xlangai/DS-1000
收藏Hugging Face2024-09-19 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/xlangai/DS-1000
下载链接
链接失效反馈资源简介:
DS-1000数据集是一个专注于代码生成任务的数据集,使用cc-by-sa-4.0许可证。该数据集的语言为代码,主要应用于文本到文本生成的任务,特别是代码生成。数据集提供了一个简化的格式,并鼓励用户通过提供的链接查看排行榜和更多信息。
The DS-1000 dataset is focused on code generation tasks and is licensed under cc-by-sa-4.0. The language of the dataset is code, and it is primarily used for text-to-text generation tasks, specifically code generation. The dataset offers a simplified format and encourages users to view the leaderboard and more information through the provided links.
提供机构:
xlangai
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-sa-4.0
- 语言: code
- 任务类别: text2text-generation
- 标签: code-generation
- 美观名称: DS-1000
其他信息
- 重格式化贡献者: Yuhang Lai, Sida Wang
搜集汇总
数据集介绍
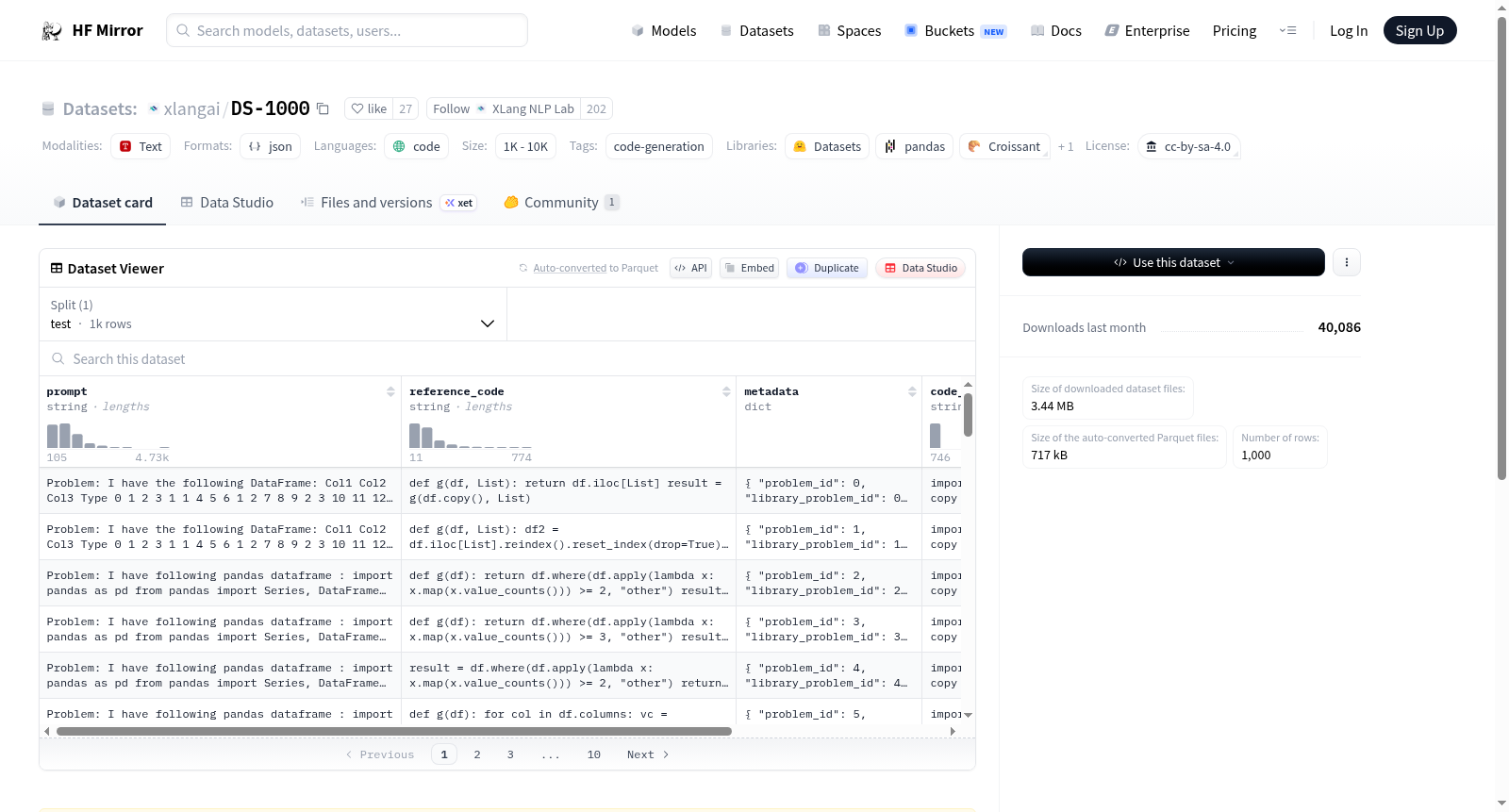
构建方式
在代码生成领域,DS-1000数据集的构建体现了严谨的工程化流程。该数据集源自原始DS-1000项目,经过重新格式化处理,以简化格式呈现,便于研究者直接使用。构建过程中,团队将原始数据转换为适合文本到文本生成任务的格式,同时保留了代码生成的核心挑战。这一过程确保了数据的一致性与可访问性,为后续评估提供了可靠基础。
特点
DS-1000数据集的特点在于其专注于代码生成任务,涵盖了多种编程语言与场景。数据集以简洁格式组织,支持高效的模型训练与评估,并集成了Eval-Arena排行榜功能,便于性能比较。其标签明确指向代码生成领域,使得研究者能够快速定位与应用,体现了专业数据集的实用性与前沿性。
