ConvLab/dailydialog
收藏Hugging Face2022-11-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ConvLab/dailydialog
下载链接
链接失效反馈官方服务:
资源简介:
DailyDialog是一个高质量的多轮对话数据集,其语言为人所写且噪声较少。数据集中的对话反映了我们的日常交流方式,并涵盖了日常生活的各种主题。我们还手动标注了数据集中的通信意图和情感信息。
DailyDialog is a high-quality multi-turn dialogue dataset with human-written utterances and minimal noise. The dialogues in this dataset reflect daily communication patterns and cover a wide range of topics in everyday life. We also manually annotated the communication intentions and emotional information contained in the dataset.
提供机构:
ConvLab
原始信息汇总
数据集概述:DailyDialog
基本信息
- 名称:DailyDialog
- 语言:英语
- 许可证:CC BY-NC-SA 4.0
- 多语言性:单语种
- 大小:10K<n<100K
- 任务类别:对话
数据集描述
- 概述:DailyDialog是一个高质量的多轮对话数据集,由人工编写,噪音较少。数据集中的对话反映了日常沟通方式,并涵盖了日常生活的多种话题。此外,数据集还手动标注了沟通意图和情感信息。
- 数据处理:
- 原始数据下载链接:ijcnlp_dailydialog.zip。
- 数据预处理步骤包括:使用
topic注释作为domain,将intent注释转换为binary对话行为,保留情感注释,使用nltk处理文本格式等。
- 注释类型:意图(intent)、情感(emotion)
支持的任务
- 自然语言理解(NLU)、自然语言生成(NLG)
数据分割
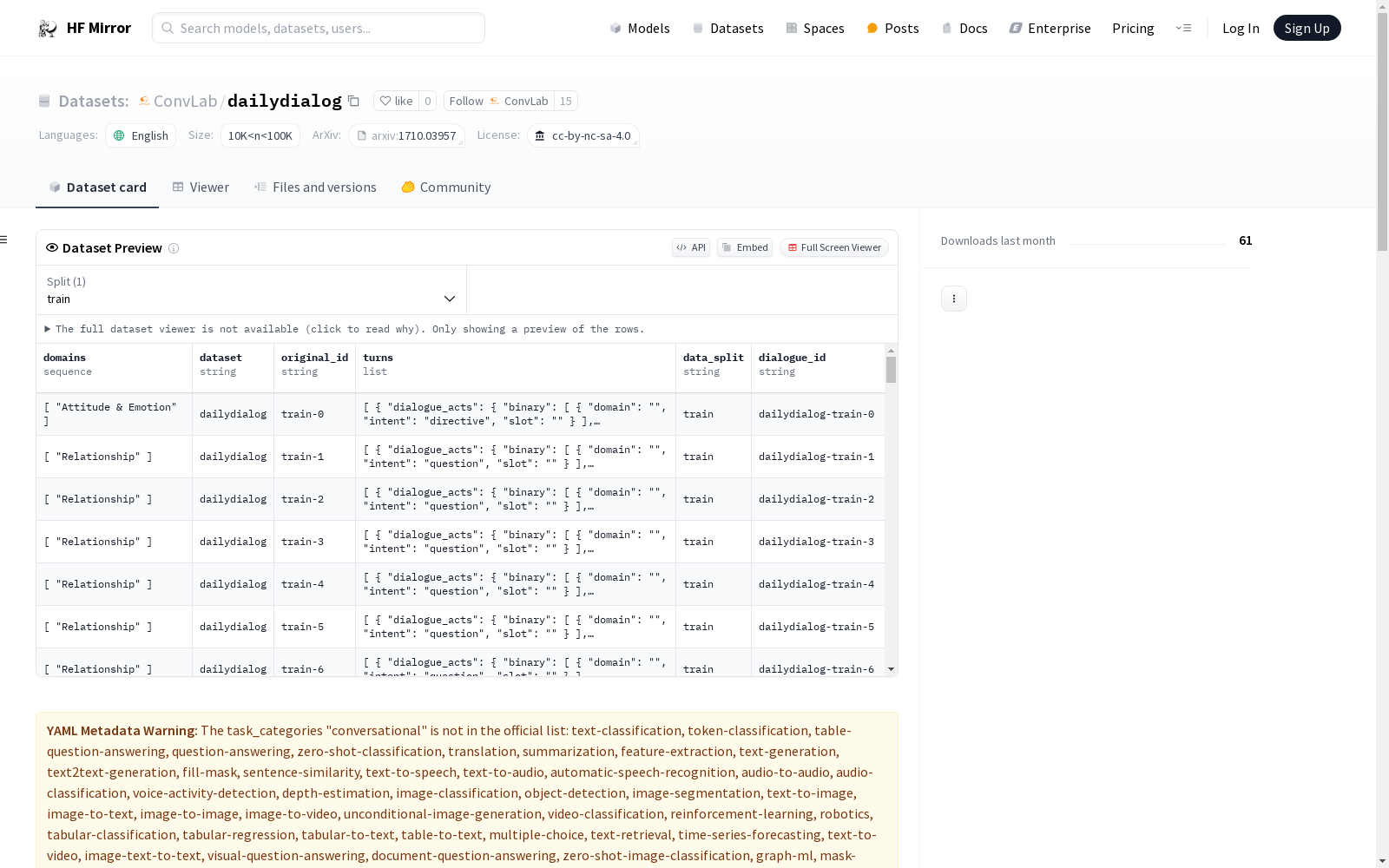
| 分割 | 对话数 | 话语数 | 平均话语数 | 平均令牌数 | 平均领域数 |
|---|---|---|---|---|---|
| 训练 | 11118 | 87170 | 7.84 | 11.22 | 1 |
| 验证 | 1000 | 8069 | 8.07 | 11.16 | 1 |
| 测试 | 1000 | 7740 | 7.74 | 11.36 | 1 |
| 全部 | 13118 | 102979 | 7.85 | 11.22 | 1 |
引用信息
@InProceedings{li2017dailydialog, author = {Li, Yanran and Su, Hui and Shen, Xiaoyu and Li, Wenjie and Cao, Ziqiang and Niu, Shuzi}, title = {DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset}, booktitle = {Proceedings of The 8th International Joint Conference on Natural Language Processing (IJCNLP 2017)}, year = {2017} }
