Zyda - 包含1.3万亿Token的开源预训练数据集
收藏Hugging Face2024-12-12 收录
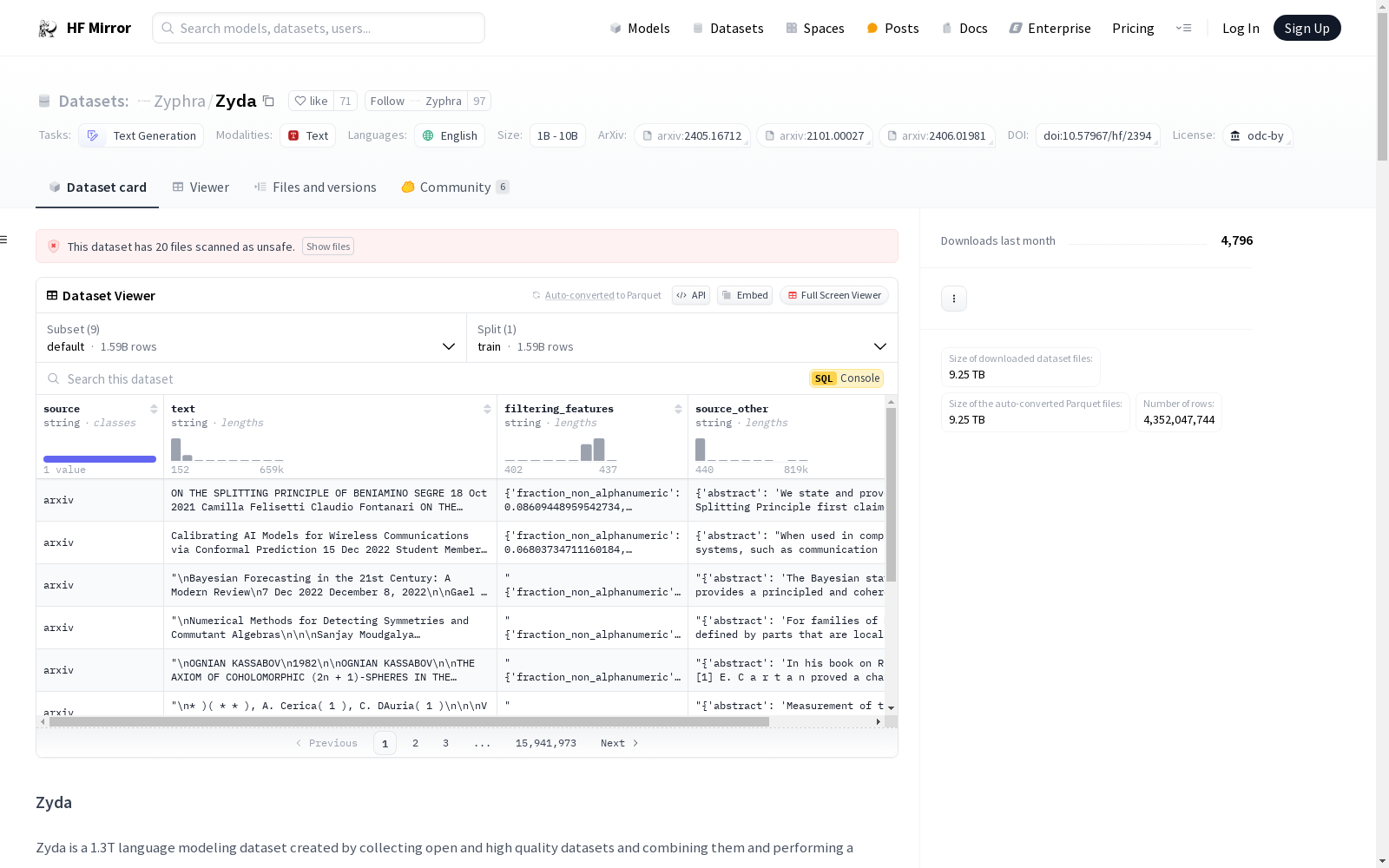
下载链接:
https://hf-mirror.com/datasets/Zyphra/Zyda
下载链接
链接失效反馈官方服务:
资源简介:
Zyda数据集是由Zyphra公司创建的一个大型语言模型预训练数据集。该数据集通过整合多个开源数据集并进行深度处理来构建,包含了1.3万亿Token,其质量接近商业语料。Zyda数据集的创建过程包括了严格的过滤和去重处理,以保持和提高从原始数据集中派生出的质量。实验结果表明,使用Zyda训练的语言模型在多项评估任务上,性能优于其他同类数据集,如Dolma、FineWeb和RefinedWeb。Zyda的发布为开源社区提供了一个高质量的、大规模的预训练语料库,为开源语言模型研究奠定数据基础。
The Zyda dataset is a large language model pre-training corpus developed by Zyphra Corporation. It is built by integrating multiple open-source datasets and undergoing in-depth processing, boasting a scale of 1.3 trillion Tokens and a quality comparable to commercial corpora. The creation process of the Zyda dataset incorporates strict filtering and deduplication operations to preserve and improve the quality of data derived from its original sources. Experimental results demonstrate that language models trained on the Zyda dataset outperform those trained on other similar datasets including Dolma, FineWeb, and RefinedWeb across a wide range of evaluation tasks. The release of the Zyda dataset offers the open-source community a high-quality, large-scale pre-training corpus, laying a solid data foundation for open-source language model research.
提供机构:
Zyphra
原始信息汇总
数据集概述
基本信息
- 数据集名称: Zyda
- 许可证: Open Data Commons License (ODC-BY)
- 任务类别: 文本生成
- 语言: 英语
- 大小类别: 大于1TB
数据集结构
- 配置名称: default
- 分割:
- 名称: train
- 样本数量: 1,594,197,267
配置详情
- 默认配置:
- 数据文件路径: data///*
- 其他配置:
- zyda_no_starcoder: data/zyda_no_starcoder//
