了核心数据支撑。该数据集通过精心构建的50万条内容-风格-风格化三元组,覆盖了从浅层色彩到深层纹理、线条及材质等多元语义层次的风格类型,为训练能够理解并迁移复杂语义信息的模型奠定了数据基础。其经典应用场景集中于训练和评估如StyleExpert框架等先进模型,这些模型通过预训练的风格编码器和MoE路由机制,实现对多样化艺术风格的精准捕捉与高质量迁移。
衍生相关工作
StyleExpert-500K数据集的构建理念与方法论,启发并支撑了一系列相关的经典研究工作。其核心的MoE(专家混合)与风格编码器结合的思想,为后续研究如何高效整合与路由多样化风格信息提供了范式。数据集本身作为高质量、语义丰富的基准,促进了针对复杂风格迁移的模型评估体系发展,例如基于Qwen的语义评分指标。此外,其数据构建流程——包括利用社区LoRA、内容一致性控制以及基于VLM的质量过滤——为后续大规模、高质量风格化数据集的构建提供了可复用的技术蓝图,推动了整个领域向更注重语义保真度与风格多样性的方向发展。
数据集最近研究
最新研究方向
在图像风格迁移领域,StyleExpert-500K数据集正推动研究范式从浅层色彩映射转向深层语义理解。该数据集通过精心构建的50万内容-风格-风格化三元组,解决了现有数据中色彩与语义失衡的瓶颈,为基于混合专家(MoE)的语义感知框架提供了高质量训练基础。前沿研究聚焦于利用预训练风格编码器引导MoE路由机制,实现从纹理、笔触到材质等多层次语义属性的动态迁移,显著提升了模型对未见风格的泛化能力。这一进展不仅突破了传统方法在复杂艺术风格表达上的局限,也为个性化内容生成、数字艺术创作等应用场景注入了新的技术活力。
相关研究论文
- 1Mixture of Style Experts for Diverse Image Stylization南开大学·计算机科学与技术学院; 深圳福田·南开大学人工智能研究院; 天津大学; vivo蓝心实验室 · 2026年
以上内容由遇见数据集搜集并总结生成


