codelion/logical-puzzles-cot
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/codelion/logical-puzzles-cot
下载链接
链接失效反馈官方服务:
资源简介:
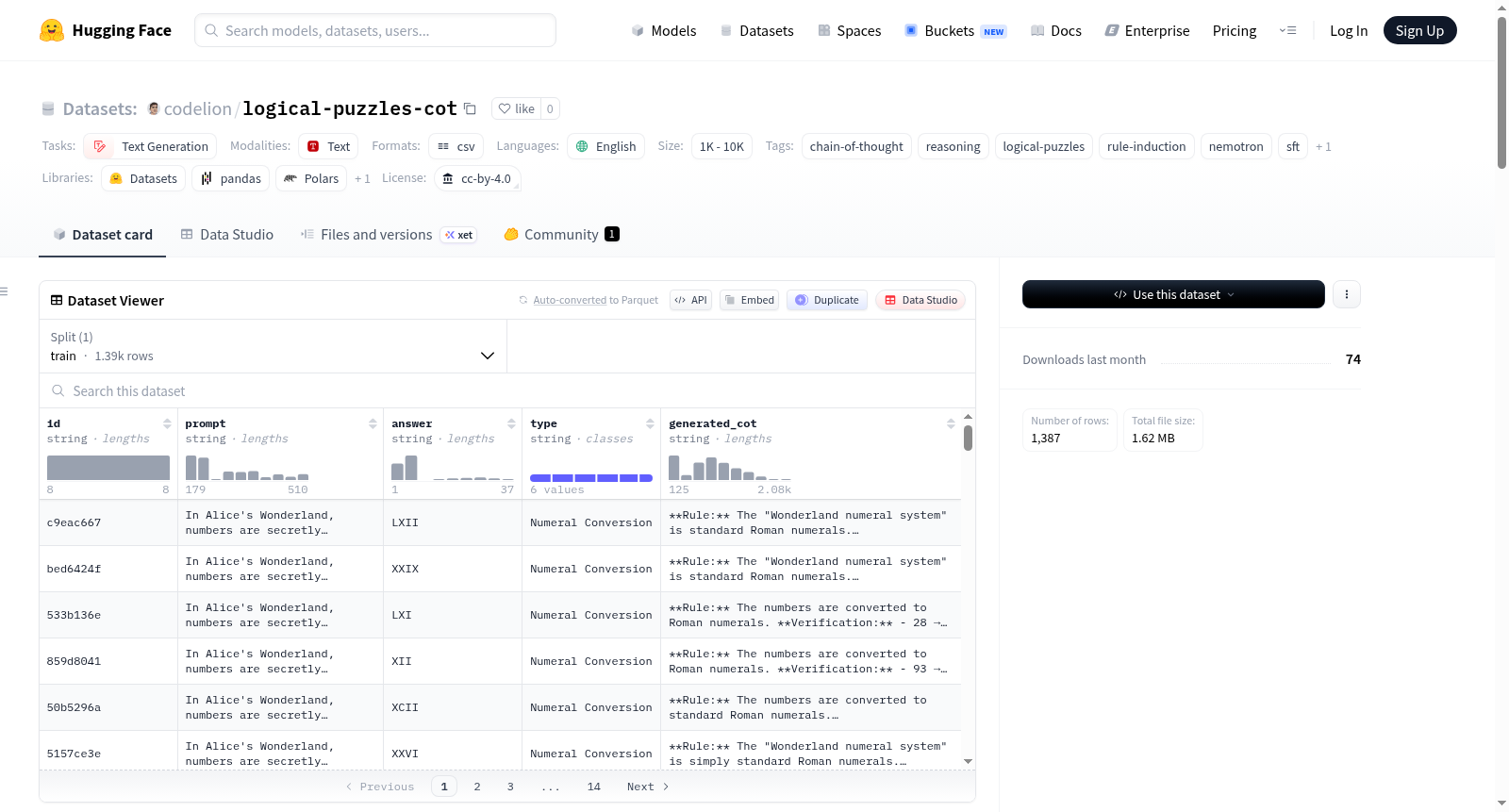
一个精选的语料库,包含1,387个经过验证的思维链推理轨迹,用于规则归纳谜题家族,这些谜题用于NVIDIA Nemotron模型推理挑战赛。每个推理轨迹都由前沿模型生成并独立验证,确保最终答案与黄金答案完全匹配。数据集涵盖了六个不同的规则家族,包括数字转换、重力常数、单位转换、文本加密、位操作和方程变换。数据集还详细说明了生成方法、使用方式、组成和限制。
A curated corpus of 1,387 verified chain-of-thought reasoning traces for the rule-induction puzzle families used in the NVIDIA Nemotron Model Reasoning Challenge on Kaggle. Every trace was generated by a frontier model and independently verified: the traces final `oxed{}` answer must exactly match the gold answer for that puzzle, or the trace is excluded. The dataset covers six rule families: Numeral Conversion, Gravitational Constant, Unit Conversion, Text Encryption, Bit Manipulation, and Equation Transformation. It also details the generation methodology, usage, composition, and limitations.