- zyda_arxiv_only: data/zyda_no_starcoder/zyda_arxiv/*
- zyda_c4-en_only: data/zyda_no_starcoder/c4_en/*
- zyda_peS2o_only: data/zyda_no_starcoder/zyda_peS2o/*
- zyda_pile-uncopyrighted_only: data/zyda_no_starcoder/zyda_pile-uncopyrighted/*
- zyda_refinedweb_only: data/zyda_no_starcoder/zyda_refinedweb/*
- zyda_slimpajama_only: data/zyda_no_starcoder/zyda_slimpajama/*
- zyda_starcoder_only: data/zyda_starcoder//
数据集描述
- 数据集来源: 由七个高质量的开源数据集组成
- 数据字段:
text: 训练文本source: 文本来源filtering_features: 用于过滤的预计算特征值(转换为JSON字符串)source_other: 来源数据集的元数据(转换为JSON字符串)
数据收集和处理
- 处理步骤: 过滤和去重
- 过滤方法: 使用手工调整的过滤器,来源包括C4、RedPajama和Gopher等
- 去重方法: 使用minhash近似去重,基于13-gram和Jaccard相似度阈值0.4
数据集组件
| 组件 | 下载大小 (GB) | 文档数量 (百万) | 令牌数量 (十亿) |
|---|---|---|---|
| zyda_refinedweb_only | 1,712.4 | 920.5 | 564.8 |
| zyda_c4-en_only | 366.7 | 254.5 | 117.5 |
| zyda_slimpajama_only | 594.7 | 142.3 | 242.3 |
| zyda_pile-uncopyrighted_only | 189.4 | 64.9 | 82.9 |
| zyda_peS2o_only | 133.7 | 35.7 | 53.4 |
| zyda_arxiv_only | 8.3 | 0.3 | 4.7 |
| zyda_starcoder_only | 299.5 | 176.1 | 231.3 |
| 总计 | 3,304.7 | 1,594.2 | 1,296.7 |
许可证信息
- 许可证: Open Data Commons License (ODC-BY)
- 使用条款: 使用此数据集还需遵守原始数据源的许可证协议和使用条款
引用信息
@misc{tokpanov2024zyda, title={Zyda: A 1.3T Dataset for Open Language Modeling}, author={Yury Tokpanov and Beren Millidge and Paolo Glorioso and Jonathan Pilault and Adam Ibrahim and James Whittington and Quentin Anthony}, year={2024}, eprint={2406.01981}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
