iletisim/dezenformasyon-bultenleri
收藏Hugging Face2026-05-03 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/iletisim/dezenformasyon-bultenleri
下载链接
链接失效反馈官方服务:
资源简介:
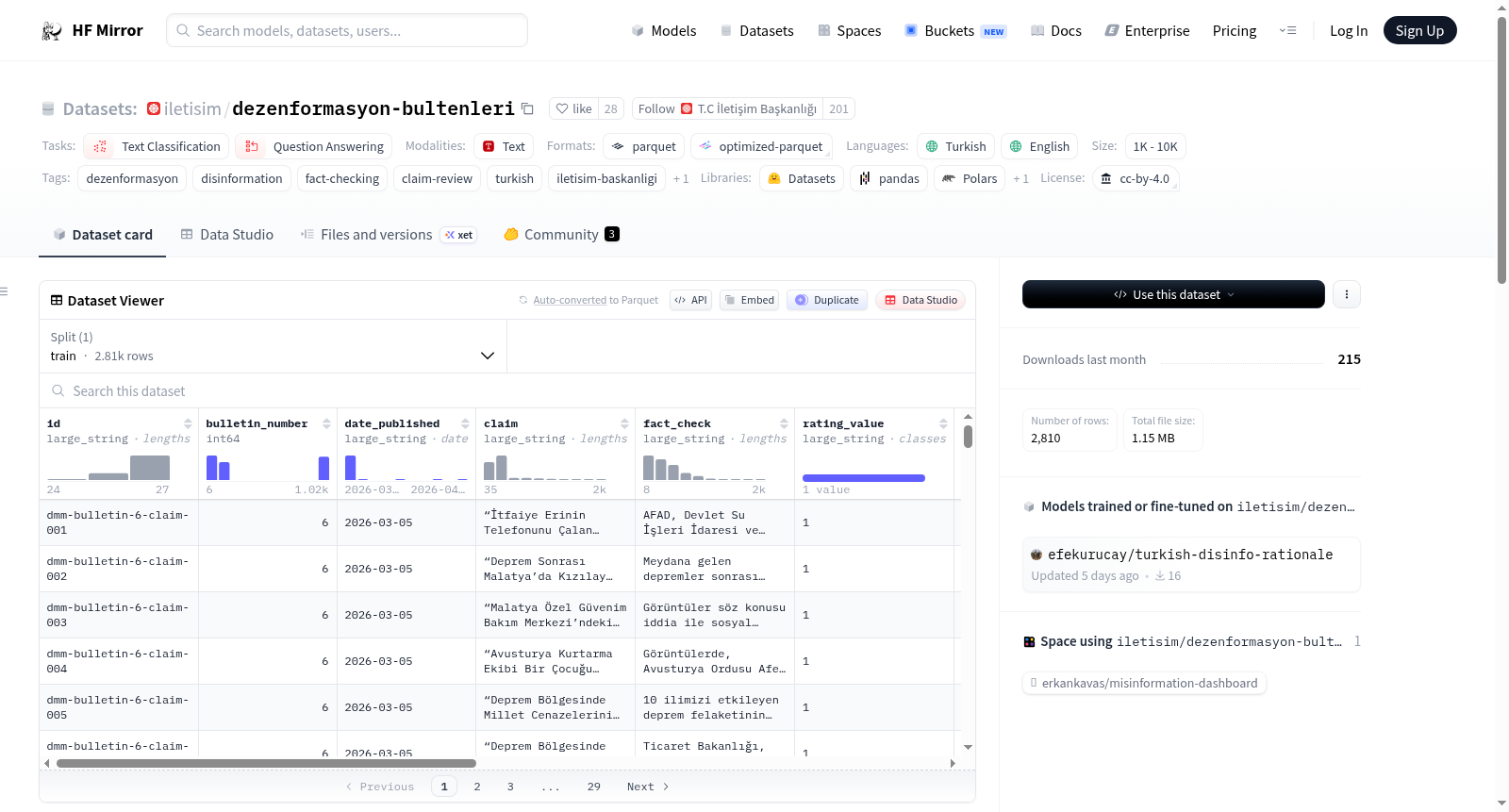
该数据集名为İletişim Başkanlığı Dezenformasyon Bültenleri (ClaimReview),包含土耳其总统府通讯局反虚假信息中心(DMM)每周发布的《虚假信息简报》中的所有声明-事实核查记录。数据按照Schema.org ClaimReview标准构建,包含声明文本、事实核查、评级和发布日期等字段。数据集采用CC BY 4.0许可协议,适用于文本分类和问答等任务。
The dataset named İletişim Başkanlığı Dezenformasyon Bültenleri (ClaimReview) contains all claim-fact-check records from the weekly Disinformation Bulletins published by the Turkish Presidencys Directorate of Communications - Center for Combating Disinformation (DMM). The data is structured according to the Schema.org ClaimReview standard and includes fields such as claim text, fact check, rating, and publication details. The dataset is licensed under CC BY 4.0 and is intended for tasks like text classification and question answering.
