conon-biblical-am-en
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/Nexuss0781/conon-biblical-am-en
下载链接
链接失效反馈官方服务:
资源简介:
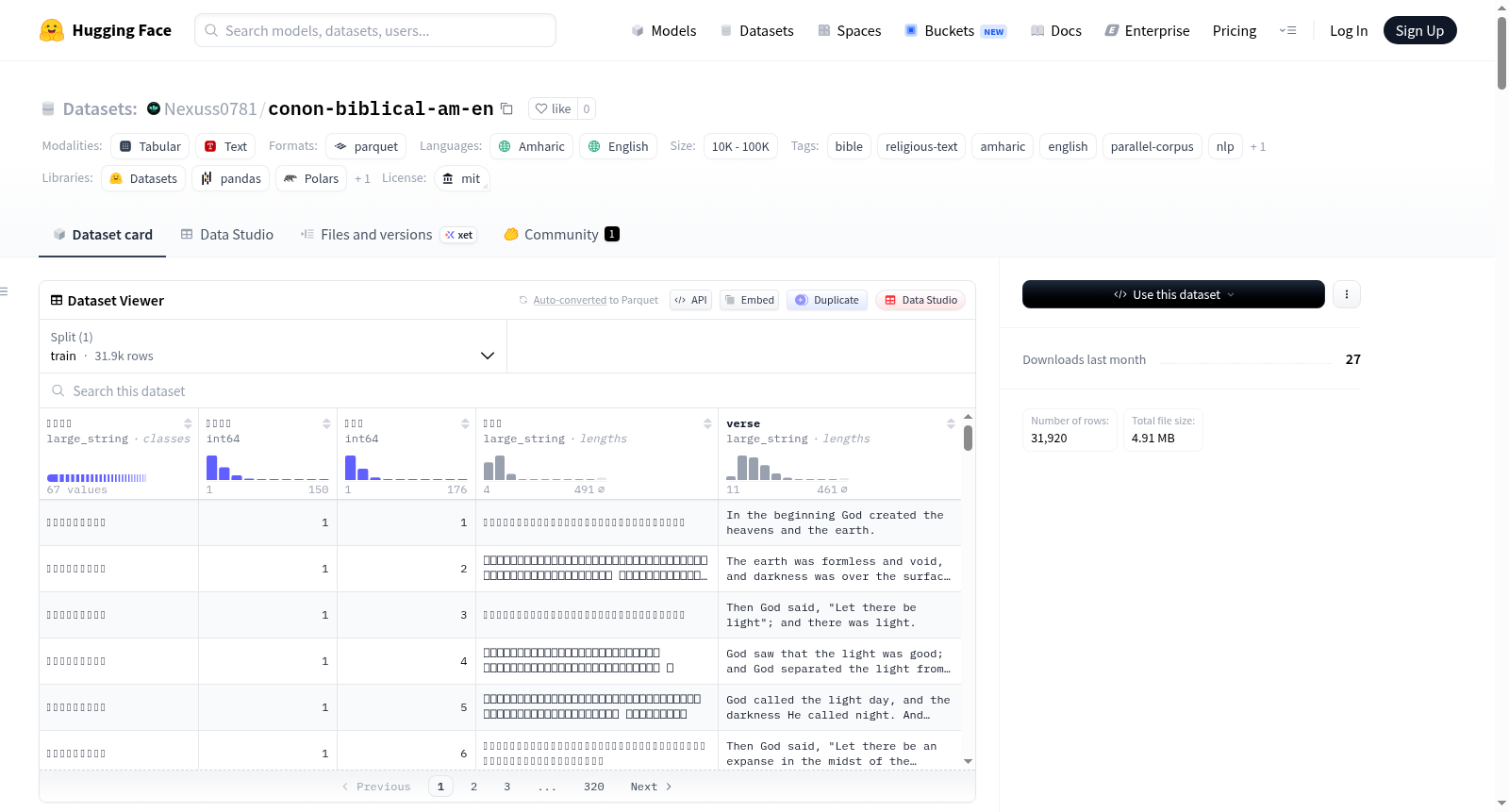
该数据集提供了一个全面的、统一的阿姆哈拉语和英语圣经平行语料库,专为自然语言处理(NLP)任务设计,包括机器翻译、跨语言信息检索和圣经语言学研究。数据集将阿姆哈拉语文本与英语新美国标准圣经(NASB)在经文级别对齐。数据集包含31,920行,涵盖67本圣经正典书籍。其关键特点包括经文级别的平行对齐、高保真度(保留阿姆哈拉语圣经的独特结构)以及处理版本间经文不匹配的鲁棒模式(用`null`值表示缺失的经文)。数据集采用Parquet格式,包含阿姆哈拉语的书名、章节号、经文号和经文内容,以及英语的经文内容。适用于机器翻译、文本生成和文本分类等任务。
创建时间:
2026-04-25
原始信息汇总
Canon Biblical Amharic-English Dataset 数据集详情
数据集概述
该数据集提供了一个阿姆哈拉语-英语双语平行语料库,内容为《圣经》全文,按节级别进行对齐。数据集包含 31,920 行数据,覆盖 67 卷书。阿姆哈拉语文本与英语 新美国标准圣经 (NASB) 版本对齐。
语言与任务
- 语言: 阿姆哈拉语 (am)、英语 (en)
- 任务: 文本分类、翻译、文本生成
- 许可证: MIT
数据来源与哲学
- 来源版本: 阿姆哈拉语圣经 和 新美国标准圣经 (NASB)。
- NASB 选择理由: 因其逐字准确的翻译哲学而被选中,强调对原始希伯来语、阿拉姆语和希腊语文本的直译。
- 节不匹配: 由于版本差异,阿姆哈拉语和英语的节可能偶尔不匹配,这是跨版本圣经对齐的已知特征。
圣经正典覆盖范围
该数据集主要关注埃塞俄比亚正统台瓦西多教会正典。在81卷书正典中,本数据集覆盖了67卷。以下为正典检查摘要:
- 旧约 (ብሉይ፡ኪዳን): 包含创世纪至玛拉基书,共40卷,全部收录 (✅)。
- 次经 (የቀኖና፡መጻሕፍት): 包含以斯拉续篇上、以斯拉续篇下、多比传、犹滴传、以斯帖记 (正典)、玛喀比传上卷、玛喀比传下卷,共7卷,全部缺失 (❌)。
- 新约 (ሐዲስ፡ኪዳን): 包含马太福音至启示录,共27卷,全部收录 (✅)。
数据结构
数据集以 Parquet 格式提供,包含以下列:
| 列名 | 描述 |
|---|---|
መጽሐፍ |
阿姆哈拉语书卷名称 |
ምዕራፍ |
章节号 |
ቁጥር |
节号 |
ጥቅስ |
阿姆哈拉语圣经文本 |
verse |
英语圣经文本 (NASB) |
节不匹配处理