Zyda数据集的构建过程分为两个主要阶段:过滤和去重。在过滤阶段,研究团队采用了多种手工调整的过滤器,这些过滤器来源于C4、RedPajama和Gopher等数据集,并结合了自定义的过滤规则。在去重阶段,使用了基于13-gram的minhash近似去重方法,minhash签名大小为128,并过滤掉Jaccard相似度超过0.4的文档。这一精细的处理流程确保了数据集的高质量和多样性。
特点
Zyda数据集包含了1.3万亿个Token,主要来源于七个高质量的开源数据集,如Pile Uncopyrighted、C4-en、peS2o等。数据集经过严格的过滤和去重处理,确保了其内容的纯净性和多样性。Zyda在语言建模任务中表现出色,尤其是在1.4B模型上,经过50B Token训练后,其性能超越了Pile、Dolma、RefinedWeb和Fineweb等数据集。Zyda的非StarCoder版本在语言任务中表现尤为突出,成为当前最优秀的开源数据集之一。
使用方法
Zyda数据集可以通过Hugging Face的`datasets`库进行下载和使用。用户可以选择下载完整的数据集,也可以根据需要下载特定的子集,如`zyda_no_starcoder`、`zyda_arxiv_only`等。下载后,数据集可以直接用于语言模型的训练,支持从1T到多T级别的模型训练。此外,Zyda还可以与其他数据集如Fineweb或Dolma结合使用,以进行更大规模的训练。
背景与挑战
背景概述
Zyda数据集是由Zyphra团队于2024年发布的一个包含1.3万亿Token的开源预训练数据集,旨在为大规模语言模型训练提供高质量的数据支持。该数据集通过整合多个开源且高质量的数据源,并经过统一的过滤和去重处理,确保了数据的高效性和多样性。Zyda的早期版本已被用于Zamba模型的预训练,并在多项语言任务中表现出色,证明了其在预训练数据集中的卓越性能。Zyda的发布不仅推动了大规模语言模型的研究,还为开源社区提供了宝贵的资源。
当前挑战
Zyda数据集在构建过程中面临多重挑战。首先,数据源的多样性和质量参差不齐,如何确保整合后的数据集在语言任务中的表现优于现有数据集是一个关键问题。其次,数据过滤和去重过程中,如何平衡数据质量与数据量的保留,尤其是在处理大规模数据时,技术难度显著增加。此外,数据集可能包含未过滤的个人敏感信息或偏见内容,如何在保证数据开放性的同时,减少潜在的法律和伦理风险,也是构建过程中不可忽视的挑战。
常用场景
经典使用场景
Zyda数据集作为大规模语言模型预训练的核心资源,广泛应用于自然语言处理领域。其1.3万亿Token的规模使其成为训练超大规模语言模型的理想选择,尤其是在需要高精度和广泛覆盖的文本生成任务中。通过结合多个高质量开源数据集并进行统一过滤和去重,Zyda在语言模型训练中表现出色,尤其适用于从数十亿到数万亿Token规模的模型训练。
实际应用
在实际应用中,Zyda数据集被广泛用于训练高性能的语言模型,支持多种下游任务,如文本生成、机器翻译、问答系统等。其高质量的数据源和严格的过滤流程确保了模型在实际应用中的稳定性和可靠性。例如,Zyda已被用于Zamba模型的预训练阶段,该模型在多个基准测试中表现出色,证明了Zyda在实际应用中的强大潜力。
衍生相关工作
Zyda数据集的发布推动了多项相关研究工作的进展。例如,基于Zyda训练的Zamba模型在语言建模任务中表现出色,成为该领域的经典工作之一。此外,Zyda的过滤和去重技术也为其他大规模数据集的处理提供了参考。其技术报告和开源代码进一步促进了学术界对大规模数据集处理方法的探索,推动了自然语言处理领域的技术进步。
以上内容由遇见数据集搜集并总结生成


