afrimgsm
收藏Hugging Face2024-07-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/yuntian-deng/afrimgsm
下载链接
链接失效反馈官方服务:
资源简介:
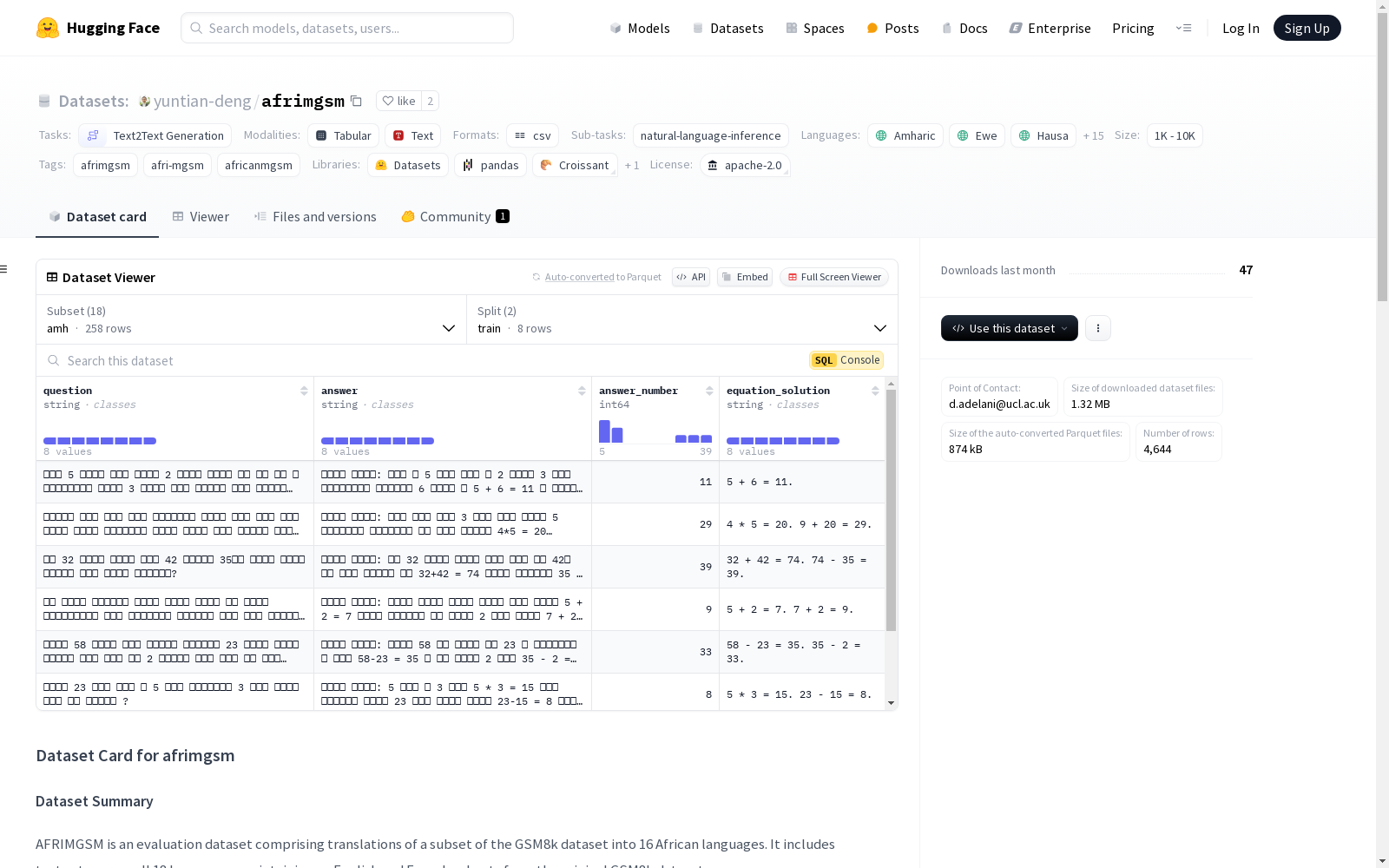
AFRIMGSM是一个评估数据集,包含将GSM8k数据集的一个子集翻译成16种非洲语言。该数据集包括18种语言的测试集,保留了原始GSM8k数据集的英语和法语子集。数据集结构包括问题和答案两个字段,每个语言都有训练和测试两个分割,大小分别为8和250。
创建时间:
2024-07-17
原始信息汇总
数据集卡片 for afrimgsm
数据集描述
数据集摘要
AFRIMGSM 是一个评估数据集,包含 GSM8k 数据集的一个子集翻译成 16 种非洲语言。它包括所有 18 种语言的测试集,保留了原始 GSM8k 数据集的英语和法语子集。
语言
数据集包含以下 18 种语言:
- am
- ee
- ha
- ig
- kin
- ln
- lug
- orm
- sna
- sot
- sw
- tw
- wo
- xh
- yo
- zu
- en
- fr
数据集结构
数据实例
英语数据实例示例如下:
python from datasets import load_dataset data = load_dataset(masakhane/afrimgsm, eng)
请指定语言代码
数据点示例如下:
{ question: A football team played 22 games. They won 8 more than they lost. How many did they win?, answer: 15 }
数据字段
question: 小学数学问题的字符串问题。answer: 最终的数值答案。
数据分割
所有语言都有两个分割:train 和 test,它们对应于 GSM8k 数据集的原始 train 和 test 分割。
分割的大小如下:
| Language | train | test |
|---|---|---|
| am | 8 | 250 |
| ee | 8 | 250 |
| ha | 8 | 250 |
| kin | 8 | 250 |
| ln | 8 | 250 |
| lug | 8 | 250 |
| orm | 8 | 250 |
| sna | 8 | 250 |
| sw | 8 | 250 |
| tw | 8 | 250 |
| wo | 8 | 250 |
| xh | 8 | 250 |
| yo | 8 | 250 |
| zu | 8 | 250 |
| en | 8 | 250 |
| fr | 8 | 250 |
| xh | 8 | 250 |
| xh | 8 | 250 |
| xh | 8 | 250 |
搜集汇总
数据集介绍
构建方式
AFRIMGSM数据集是基于GSM8k数据集的一个子集,通过将其翻译成16种非洲语言构建而成。该数据集保留了GSM8k中的英语和法语子集,并在此基础上扩展了多种非洲语言的测试集。每个语言的数据集均包含训练集和测试集,数据格式为TSV文件,确保了数据的结构化和易于处理。
