【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
namextend
收藏Hugging Face2025-01-31 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/aieng-lab/namextend
下载链接
链接失效反馈官方服务:
资源简介:
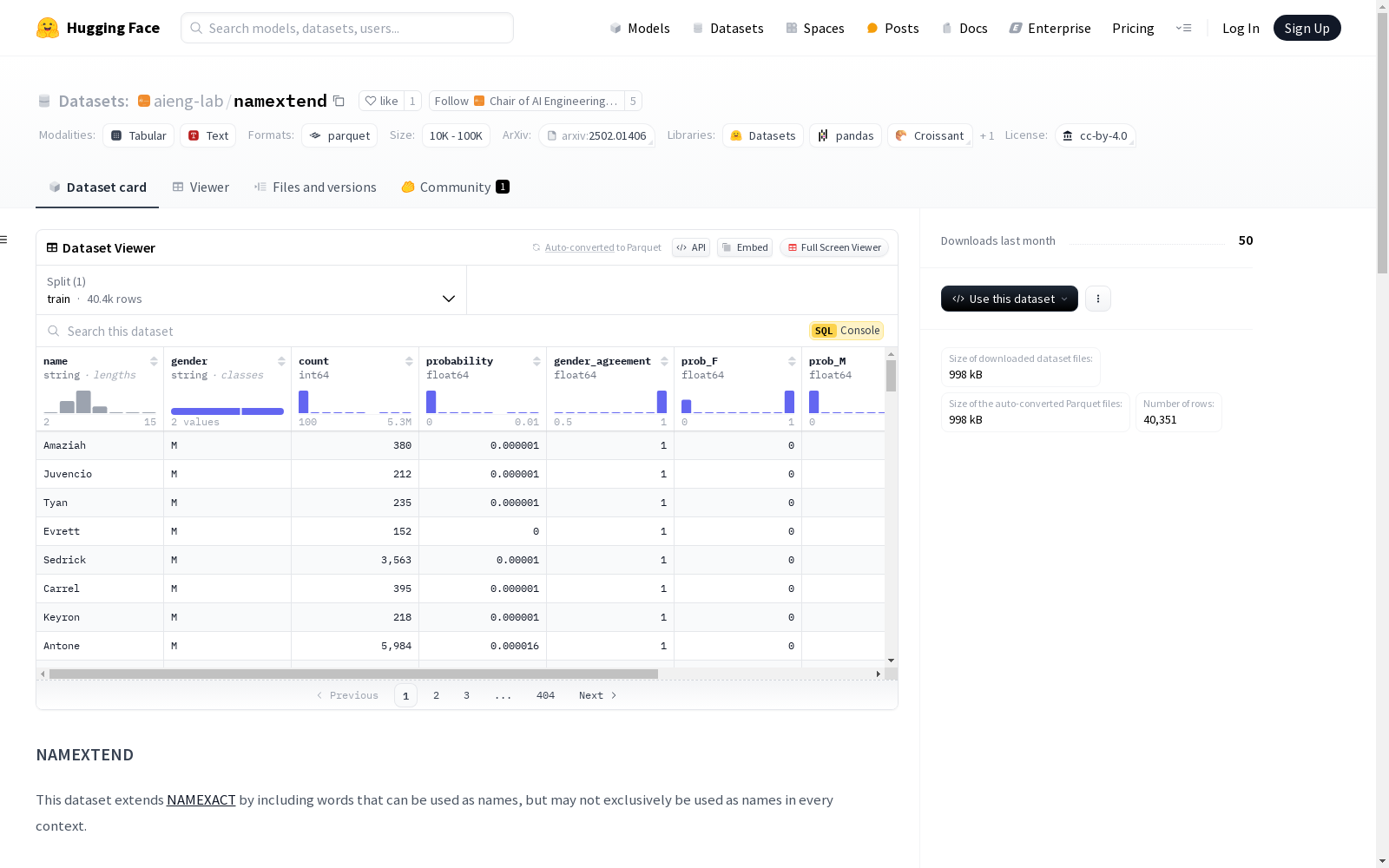
NAMEXTEND数据集是对NAMEXACT数据集的扩展,包含了可以用作名字的词汇,但这些词汇在其他上下文中也可能有不同用途。例如,'Christian'可以指基督教信徒,'Drew'是动词'draw'的过去式,'Florence'是意大利的一个城市,'Henry'是电感的SI单位,'Mercedes'是一个汽车品牌。此外,数据集还包含了性别模糊的名字,每个性别都单独列出。例如,'Skyler'作为女性名字的概率为37.3%,作为男性名字的概率为62.7%。数据集的结构包括名字、性别、计数、概率、性别一致性、主要性别、性别标签、女性名字概率和男性名字概率等字段。数据来源于'Gender by Name'数据集,并经过过滤处理,只保留了计数至少为100的名字。
创建时间:
2025-01-28
搜集汇总
数据集介绍
构建方式
namextend数据集的构建主要通过筛选原始的Gender by Name数据集,保留至少计数次数大于100的名称,以排除使用频率极低的名称。此数据集不仅包含通常用作名称的单词,还包括可能在其他上下文中使用的单词,以及具有模糊性别的名称。每个名称根据其在不同性别中的使用概率进行分类,并计算性别一致性指标,以反映名称在性别归属上的确定性。
特点
namextend数据集的特点在于它扩展了namexact数据集,包含了更多可能在特定上下文中作为名称使用的单词,同时涵盖了具有性别模糊性的名称。数据集详细记录了每个名称的性别、计数、概率、性别一致性、主要性别标识以及男性和女性使用的概率。这些特性使其成为研究和应用性别预测、名称分类等领域的宝贵资源。
