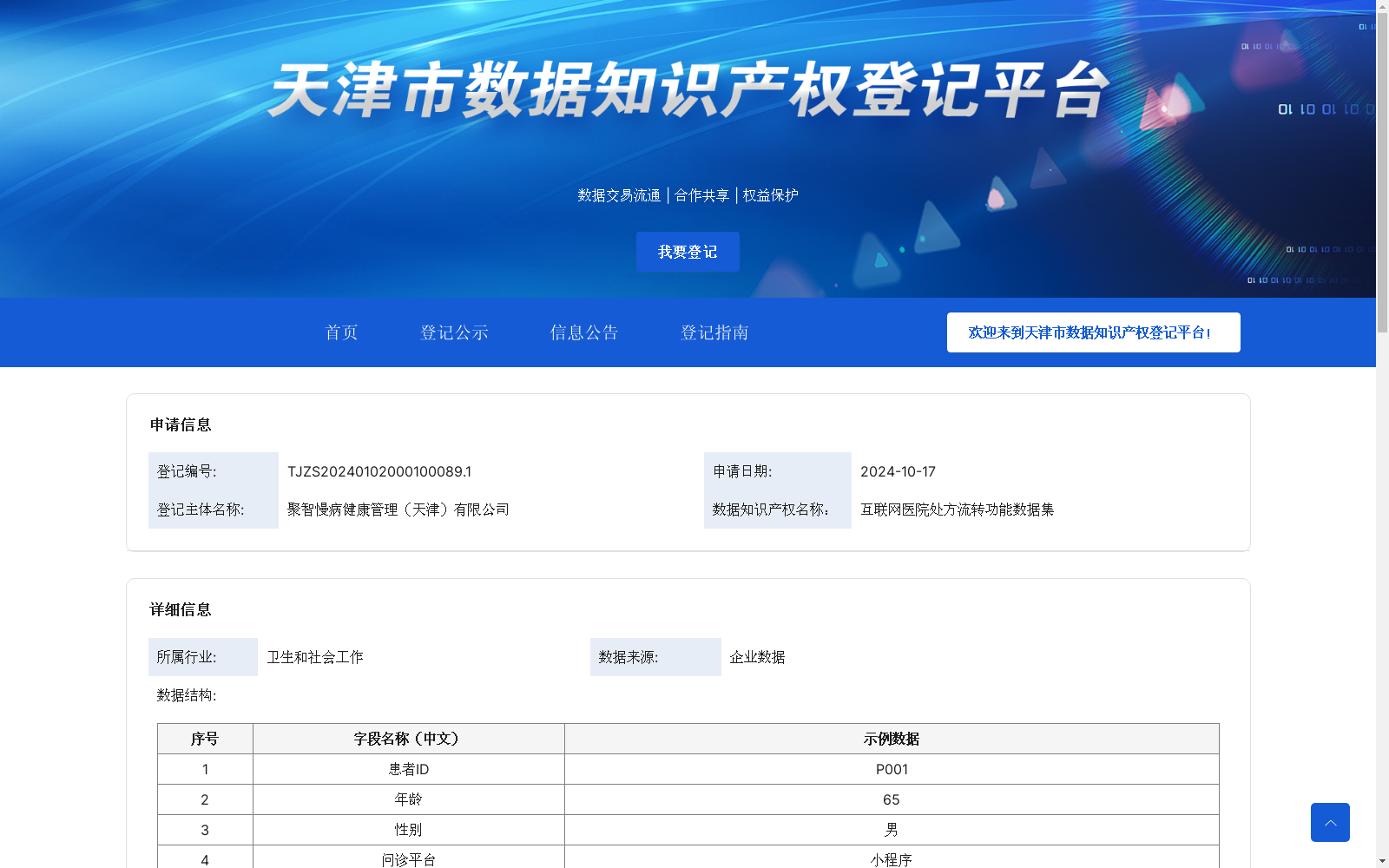
互联网医院处方流转功能数据集
收藏天津市数据知识产权登记平台2024-10-22 更新2024-11-05 收录
下载链接:
https://dengji.tjippc.cn/xxgg_nr?id=3ec06730-580a-4791-b741-f07f44538f2a
下载链接
链接失效反馈官方服务:
资源简介:
1. 数据采集与预处理算法
1.1 数据采集整合:
患者使用移动设备在线上医院进行线上问诊,第三方认证机构可以向患者提供一定的医生信息,以保证患者能够选择合适的医生进行问诊;
规则:
设备数据通过API接口定期自动上传到云平台。
每个患者的所有数据点都与其唯一的患者ID关联。
1.2 数据整理:
在医生对患者进行诊断后,患者通过输入身份证号识别在第三方认证机构进行身份认证,认证完成后,第三方认证机构会将患者的身份证明发送给医生,医生确认无误后对患者开具电子处方;
算法:
1.2.1缺失值处理:使用线性插值法填补时间序列中的小规模缺失数据;对于大规模缺失,则标记为不可用数据。
1.2.2异常值处理:运用3a原则进行检测,或基于历史数据的上下限范围设定合理的阈值。异常值可通过历史均值替换或删除。
1.3 数据流转:
在医生对患者开具电子处方后,医生需要将电子处方发送给处方流转平台,使处方被登记在处方流转平台,药师登入处方流转平台对处方进行审核;
1.4 数据存储
在审核完成后,将处方单推送至患者,患者根据需求选择药物配送方式。
2. 就诊流程算法
1用户通过手机号进行注册,注册成功后登录医院微信小程序,同时录入身份证号;
2医生根据系统中已经存在的患者信息,对选择健康管理服务的患者进行管理;
3患者数据匹配:将系统中存在就诊数据的患者根据身份证号进行匹配,存在院内就诊记录、住院记录、互联网医院就诊记录、和患者自行上传的院外就诊记录则在系统中的医院端和患者端进行展示;
4健康监测数据管理:患者可以选择自行录入血压、血糖等监测数据,也可由医生进行录入,录入的数据存在异常时,医生可通过短信和微信的方式提醒患者;
5随访管理:系统自动对医生设置的需要进行随访的患者进行提醒,医生选择随访管理,对所有本人需要管理的随访患者进行查询和随访操作;
6问卷管理:在随访过程中,如需及时了解患者情况,除了电话、门诊等方式进行沟通外,也可创建问卷推送给患者,患者填写完成后方便医生对患者的健康情况进行了解;
7健康管理系统负责对平台上的每个阶段产生的每个阶段的数据进行数据比对和分析。
3. 处方生成算法
3.1 处方生成:
根据患者的就诊数据,结合其慢性病类型,生成处方。
算法:
一、对用户信息库进行聚类操作,确定与患者身体素质相似的一类用户;
二、根据一的聚类结果结合历史处方进行本次处方的计算,得出与患者相似用户的处方集;
三、根据用户的疾病史对二中的运动项目集进行过滤筛选,得到新的处方集;
四、对三的得出的处方对应用户的身体情况,选出患者治疗效果最优的处方,则为最终确定的处方;
五、根据用户的基础信息经过计算确定患者的处方;
六、根据从四得到的处方确定药品的范围,以及用药周期;
七、完成就诊处方的生成。
1. Data Collection and Preprocessing Algorithms
1.1 Data Collection and Integration:
Patients conduct online consultations on online hospitals via mobile devices. Third-party certification institutions can provide patients with relevant doctor information to ensure that patients can select suitable doctors for consultations;
Rules:
Device data is automatically uploaded to the cloud platform at regular intervals via API interfaces.
All data points of each patient are associated with their unique patient ID.
1.2 Data Organization:
After the doctor diagnoses the patient, the patient undergoes identity authentication at the third-party certification institution by entering their ID number. After the authentication is completed, the third-party certification institution will send the patient's identity proof to the doctor. After confirming the correctness, the doctor will issue an electronic prescription to the patient;
Algorithms:
1.2.1 Missing Value Handling: Linear interpolation is used to fill small-scale missing data in time series; for large-scale missing data, they are marked as unavailable data.
1.2.2 Outlier Handling: The 3a principle is used for detection, or reasonable thresholds are set based on the upper and lower limits of historical data. Outliers can be replaced by historical mean values or deleted.
1.3 Data Flow:
After the doctor issues the electronic prescription to the patient, the doctor needs to send the electronic prescription to the prescription circulation platform so that the prescription is registered on the platform. Pharmacists log in to the prescription circulation platform to review the prescription;
1.4 Data Storage:
