CAPTex
收藏Hugging Face2025-02-21 更新2025-02-22 收录
下载链接:
https://huggingface.co/datasets/AmirHossein2002/CAPTex
下载链接
链接失效反馈官方服务:
资源简介:
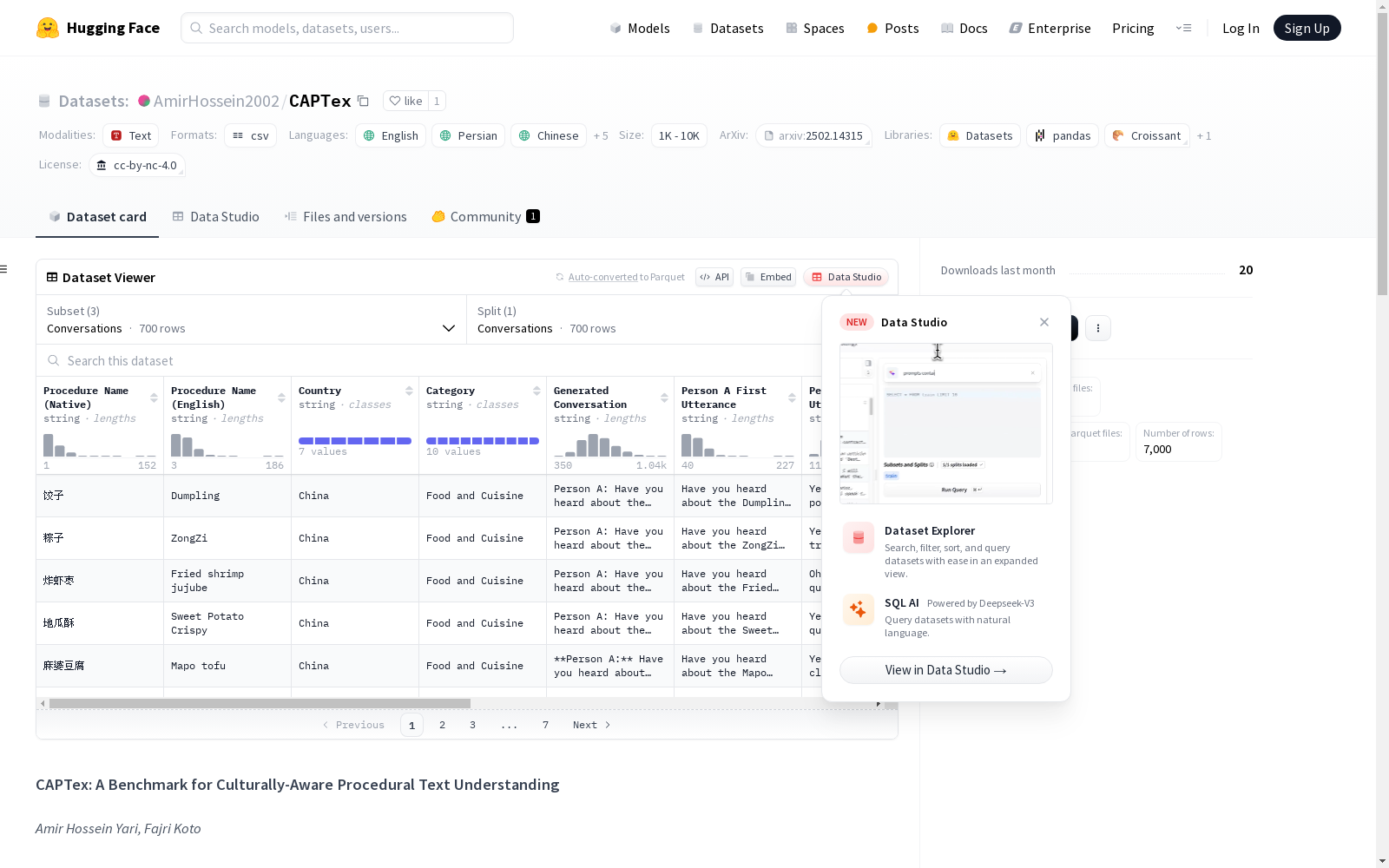
CAPTex(文化感知程序性文本)数据集是一个用于评估多语言大型语言模型在理解不同文化背景下程序性文本的能力的基准。该数据集包括来自七个具有不同文化的地区的程序性知识,涵盖食品与烹饪、节日庆典、社会礼仪与款待等十个文化意义领域。数据集中的程序性文本由原住民提供,包括原始文本和英文翻译,并且还包括基于这些文本的对话和多项选择题。
创建时间:
2025-02-20
搜集汇总
数据集介绍
构建方式
CAPTex数据集的构建采取了多语言、多文化的视角,涵盖了来自中国、印度、印尼、伊朗、日本、尼日利亚和巴基斯坦七个具有文化差异的地区。数据集包含由各区域母语人士贡献的原始程序性文本及其英文翻译,确保了文本的真实性和文化丰富性。数据集分为程序性文本、结构化对话和多项选择题三种类型,涵盖了十个文化意义显著的领域。
特点
CAPTex数据集的特点在于其文化意识的程序性文本理解基准,提供了700个结构化对话和5600个多项选择题,以及1400个人类编写的程序性文本(包括七种本土语言及其英文翻译)。该数据集在语言资源分配上也有所区分,包括高资源语言(中文、日语、英语)、中等资源语言(波斯语、印地语)和低资源语言(印尼语、乌尔都语、豪萨语),从而为评估多语言大型语言模型在不同文化背景下的理解和推理能力提供了全面的测试平台。
使用方法
使用CAPTex数据集时,用户可根据不同的配置名称访问不同的数据文件,如程序性文本(Procedures)、多项选择题(MCQs)和对话(Conversations)。数据集遵循Creative Commons Attribution 4.0国际许可,允许用户在提供适当归属和链接至许可的情况下,自由使用、共享、改编、分发和复制数据集中的内容。