使用方法
使用namextend数据集时,用户可以依据数据集提供的名称、性别分布、概率等信息进行性别预测模型训练、自然语言处理任务中的实体识别等。数据集提供了训练 splits,可以直接用于机器学习模型的训练过程。用户应遵守cc-by-4.0许可证的规定,合理使用和分享数据集。
背景与挑战
背景概述
namextend数据集是在数据科学和自然语言处理领域中,针对姓名识别与性别分类任务的重要资源。该数据集由aieng-lab团队创建于2025年,是对namexact数据集的扩展,包含了更多在特定语境下可能作为名字使用的词汇。namextend不仅包含了常用作名字的词汇,还包括了性别模糊的名字,并为每个名字提供了性别概率。该数据集的构建旨在提高模型对姓名和性别之间复杂关系的理解能力,对于性别偏见减轻和性别分类研究具有显著影响。
当前挑战
namextend数据集在构建和应用过程中面临的挑战主要包括:如何准确地区分名字和普通词汇,尤其是在多义性较强的词汇中;如何处理性别分类的不确定性,特别是在性别模糊的名字上;以及如何确保数据集的广泛性和代表性,避免引入偏见。此外,数据集在收集和过滤过程中,对于名字出现频率的阈值设定,也可能导致数据集的局限性,影响模型的泛化能力。
常用场景
经典使用场景
namextend数据集在命名实体识别(NER)任务中具有显著的应用价值,特别是在处理性别相关的命名实体时,其提供的性别概率信息为模型训练提供了重要依据,使得模型能够更准确地识别和预测性别相关的命名实体。
实际应用
在实际应用中,namextend数据集可被用于改进在线身份验证系统,通过分析用户提供的名字,系统可以更准确地推断用户的性别,从而提升个性化推荐和用户体验。
衍生相关工作
基于namextend数据集,研究者们已经开展了一系列相关工作,包括性别预测模型的开发、性别去偏算法的设计以及性别歧视语言的检测等,这些研究为创建更加公平和包容的技术提供了基础。
以上内容由遇见数据集搜集并总结生成