After the review is completed, the prescription slip is pushed to the patient, and the patient selects the drug delivery method according to their needs.
2. Consultation Process Algorithms
2.1 Users register via their phone numbers, log in to the hospital's WeChat Mini Program after successful registration, and enter their ID numbers at the same time;
2.2 Doctors manage patients who have selected health management services based on the existing patient information in the system;
2.3 Patient Data Matching: Patients with existing medical records in the system are matched according to their ID numbers. In-hospital medical records, hospitalization records, internet hospital consultation records, and out-of-hospital medical records uploaded by patients themselves will be displayed on both the hospital end and the patient end of the system;
2.4 Health Monitoring Data Management: Patients can choose to manually enter monitoring data such as blood pressure and blood glucose, or doctors can enter the data. If the entered data is abnormal, doctors can remind patients via SMS and WeChat;
2.5 Follow-up Management: The system automatically reminds patients who need follow-up as set by the doctor. Doctors select follow-up management to query and perform follow-up operations on all follow-up patients under their management;
2.6 Questionnaire Management: During follow-up, if doctors need to understand the patient's situation in a timely manner, in addition to communication via phone, outpatient service and other methods, questionnaires can also be created and pushed to patients. After the patients fill out the questionnaires, doctors can conveniently understand the patients' health conditions;
2.7 Health Management System Data Analysis: The health management system is responsible for data comparison and analysis of data generated at each stage on the platform.
3. Prescription Generation Algorithms
3.1 Prescription Generation:
Prescriptions are generated based on the patient's consultation data and their chronic disease types.
Algorithms:
1. Perform clustering operations on the user information database to identify a group of users with similar physical qualities to the patient;
2. Calculate the current prescription based on the clustering results from step 1 combined with historical prescriptions, and obtain the prescription set of users similar to the patient;
3. Filter and screen the exercise item set from step 2 based on the user's disease history to obtain a new prescription set;
4. Select the prescription with the optimal therapeutic effect for the patient based on the user's physical condition corresponding to the prescriptions obtained in step 3, which is the final confirmed prescription;
5. Determine the patient's prescription through calculation based on the user's basic information;
6. Determine the scope of medications and the medication cycle based on the prescription obtained in step 4;
7. Complete the generation of the consultation prescription.
提供机构:
聚智慢病健康管理(天津)有限公司
创建时间:
2024-10-17
搜集汇总
数据集介绍
特点
互联网医院处方流转功能数据集包含63条患者健康记录,每月更新,涵盖基本信息、健康指标和电子处方等,用于居家线上就诊和健康管理,解决传统医疗资源分配不均等问题。
以上内容由遇见数据集搜集并总结生成