背景与挑战
背景概述
CAPTex数据集,全称为Culturally-Aware Procedural Texts,是由Sharif University of Technology和MBZUAI的研究人员Amir Hossein Yari与Fajri Koto于2025年创建的一组多语言大型语言模型评估数据集。该数据集旨在评估多语言大型语言模型对嵌入在不同文化背景中的程序性文本的理解和推理能力。CAPTex包含了来自中国、印度、印度尼西亚、伊朗、日本、尼日利亚和巴基斯坦等七个文化独特区域的程序性知识,由各区域的母语人士贡献原始程序性文本及其英文翻译,确保了数据集的真实性和文化丰富性。该数据集在程序性文本理解、多语言处理和文化差异理解等领域产生了重要影响。
当前挑战
CAPTex数据集面临的挑战主要包括:如何确保多语言大型语言模型在理解程序性文本时考虑到不同文化的独特性,以及如何提高模型对低资源语言的处理能力。构建过程中,数据集的创建者面临了跨文化交流的障碍、文本收集和翻译的准确性问题,以及如何平衡不同语言和文化背景下的数据代表性等挑战。
常用场景
经典使用场景
CAPTex数据集作为评估多语种大型语言模型对嵌入在多元文化背景中的程序性文本理解和推理能力的基准,其经典使用场景在于对mLLMs进行跨文化程序性文本理解的性能测试。该数据集通过提供来自七个文化区域的程序性知识,使得研究者能够评估模型在不同文化背景下的适应性和准确性。
实际应用
在实际应用中,CAPTex数据集可被用于开发能够理解和生成跨文化程序性文本的智能系统,如自动化的多语言旅游指南、文化交流平台以及多文化教育材料编制工具。
衍生相关工作
基于CAPTex数据集,相关研究工作已经衍生出对多语种模型在跨文化交流、多文化知识获取和处理等方面能力的深入分析,以及如何通过增强模型的文化意识来提升其跨文化理解和交互质量的研究。
以上内容由遇见数据集搜集并总结生成


