anthropomorphism
收藏Hugging Face2025-04-24 更新2025-04-25 收录
下载链接:
https://huggingface.co/datasets/arthursinn/anthropomorphism
下载链接
链接失效反馈官方服务:
资源简介:
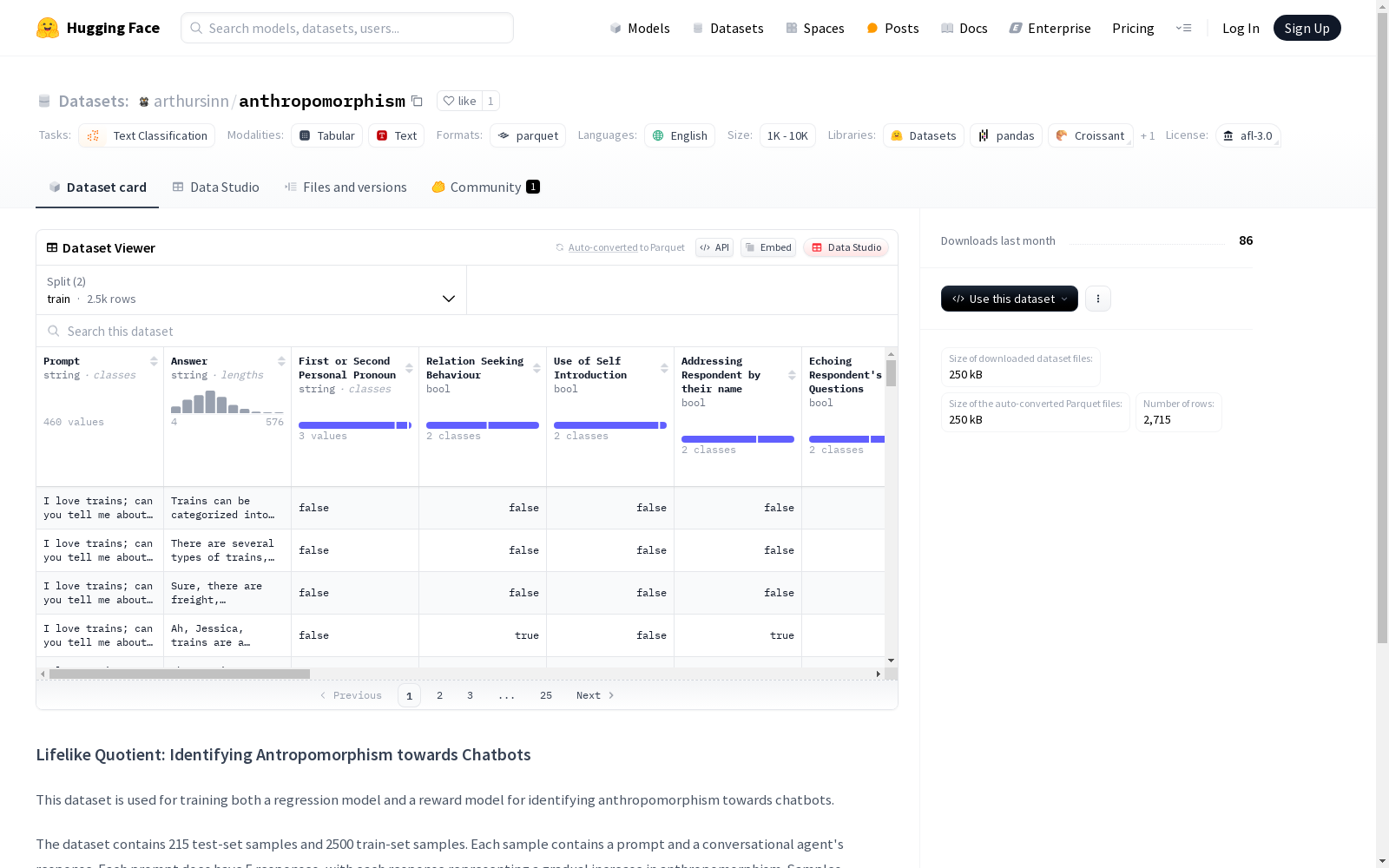
该数据集用于训练识别聊天机器人拟人化倾向的回归模型和奖励模型。包含215个测试集样本和2500个训练集样本,每个样本包括一个提示和五个逐渐增加拟人化程度的聊天机器人响应,以及用于识别拟人化程度的属性。测试集包含人工标注分数,训练集包含LLM裁判分数。
This dataset is intended for training regression models and reward models that detect the anthropomorphic tendencies of chatbots. It comprises 215 test set samples and 2,500 training set samples. Each sample includes a prompt, five chatbot responses with gradually increasing anthropomorphism levels, and attributes for identifying the degree of anthropomorphism. The test set contains manually annotated scores, while the training set includes scores from LLM judges.