当英语NASB版本比阿姆哈拉语版本包含更多节时,ጥቅስ (阿姆哈拉语) 列将为 null 值,而 verse (英语) 列保持填充。这确保了数据集的完整性。
技术审计结果
- 章节序列: 大多数书卷遵循完美的 1 到 N 序列。
- 特殊情况:
- ተግሣጽ (Tegsats): 遵循从第25章到第31章的特定序列。
- መዝሙረ፡ዳዊት (Psalms): 英语包含150章,阿姆哈拉语包含149章,已知差距已通过不匹配逻辑处理。
- 数据完整性: 包含的书卷中未发现主序列缺失章节。
未来路线图
后续数据集将专注于英语和阿姆哈拉语之间的跨语言理解,计划准备训练和SFT数据集,通过添加多样、高质量的数据来增强AI的准确性和对话能力。
使用方式
python from datasets import load_dataset
dataset = load_dataset("Nexuss0781/conon-biblical-am-en") data = dataset["train"]
引用
bibtex @misc{nexuss2024bible, author = {Nexuss0781}, title = {Canon Biblical Amharic-English Dataset}, year = {2024}, publisher = {Hugging Face}, journal = {Hugging Face Hub}, howpublished = {url{https://huggingface.co/datasets/Nexuss0781/conon-biblical-am-en}} }
搜集汇总
数据集介绍
构建方式
该数据集以阿姆哈拉语圣经与英文新美国标准圣经(NASB)为源文本,采用逐节对齐的策略构建成一个大规模平行语料库。针对两个版本间可能出现的诗节数量差异,数据集通过引入空值填充机制来妥善处理,确保了阿姆哈拉语文本完整性的同时,也保留了英文原典的完整性。数据集以Parquet格式存储,包含经卷名、章节号、诗节号、阿姆哈拉语文本和英文文本五个字段,总计31,920行数据,覆盖了67卷正典经书。
特点
该数据集最显著的特征在于其高度严谨的逐节对齐精度,尤其注重对埃塞俄比亚正统台瓦西多教会正典的忠实还原。数据集选用以字面准确性著称的NASB英文译本,并建立了稳健的格式塔来应对版本间的诗节失配问题,缺失部分以空值标注,从而兼顾了双语数据的完整性与一致性。此外,数据集还涵盖了包括《特格萨茨》等在内的独具特色的次经卷目,为跨语言圣经语言学研究提供了珍贵资源。
使用方法
研究人员可通过Hugging Face的datasets库直接加载该数据集,使用单行代码即可获取训练子集。该数据集适用于机器翻译、跨语言信息检索、文本分类乃至文本生成等多种自然语言处理任务。在实际应用中,模型需具备对两种语言的深层理解能力,以弥补版本间偶尔存在的诗节错位问题。未来,开发者计划在此基础上构建更侧重于跨语言理解与对话交互的监督微调(SFT)数据集,进一步提升模型的应用潜力。