使用方法
使用DS-1000数据集时,研究者可通过HuggingFace平台直接加载简化格式的数据,进行代码生成模型的训练或测试。建议参考项目页面获取详细测试代码与排行榜信息,并结合原始仓库探索更多格式选项。数据集适用于文本到文本生成任务,用户可依据需求调整预处理流程,以最大化其科研价值。
背景与挑战
背景概述
在人工智能与软件工程交叉领域,代码生成任务日益受到重视,旨在通过自然语言描述自动生成可执行代码。DS-1000数据集由xlang-ai团队于2022年推出,其核心研究问题聚焦于评估大型语言模型在数据科学编程环境中的实际代码生成能力。该数据集涵盖了Python库如NumPy和Pandas的多样化编程问题,为衡量模型在真实场景下的泛化性与准确性提供了标准化基准,显著推动了代码智能领域的研究进展与模型评估的严谨性。
当前挑战
DS-1000数据集所针对的领域挑战在于数据科学代码生成的高度复杂性,要求模型不仅理解自然语言指令,还需掌握特定库的语法语义及上下文依赖,以生成功能正确且高效的代码。在构建过程中,挑战包括从实际数据科学竞赛和教程中筛选高质量问题,确保覆盖广泛的应用场景,同时维护代码片段的可执行性与评估的公平性,避免偏差并适应快速演变的编程实践。
常用场景
经典使用场景
在代码生成领域,DS-1000数据集常被用于评估大型语言模型在解决实际编程问题上的能力。该数据集覆盖了Python、SQL、Java等多种编程语言,通过提供多样化的编程任务,如代码补全、错误修复和算法实现,为研究者提供了一个标准化的测试平台。模型在这些任务上的表现能够直观反映其理解代码逻辑、遵循编程规范以及生成高效解决方案的综合水平,从而推动代码智能技术的进步。
实际应用
在实际应用中,DS-1000数据集被广泛用于开发智能编程助手和自动化代码生成工具。这些工具能够辅助开发者快速完成代码编写、调试和优化,提升软件开发的效率和质量。例如,在集成开发环境中,基于该数据集训练的模型可以实时提供代码建议或自动生成复杂函数,减少人工编码错误。此外,它还可用于教育领域,帮助学生通过实践练习掌握编程技能,推动编程教育的普及和创新。
衍生相关工作
围绕DS-1000数据集,衍生了一系列经典研究工作,包括基于该基准的模型性能评估框架和代码生成算法的改进。许多研究团队利用该数据集进行了深入的实验分析,提出了针对代码语义理解和生成效率的优化方法。这些工作不仅推动了如Codex、AlphaCode等先进模型的发展,还促进了代码生成与其他自然语言处理任务的融合,为构建更智能、更通用的编程系统奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