提供机构:
codelion
搜集汇总
数据集介绍
构建方式
该数据集旨在为规则归纳类逻辑谜题提供高质量的思维链推理轨迹,其构建过程严谨而精细。首先,利用前沿模型(如Anthropic Claude Sonnet 4.6)对每个谜题逐一生成初版思维链,并设定严格格式约束。随后,对生成的每条轨迹进行独立验证,确保其最终答案与标准答案完全一致,仅保留通过的样本。针对某些类别中模型解决率偏低的情况,采用算法化补全策略,例如通过逐位布尔搜索或算术规则族搜索推导缺失规则,并据此生成自然语言思维的链式推理。对于少数格式错误但推理正确的轨迹,予以重写以保留正确推理过程。此外,极少数边缘案例由人类专家编写思维链。最终,经过层层筛选与校验,构建出包含1,387条已验证正确推理轨迹的语料库。
特点
该数据集的核心特色在于其高质量与多样性。所有思维链轨迹均经过独立验证,确保最终答案与标准答案严格匹配,杜绝了推理链条中的误差积累。数据集覆盖六大谜题类别,包括数字转换、引力常数推算、单位换算、文本加密、位操作及方程变换,展现了丰富的规则归纳场景。每条样本包含唯一的谜题标识、原始提示、标准答案、类别标签及经过验证的思维链文本,结构清晰且格式统一。尤为突出的是,该数据集中的思维链由前沿模型生成,呈现出自然语言推理的流畅风格,与传统的确定性思维链语料形成互补,有助于提升模型在多样化场景下的推理鲁棒性与泛化能力。
使用方法
该数据集可直接用于监督式微调,适配成熟的LoRA训练流程。用户可通过HuggingFace的`datasets`库加载数据,例如`load_dataset("codelion/logical-puzzles-cot", split="train")`,即可获得训练集。在实际应用中,建议将其作为自然语言推理风格的补充语料,与传统的确定性思维链语料结合使用:先在确定性语料上训练基线模型以保证基础准确性,再在本数据集上微调以增强模型的自然推理风格和分布外鲁棒性。对于训练中的损失遮蔽,可通过0/1掩码区分提示区域与响应区域,从而更精准地优化模型生成能力。该数据集的结构直接兼容主流微调框架,无需额外适配即可投入使用。
背景与挑战
背景概述
随着大语言模型在复杂推理任务上的能力日益受到关注,链式思维(Chain-of-Thought)推理成为了提升模型可解释性与准确性的关键技术路径。2024年,NVIDIA 发起了 Nemotron 模型推理挑战赛,旨在推动模型在规则归纳型逻辑谜题上的推理能力。在此背景下,由研究团队构建的 logical-puzzles-cot 数据集应运而生,收录了1,387条经过严格验证的链式思维推理轨迹,覆盖罗马数字转换、物理常数推断、单位换算、文本加密、位操作与方程变换六大谜题类别。该数据集不仅为参赛者提供了高质量的训练资源,也推动了规则归纳推理领域评测标准的建立,对后续研究具有显著的参考价值。
当前挑战
该数据集所解决的领域问题核心在于规则归纳推理,即模型需从少量示例中推导出隐含规则并应用于新查询,这一过程对模型的泛化能力与符号理解构成严峻挑战。在构建过程中,研究团队面临多重困难:前沿模型对特定类别谜题求解率低于60%,需引入算法化推导与人工补全策略;格式一致性要求极高,如前导零、符号保留等细节,导致大量推理轨迹因输出格式偏差被丢弃;部分谜题系列如密码算术因操作语义复杂而无法生成可信推理链,最终被排除。此外,位操作与方程变换类别的覆盖率分别仅为66%与88%,反映了规则归纳任务中固有的难度差异与构建瓶颈。
常用场景
经典使用场景
逻辑谜题链式思考数据集(logical-puzzles-cot)专为提升大语言模型的规则归纳与多步推理能力而构建,其经典使用场景聚焦于监督微调(SFT)范式下的推理链生成。数据集合拢了六类规则归纳谜题——涵盖数字转换、引力常数求解、单位换算、文本加密、位操作及方程变换——每一道谜题均配有经前沿模型生成并独立验证的链式思考轨迹。研究者可直接将其嵌入Nemotron模型LoRA训练管线,或作为推理链语料与确定性数据集互补,以提升模型在自然语言推理风格及分布外场景中的鲁棒性。该数据集精准回应了当前大模型在结构化推理任务中易出现逻辑断裂、格式失配等痛点,为因果语言模型的推理能力强化提供了高质量、可复现的训练素材。
衍生相关工作
该数据集衍生了若干具有启发意义的经典工作。最直接的关联是其在NVIDIA Nemotron模型推理挑战赛中的源起与落地,与huikang等人开源的确定性CoT语料库形成了天然互补,后者的获奖方案依托该数据集实现了自然推理风格与确定性格局的有机融合。此外,该数据集的生成方法论——特别是针对硬性类别的算法补全策略(如位操作的逐比特布尔搜索和方程变换的算子族搜索)——启发了后续研究者在复杂符号推理任务中结合符号引擎与语言模型的混合推理框架。更进一步,该数据集对密码算术谜题的有意剔除,催生了一批专门研究复合算子语义推理的数据集构建工作,推动领域内学者重新审视规则归纳任务中运算符语义泛化的边界,为构建更全面的推理能力基准提供了反思与迭代的契机。
数据集最近研究
最新研究方向
该数据集围绕大型语言模型在规则归纳与链式推理任务中的能力提升展开,聚焦于通过高质量、经过验证的思维链数据来增强模型的逻辑推理与泛化能力。关联到NVIDIA Nemotron模型推理挑战这一前沿热点事件,该数据集针对六类规则归纳谜题(如数字转换、单位换算、文本加密等)生成并验证了1387条独立正确的思维链,特别关注了传统确定性方法难以处理的高难度类别(如位运算和方程变换),通过算法补充与人类撰写相结合的方式弥补模型生成的不稳定性。其意义在于为SFT与LoRA微调提供了与现有确定性语料风格互补的自然语言推理资源,有助于模型在规则归纳任务上更好地平衡精确性与自然推理表达,对提升AI在形式化推理领域的鲁棒性和可解释性具有重要推动作用。
以上内容由遇见数据集搜集并总结生成