提供机构:
iletisim
搜集汇总
数据集介绍
构建方式
在信息泛滥的数字时代,虚假信息的识别与辟谣成为维护公共舆论健康的关键挑战。该数据集由土耳其共和国总统府通信局虚假信息打击中心(DMM)每周发布的《虚假信息公报》整理而成,收录了所有声明与事实核查的完整记录。数据按照Schema.org的ClaimReview标准进行结构化处理,每个条目包含唯一标识符、公报编号、发布日期、虚假信息声明文本、官方核实的事实内容、评分等级(1至5分制)及标签,并附有API链接与源页面地址,确保了数据的可追溯性与标准化。
特点
该数据集以土耳其语为主,兼具英语标注,覆盖文本分类与问答两大任务领域。其核心特点在于结构化的评分机制,通过从“错误”到“正确”的等级标签,直观呈现每项声明的真实性判定。此外,数据源于官方权威机构,经过系统化归档与API接口公开,兼具时效性与可靠性。集内包含数千条记录,支持按公报编号筛选、批量分析及与Pandas等工具集成,为虚假信息检测与事实核查研究提供了高质量的标注资源。
使用方法
数据集可通过Hugging Face的Datasets库便捷加载,调用`load_dataset("iletisim/dezenformasyon-bultenleri", split="train")`即可获取训练集。用户可直接访问各记录的声明与核查结果,或利用`filter`方法按公报编号提取特定批次的内容。借助`to_pandas()`函数,数据可转换为DataFrame格式,便于进行分组统计与深度分析。该数据集适用于文本分类任务(如判别真假信息)及问答任务(如基于声明检索对应事实),为多语种事实核查研究提供了灵活的工具基础。
背景与挑战
背景概述
在信息爆炸的时代,虚假信息(dezenformasyon)的传播对社会稳定与公共信任构成了严峻挑战。为应对这一问题,土耳其共和国总统府通信局下属的虚假信息应对中心(DMM)自2020年起定期发布《虚假信息公报》,系统性地揭露并纠正广泛流传的谬误主张。2024年,该机构联合研究团队将这些公报内容整理为结构化数据集,即“dezenformasyon-bultenleri”,遵循Schema.org的ClaimReview标准,收录了超过数千条主张与事实核查记录。该数据集为多语言(土耳其语与英语)文本分类与问答任务提供了宝贵的监督学习资源,成为打击虚假信息领域的重要基准,尤其推动了低资源语言环境下的自动事实核查研究。
当前挑战
该数据集面临的核心挑战源于虚假信息本身的复杂性:第一,虚假主张往往巧妙伪装于半真半假的叙述中,要求模型具备深层语义理解与常识推理能力,而现有模型在跨文化语境中的泛化表现尚不理想。第二,数据构建过程中,DMM需从海量社交媒体与新闻源中人工筛选高影响力的可疑主张,这一过程耗时且易受主观偏差影响;同时,每周发布的公报需在保证时效性的前提下完成严格的事实核查,对专家团队的持续投入提出了极高要求。此外,数据规模相对有限(1千至1万条),且标注仅涵盖二元或分级评分,缺乏对主张传播网络与受众影响的记录,制约了多维真实性分析的发展。
常用场景
经典使用场景
该数据集源自土耳其共和国总统府通信局虚假信息防治中心每周发布的虚假信息公报,收录了经过结构化整理的声明与事实核查记录,遵循Schema.org的ClaimReview标准。经典使用场景聚焦于文本分类与问答任务,研究者可据此构建自动化的虚假信息识别模型,通过训练分类器判定社交媒体或新闻中传播的声明是否为虚假信息,亦可在问答系统中实现针对特定虚假声明的事实真相检索与生成。
实际应用
在实际应用中,该数据集助力媒体机构与公共管理部门构建智能事实核查系统,自动监测并标注网络空间中流传的虚假声明。它还可嵌入社交媒体平台的实时内容审核流程,辅助标记可疑信息并向用户提供经官方核验的真相说明,从而提升公共信息的可信度,遏制谣言的二次传播。
衍生相关工作
在该数据集的基础上,衍生出了一系列相关经典工作,包括开发基于预训练语言模型的土耳其语虚假信息检测工具、构建融合声明文本与元数据的多模态分类框架,以及设计面向事实核查结果的可解释性分析模型。此外,它催生了针对土耳其语场景的虚假信息传播动态建模研究,为后续构建跨领域、多语种的事实核查知识图谱奠定了基础。
以上内容由遇见数据集搜集并总结生成


