IDEA-Bench
收藏IDEA-Bench 数据集概述
数据集描述
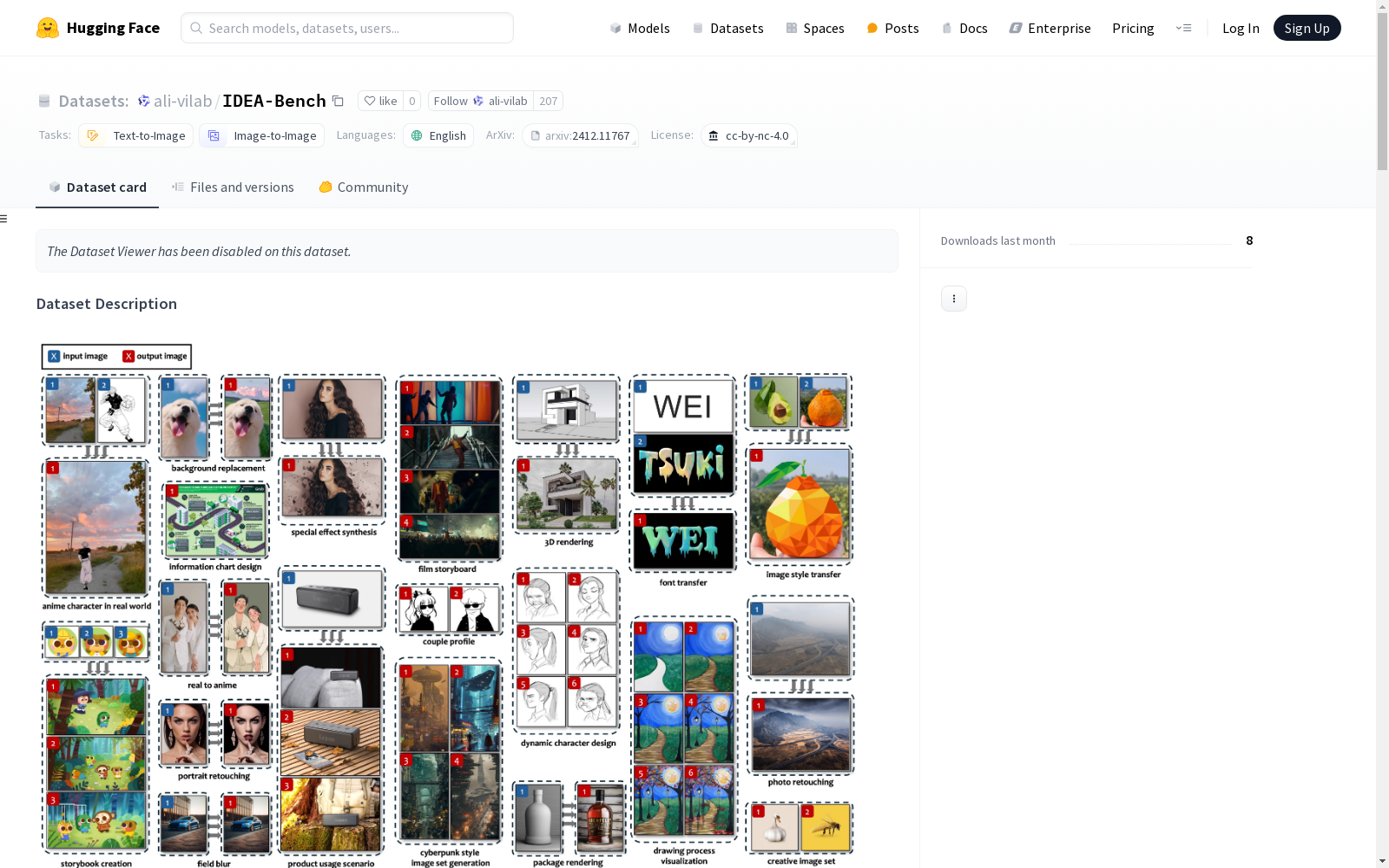
IDEA-Bench 是一个综合基准,旨在评估生成模型在专业设计任务中的性能。它包含 100 个精心挑选的任务,涵盖五个类别:文本到图像、图像到图像、图像到图像、文本到图像和图像到图像。这些任务涵盖了广泛的应用,包括故事板、视觉效果、照片修饰等。
IDEA-Bench 通过 275 个测试用例和 1,650 个详细的评估标准,提供了一个强大的框架,旨在弥合当前生成模型能力与专业级要求之间的差距。
支持的任务
该数据集支持以下任务:
- 文本到图像生成
- 图像到图像变换
- 图像到图像合成
- 文本到图像生成
- 图像到图像生成
使用场景
IDEA-Bench 旨在评估生成模型在专业级图像设计中的能力,测试其一致性、上下文相关性和多模态集成能力。它适用于基准测试文本到图像模型、图像编辑工具和通用生成系统的进展。
数据集格式和结构
数据组织
数据集被组织成 275 个子目录,每个子目录代表一个独特的评估案例。每个子目录包含以下组件:
-
instruction.txt
包含用于生成图像的提示的纯文本文件。 -
meta.json
提供特定评估案例元数据的 JSON 文件。其结构如下: json { "task_name": "special effect adding", "num_of_cases": 3, "image_reference": true, "multi_image_reference": true, "multi_image_output": false, "uid": "0085", "output_image_count": 1, "case_id": "0001" } -
Image Files
可选的 .jpg 文件,按顺序命名(例如,0001.jpg, 0002.jpg),表示案例的输入图像。某些案例可能不包含图像文件。 -
eval.json
包含六个评估问题的 JSON 文件,以及详细的评分标准。示例格式: json { "questions": [ { "question": "Does the output image contain circular background elements similar to the second input image?", "0_point_standard": "The output image does not have circular background elements, or the background shape significantly deviates from the circular structure in the second input image.", "1_point_standard": "The output image contains a circular background element located behind the main subjects head, similar to the visual structure of the second input image. This circular element complements the subjects position, enhancing the composition effect." }, ... ] } -
auto_eval.jsonl
某些子目录包含auto_eval.jsonl文件。该文件用于多模态大语言模型(MLLMs)的自动化评估。
示例案例结构
对于任务“special effect adding”,文件夹结构可能如下:
special_effect_adding_0001/ ├── 0001.jpg ├── 0002.jpg ├── 0003.jpg ├── instruction.txt ├── meta.json ├── eval.json ├── auto_eval.jsonl
评估
人工评估
IDEA-Bench 的评估过程包括严格的人工评分系统。每个案例根据其子目录中的 eval.json 文件进行评估。评分过程遵循层次结构:
-
层次评分:
- 如果问题 1 或问题 2 得分为 0,则剩余四个问题(问题 3–6)自动得分为 0。
- 如果问题 3 或问题 4 得分为 0,则最后两个问题(问题 5 和 6)得分为 0。
-
任务级分数:
- 共享相同
uid的案例分数被平均以计算任务分数。
- 共享相同
-
类别和最终分数:
- 某些任务被归类为专业级类别,其分数按
task_split.json中的描述进行汇总。 - 五个主要类别的最终分数通过平均每个类别内的任务分数获得。
- 总体模型分数是五个主要类别分数的平均值。
- 某些任务被归类为专业级类别,其分数按
MLLM 评估
自动化评估利用多模态大语言模型(MLLMs)评估 auto_eval.jsonl 文件中包含的精细调整提示的子集。这些提示由标注者精心调整,以确保详细的准确评估。