许可证
- CC BY-NC-SA 4.0
以上是对DailyDialog数据集的概述,包括其基本信息、描述、支持的任务、数据分割以及引用和许可证信息。
搜集汇总
数据集介绍
构建方式
DailyDialog数据集的构建基于对日常对话的精心收集与标注。该数据集通过人工方式筛选和整理,确保对话内容的高质量和低噪声特性。对话涵盖了日常生活中的多个主题,如生活、教育、情感等,并进一步通过人工标注的方式,为每轮对话添加了沟通意图和情感信息。数据集的预处理步骤包括使用NLTK工具进行分词和去空格处理,以及对标点符号的规范化处理,确保数据的一致性和可用性。
特点
DailyDialog数据集的显著特点在于其高质量的多轮对话内容,这些对话不仅语言自然,且覆盖了广泛的日常话题。数据集中的每轮对话都经过人工标注,包含了沟通意图和情感信息,这为研究对话系统中的意图识别和情感分析提供了丰富的资源。此外,数据集的预处理步骤确保了文本的规范化,使得数据在不同任务中的应用更加便捷。
使用方法
使用DailyDialog数据集前,需先安装ConvLab-3平台。通过调用`load_dataset`、`load_ontology`和`load_database`函数,可以轻松加载数据集及其相关元数据。数据集支持多种自然语言处理任务,如自然语言理解(NLU)和自然语言生成(NLG)。用户可以根据需要选择不同的数据分割(如训练集、验证集和测试集),并利用数据集中的标注信息进行模型训练和评估。
背景与挑战
背景概述
DailyDialog数据集是由Li等人于2017年创建的高质量多轮对话数据集,旨在为自然语言处理领域的对话系统研究提供丰富的资源。该数据集的语言为人工编写,噪声较少,涵盖了日常生活中的多种话题,如日常生活、学校生活、文化教育等。研究人员还为数据集手动标注了交流意图和情感信息,使其在对话系统的意图识别和情感分析任务中具有重要应用价值。该数据集的发布为对话系统研究提供了新的基准,推动了多轮对话建模和情感理解技术的发展。
当前挑战
DailyDialog数据集在构建过程中面临多项挑战。首先,如何从大量日常对话中筛选出高质量、低噪声的对话样本是一个关键问题。其次,手动标注交流意图和情感信息需要大量的人力和时间,且标注的一致性和准确性难以保证。此外,数据集的多样性和覆盖范围也是一个挑战,确保对话内容涵盖广泛的主题和情境,以提高模型的泛化能力。在应用层面,如何有效利用标注信息进行意图识别和情感分析,以及如何处理多轮对话中的上下文依赖关系,也是该数据集面临的重要挑战。
常用场景
经典使用场景
DailyDialog数据集在多轮对话生成和理解任务中展现了其经典应用价值。该数据集通过丰富的多轮对话样本,涵盖日常生活中的多种话题,为自然语言处理(NLP)领域的研究者提供了高质量的对话数据资源。其标注的意图和情感信息,使得研究者能够在对话行为识别、情感分析等任务中进行深入探索,从而推动对话系统的智能化发展。
解决学术问题
DailyDialog数据集解决了多轮对话数据稀缺和标注不充分的问题,为学术界提供了丰富的对话样本和详细的标注信息。通过该数据集,研究者能够更好地研究对话系统中的意图识别、情感分析等关键问题,推动对话系统在自然语言理解和生成方面的技术进步,具有重要的学术研究意义。
衍生相关工作
基于DailyDialog数据集,研究者们开展了多项经典工作,包括对话行为识别、情感分析和多轮对话生成等。这些工作不仅推动了对话系统在自然语言处理领域的发展,还为后续研究提供了宝贵的经验和方法。例如,一些研究通过该数据集训练的模型在对话行为分类和情感识别任务中取得了显著的性能提升,进一步验证了该数据集在对话系统研究中的重要性。
以上内容由遇见数据集搜集并总结生成


