CVDN
收藏cvdn.dev2025-03-21 收录
下载链接:
https://cvdn.dev/
下载链接
链接失效反馈官方服务:
资源简介:
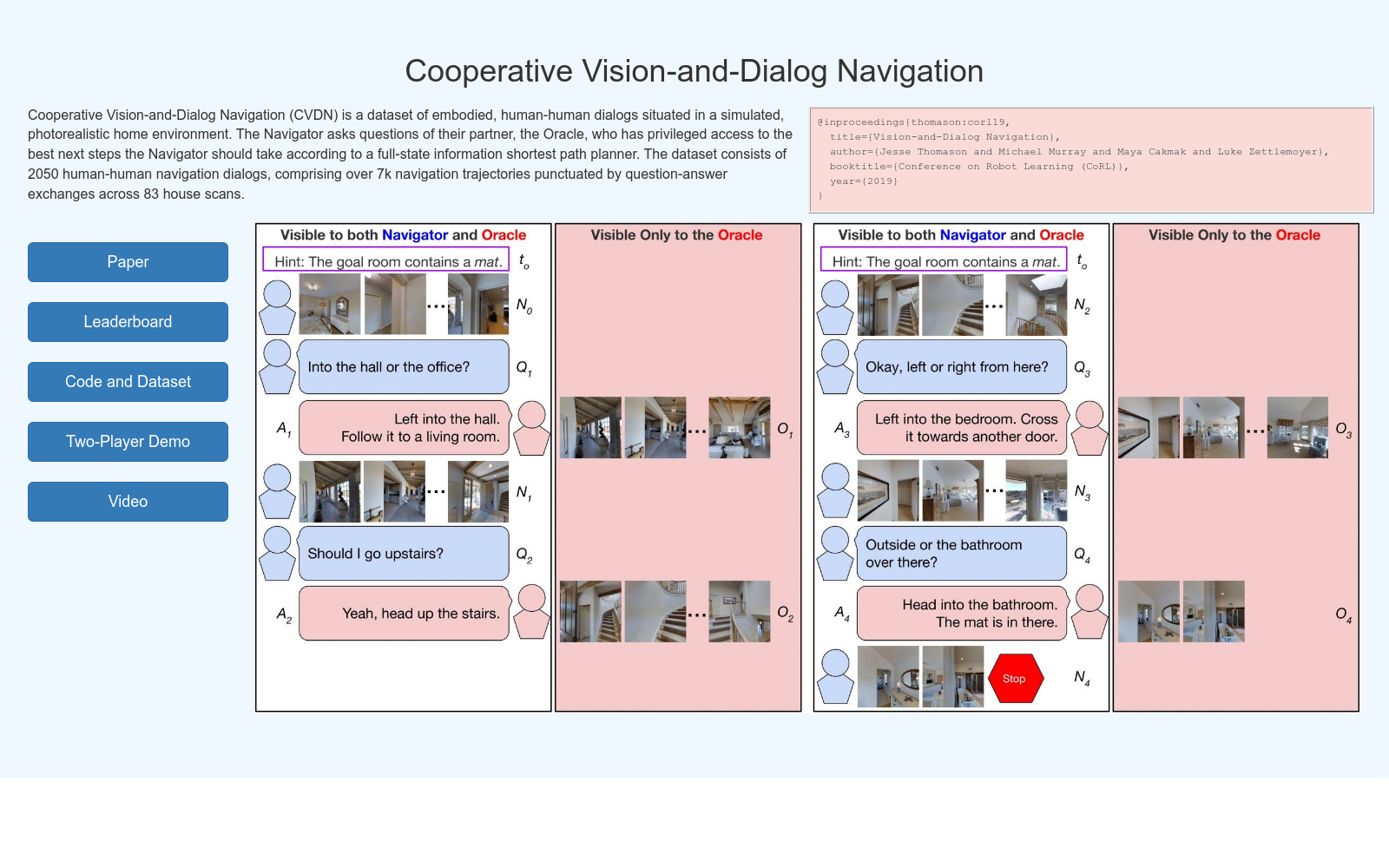
Cooperative Vision-and-Dialog Navigation(CVDN)数据集由华盛顿大学计算机科学与工程学院的研究团队创建,旨在推动机器人在人类环境中通过自然语言交互进行导航的研究。该数据集包含超过2000段在模拟的逼真家居环境中进行的人类对话,这些对话涉及导航任务,其中一位参与者(导航者)需要找到目标位置,而另一位参与者(先知)则提供帮助。数据集内容丰富,包含超过7000条导航轨迹,平均每段对话包含约6轮问答,总词数超过16万。数据集的创建基于Matterport Room-2-Room(R2R)模拟环境,通过众包方式收集人类对话,对话内容涉及从模糊的初始指令出发,通过问答逐步明确导航路径。CVDN数据集的应用领域广泛,可用于训练能够理解自然语言指令并进行导航的机器人,也可用于开发为人类在不熟悉环境中提供语言导航指导的系统。
The Cooperative Vision-and-Dialog Navigation (CVDN) dataset was created by a research team from the Department of Computer Science and Engineering, University of Washington, with the goal of advancing research on robot navigation via natural language interaction in human-centric environments. This dataset includes over 2,000 human dialogues conducted in simulated photorealistic home environments, all focused on navigation tasks: one participant, the navigator, needs to locate a target location, while the other, the oracle, provides assistance. It contains more than 7,000 navigation trajectories, with each dialogue averaging roughly 6 rounds of question-and-answer exchanges, and a total word count exceeding 160,000. The CVDN dataset is built upon the Matterport Room-2-Room (R2R) simulated environment, and human dialogues were collected through crowdsourcing, with the content involving gradually clarifying navigation paths via question-and-answer interactions starting from vague initial instructions. The CVDN dataset has a wide range of application scenarios: it can be used to train robots capable of understanding natural language instructions and performing navigation tasks, as well as to develop systems that provide verbal navigation guidance for humans in unfamiliar environments.
提供机构:
华盛顿大学计算机科学与工程学院
搜集汇总
数据集介绍
背景与挑战
背景概述
CVDN是一个包含2050个人类对话的视觉与对话导航数据集,基于83个房屋的模拟环境,包含超过7000个导航轨迹和问答交互,用于研究协作导航任务。
以上内容由遇见数据集搜集并总结生成


