SpatialVID
收藏Hugging Face2025-09-17 更新2025-09-18 收录
下载链接:
https://huggingface.co/datasets/FelixYuan/SpatialVID
下载链接
链接失效反馈官方服务:
资源简介:
SpatialVID是一个大规模视频数据集,包含空间注释,用于文本到视频、文本到3D、图像到3D、图像到视频和其他任务。数据集大约10TB大小,分为545组以便于管理。每组包含大约14GB的视频数据和1.5GB的注释数据。数据集包括每个视频片段的元数据,可以使用pandas进行过滤和分析。注释包括标题、动态掩码、相机内参、相机位姿和运动指令。数据集旨在用于研究和非商业用途。
创建时间:
2025-09-08
原始信息汇总
SpatialVID 数据集概述
数据集基本信息
- 名称:SpatialVID
- 描述:大规模空间标注视频数据集
- 许可证:CC-BY-NC-SA-4.0
- 数据规模:约10TB
- 语言:英文
- 任务类别:文本到视频、文本到3D、图像到3D、图像到视频、其他
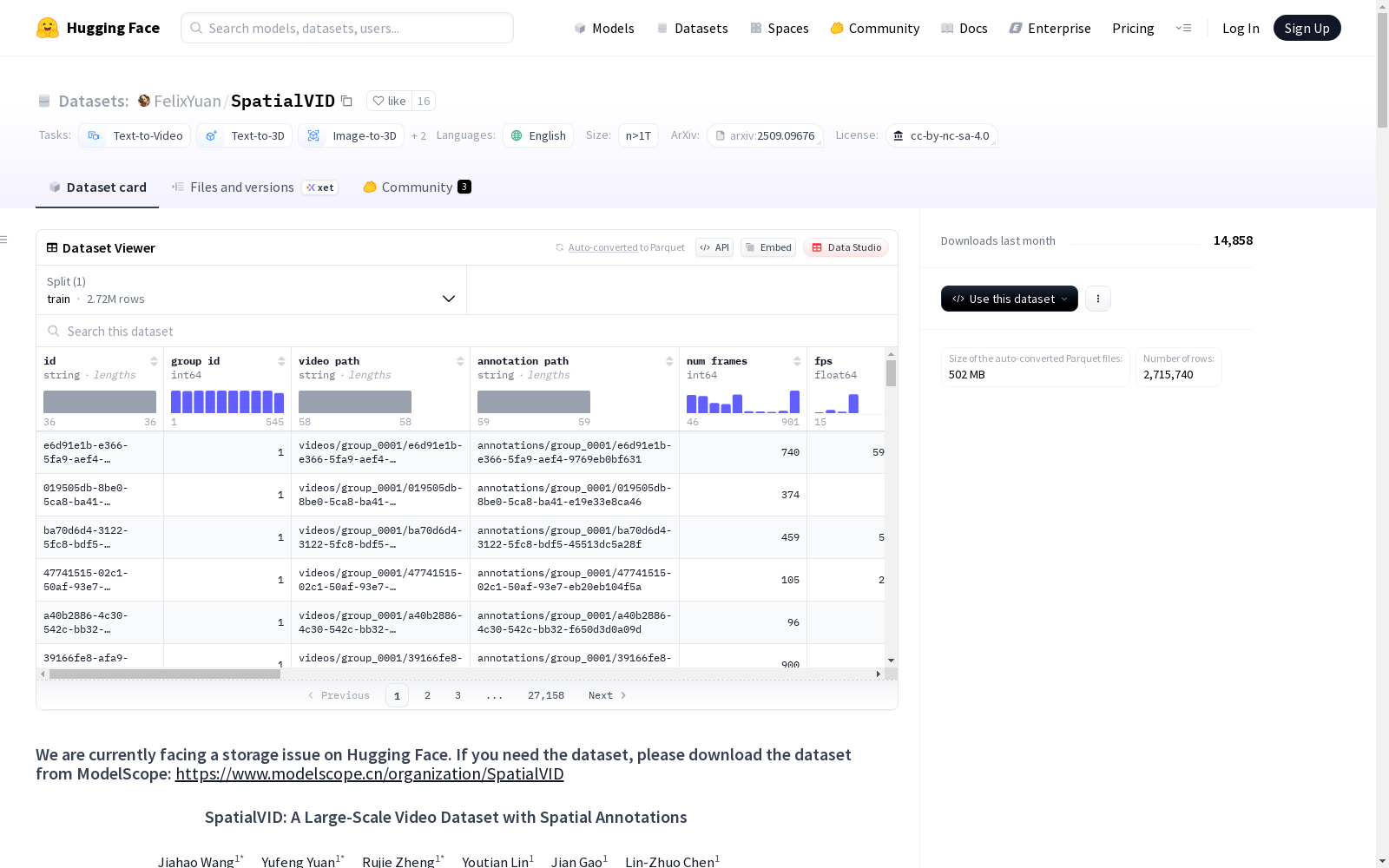
数据组织架构
数据集按545个分组组织,每组包含约14GB视频数据和1.5GB标注数据。目录结构分为:
annotations/:标注文件目录data/:元数据文件目录videos/:视频文件目录
核心特征
元数据字段
- 视频标识符(id、group id)
- 文件路径(video path、annotation path)
- 视频特性(num frames、fps、resolution)
- 质量评分(aesthetic score、luminance score、motion score、ocr score)
- 运动参数(moveDist、distLevel、rotAngle、trajTurns、dynamicRatio)
- 场景属性(motionTags、sceneType、brightness、timeOfDay、weather、crowdDensity)
标注文件类型
caption.json:结构化视频描述文本dyn_masks.npz:动态区域掩码intrinsics.npy:相机内参矩阵poses.npy:相机位姿数据instructions.json:帧间运动指令
下载信息
- 主下载地址:https://www.modelscope.cn/organization/SpatialVID
- 备用地址:https://huggingface.co/datasets/FelixYuan/SpatialVID
- 下载命令:
hf download SpatialVID/SpatialVID --repo-type dataset
使用说明
- 标注帧按
int(fps/5)间隔提取 - 提供Python工具脚本用于数据处理
- 支持pandas进行元数据过滤和分析
相关资源
- 项目页面:https://nju-3dv.github.io/projects/SpatialVID/
- 论文地址:https://arxiv.org/abs/2509.09676
- 代码仓库:https://github.com/NJU-3DV/spatialVID