特点
AFRIMGSM数据集涵盖了18种语言,包括多种非洲语言以及英语和法语。每个语言的数据集均包含训练集和测试集,数据量适中,适合用于多语言文本生成任务。数据集中的每个样本包含一个数学问题和其对应的数值答案,适用于自然语言推理和文本生成任务。
使用方法
使用AFRIMGSM数据集时,可以通过Hugging Face的`datasets`库加载特定语言的数据集。用户需指定语言代码,例如`eng`表示英语。加载后的数据集包含`question`和`answer`两个字段,分别表示数学问题和答案。该数据集适用于多语言文本生成模型的训练和评估,尤其适合用于非洲语言的自然语言处理研究。
背景与挑战
背景概述
AFRIMGSM数据集是一个基于GSM8k数据集的评估数据集,旨在将数学问题翻译成16种非洲语言,并保留了原始GSM8k数据集中的英语和法语子集。该数据集的创建旨在推动非洲语言在自然语言处理领域的研究与应用,特别是在数学问题求解任务中的多语言能力评估。通过将数学问题翻译成多种非洲语言,AFRIMGSM为研究多语言模型在低资源语言环境下的表现提供了重要资源。该数据集由Masakhane社区的研究人员主导开发,反映了非洲语言多样性和自然语言处理技术在全球范围内的扩展需求。
当前挑战
AFRIMGSM数据集面临的挑战主要体现在两个方面。首先,在领域问题方面,该数据集旨在解决多语言数学问题求解的挑战,尤其是在低资源语言环境下的模型表现评估。由于非洲语言的语法结构和表达方式与英语等主流语言存在显著差异,模型在处理这些语言时可能面临理解偏差和翻译错误的问题。其次,在数据集构建过程中,研究人员需要克服语言资源匮乏、翻译质量控制和数据标注一致性等挑战。许多非洲语言的可用语料库有限,翻译过程中需要依赖双语专家或自动化工具,这可能导致数据质量的不一致性。此外,确保翻译后的数学问题在语义和逻辑上与原始问题保持一致,也是构建过程中的一大难点。
常用场景
经典使用场景
afrimgsm数据集主要用于评估多语言模型在非洲语言环境下的数学问题解决能力。该数据集通过将GSM8k数据集中的数学问题翻译成16种非洲语言,为研究者提供了一个跨语言的自然语言推理任务平台。经典的使用场景包括测试模型在不同语言环境下的泛化能力,尤其是在低资源语言中的表现。
解决学术问题
afrimgsm数据集解决了在低资源语言环境下进行自然语言处理和数学推理的挑战。通过提供多语言的数学问题数据集,研究者能够评估和优化模型在非洲语言中的表现,填补了现有研究中非洲语言数据稀缺的空白。这一数据集为跨语言模型的开发和评估提供了重要的基准,推动了多语言自然语言处理技术的发展。
衍生相关工作
afrimgsm数据集衍生了一系列相关研究,特别是在多语言自然语言处理领域。基于该数据集的研究工作包括开发跨语言数学问题解答模型、优化低资源语言的自然语言推理算法等。这些研究不仅推动了非洲语言处理技术的发展,还为全球多语言模型的优化提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