背景与挑战
背景概述
该数据集名为Canon Biblical Amharic-English Dataset,由研究人员Nexuss0781于2024年创建,发布于HuggingFace平台。其核心目标是为自然语言处理领域提供一部全面且统一的阿姆哈拉语-英语圣经平行语料库,覆盖了埃塞俄比亚正统台瓦西多教会认可的81卷正典中的67卷,共计31,920条经节级别的对齐数据。该工作的深远意义在于,它不仅为机器翻译、跨语言信息检索和圣经语言学等下游任务提供了关键资源,更致力于推动低资源语言阿姆哈拉语的数字化进程与文化遗产保护。数据集选用以字面准确著称的NASB英文版本,并开创性地处理了不同版本间的经节数量差异问题,对宗教文本计算语言学领域产生了重要影响。
当前挑战
该数据集面临的首要挑战源于其领域问题,即不同圣经译本间存在的固有结构性差异。阿姆哈拉语圣经与英文NASB版本在章节划分和经节数量上并非完全一致,导致出现经文不匹配的情况,这为精确的平行语料对齐带来了根本性困难。其次,在构建过程中,由于仅覆盖了81卷正典中的67卷,仍有部分次经书卷缺失,构建完整的埃塞俄比亚正典语料库成为后续的重大挑战。此外,数据集采用AI提取逻辑,模型的自身理解能力会弥补翻译对齐中的局限,但这也意味着对AI模型的语言间语义关系理解提出了极高要求,且难以保证翻译质量的绝对精确,未来需通过更细粒度的跨语言理解数据和强化学习来提升性能。
常用场景
经典使用场景
该数据集最经典的使用场景在于构建阿姆哈拉语与英语之间的神经机器翻译系统。凭借其节级对齐的平行语料库,研究者能够训练端到端的序列到序列模型,实现两种语言在宗教文本语境下的精准互译。此外,它可作为跨语言信息检索的基准资源,用于评估模型在圣经文本中的语义对齐能力。同时,该数据集也为文本生成任务提供了丰富的语料,支持基于上下文的圣经经文续写或摘要生成等应用。
实际应用
在实际应用中,该数据集可赋能数字人文领域的圣经文本研究与文化遗产保护。基于此语料,可开发面向埃塞俄比亚东正教信徒的智能问答系统或圣经阅读辅助工具,实现双语经文检索、语义解释与多版本对比阅读。此外,它能够支持跨语言传教辅助系统的构建,帮助传教士或语言学习者快速理解阿姆哈拉语圣经内容,促进宗教文化的传播与交流。
衍生相关工作
该数据集衍生了多个重要的相关工作,其中最典型的是基于其精心构建的有监督微调数据集,用于训练能够回答圣经问题、检索经文并进行高精度翻译的对话式AI模型。这些衍生资源进一步拓展了原始语料的价值,通过引入指令微调范式,增强了模型在宗教文本领域的零样本泛化能力,并为后续开发更贴近用户交互风格的跨语言理解系统奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