- 工具脚本:https://github.com/NJU-3DV/SpatialVID/blob/main/utils/
搜集汇总
数据集介绍
构建方式
SpatialVID数据集通过系统性采集与标注流程构建,涵盖545个视频组别,每个组包含约14GB视频数据与1.5GB标注数据。采用间隔帧采样策略,以每秒五分之一帧率提取关键帧,并配套生成动态掩膜、相机内参、位姿矩阵及结构化文本描述。所有标注数据通过标准化流程处理,确保空间参数与视觉内容的精确对齐。
特点
该数据集核心特征在于融合多模态空间注释,包含动态目标分割掩膜、标准化相机内参、以米为单位的位姿数据及沉浸式文本描述。其10TB规模涵盖多样化场景类型、光照条件与运动模式,每个视频均配备美学评分、运动强度标签及动态比例指标,为三维视觉任务提供丰富上下文信息。
使用方法
用户可通过元数据文件快速筛选符合需求的视频片段,利用标注文件夹内的NPZ和JSON文件加载空间参数。动态掩膜需通过专用解压工具处理,相机参数可转换为像素坐标体系。研究者可结合位姿数据与运动指令重建摄像机轨迹,或利用文本描述训练跨模态生成模型。
背景与挑战
背景概述
SpatialVID作为南京大学与中国科学院自动化研究所联合研制的大规模空间标注视频数据集,诞生于2025年计算机视觉领域对多模态学习需求日益增长的背景之下。该数据集由Jiahao Wang、Yufeng Yuan等学者主导构建,核心目标在于解决动态场景理解、相机运动建模与三维空间推理的复合性问题。其创新性地融合了文本-视频-三维的跨模态标注体系,通过十万余段高清视频及其对应的空间参数标注,为神经渲染、动态场景重建与生成式视频模型提供了关键数据支撑,显著推动了视觉与几何学习领域的交叉研究进展。
当前挑战
在领域问题层面,SpatialVID致力于攻克动态场景中运动解耦与空间感知的复杂性挑战,具体包括移动目标与静态背景的分离、相机位姿的精确估计以及多视角几何一致性保持等核心难题。构建过程中面临标注规模与精度的双重压力:需处理超过10TB原始视频数据,并保证每段视频的动态掩码、相机内参及位姿轨迹的标注可靠性;同时,为解决标注一致性难题,研究团队开发了自动化标注流水线与人工校验相结合的多级质量控制机制,以确保大规模数据下的标注精度与时空连贯性。
常用场景
经典使用场景
在三维视觉与动态场景理解领域,SpatialVID数据集通过提供大规模视频序列及其空间标注信息,成为多视图几何重建与神经辐射场研究的基准数据源。其丰富的相机运动轨迹、动态掩码和标准化内参数据,支持从单目视频中恢复三维场景结构,并精确分离静态背景与动态物体,为计算机视觉算法提供了真实世界的复杂测试环境。
实际应用
在工业应用中,SpatialVID支持自动驾驶系统进行高精度环境感知与轨迹预测,其动态掩码可用于车辆和行人的运动行为分析。影视制作领域可借助其相机运动指令数据实现虚拟摄像机的智能控制,而AR/VR行业则利用其三维重建能力构建沉浸式交互环境,显著提升虚拟内容的真实感和空间一致性。
衍生相关工作
基于该数据集衍生的经典工作包括动态神经辐射场(NeRF)的改进模型,如DynNeRF和NSFF,它们利用动态掩码实现运动物体的分离建模。在视觉语言模型领域,其丰富的文本描述推动了Video-LLM在场景理解方面的发展,同时为Panoptic-SLAM等融合语义与几何的算法提供了验证基础。
以上内容由遇见数据集搜集并总结生成