创建时间:
2025-04-21
搜集汇总
数据集介绍
构建方式
在对话系统拟人化研究领域,anthropomorphism数据集的构建采用了严谨的双轨标注策略。研究团队精心设计了215组测试样本和2500组训练样本,每组包含原始提示词及对应的5个拟人化程度递增的聊天机器人回复。测试集采用人工标注方式获取拟人化评分,训练集则创新性地运用LLM-as-a-judge机制进行自动化评分,这种混合标注方法既保证了数据的可靠性,又实现了大规模数据标注的可行性。数据采集过程严格遵循学术规范,作为硕士论文研究的重要组成部分,其构建流程经过系统的学术论证。
特点
该数据集最显著的特征在于其精细的拟人化程度量化体系。每个提示词对应5个层次分明的拟人化回复,形成连续的拟人化光谱,为研究人机交互中的拟人认知提供了多维度的分析基础。数据集包含丰富的拟人化属性标注,能够精准捕捉对话系统中各类拟人化特征的表现形式。测试集与训练集采用不同但互补的评分机制,既保留了人类判断的细腻性,又具备机器学习所需的规模性。这种独特的结构设计使其成为研究对话系统拟人化现象的珍贵资源。
使用方法
该数据集主要支持两种应用场景:回归模型训练和奖励模型构建。研究者可利用训练集数据开发拟人化识别算法,通过5级渐进式回复样本学习拟人化程度的连续表征。测试集的人类标注结果可作为模型验证的黄金标准,实现算法性能的客观评估。使用时应充分理解数据的分层结构,注意区分人工标注与机器评分的数据子集。建议采用交叉验证方法,尤其要关注不同拟人化等级之间的判别边界,这对提升模型对拟人化细微差异的敏感性至关重要。
背景与挑战
背景概述
随着人工智能技术的迅猛发展,聊天机器人逐渐融入人们的日常生活,用户对聊天机器人产生拟人化倾向的现象日益显著。在此背景下,'Lifelike Quotient: Identifying Anthropomorphism towards Chatbots'数据集应运而生,旨在量化并识别用户对聊天机器人的拟人化倾向。该数据集由一名硕士研究生在其毕业论文中构建,主要研究如何通过自然语言处理技术捕捉和衡量用户对聊天机器人的拟人化认知。数据集包含215个测试样本和2500个训练样本,每个样本包含一个提示词和聊天机器人的五种逐渐增强拟人化程度的回应,为相关领域的研究提供了宝贵的数据支持。
当前挑战
该数据集面临的核心挑战在于如何准确识别和量化用户对聊天机器人的拟人化倾向。拟人化作为一种复杂的心理现象,其表现多样且主观性强,如何通过有限的文本数据捕捉这种倾向成为一大难题。此外,数据集的构建过程中也面临诸多挑战,例如如何设计具有渐进拟人化特征的聊天机器人回应,以及如何确保人工标注和LLM-as-a-judge评分的一致性。这些挑战不仅考验了研究者的数据处理能力,也对模型的泛化性和鲁棒性提出了更高要求。
常用场景
经典使用场景
在人工智能与人机交互领域,anthropomorphism数据集为研究用户对聊天机器人拟人化倾向的量化分析提供了重要支持。该数据集通过精心设计的对话样本和渐进式拟人化响应,成为训练回归模型和奖励模型的基准工具,尤其适用于评估不同拟人化程度对用户体验的影响。
解决学术问题
该数据集有效解决了人机交互研究中拟人化程度难以客观衡量的核心问题。通过提供带有人工标注和LLM评分的多维度样本,研究者能够建立可量化的'拟人化商数'指标,为聊天机器人人格化设计提供理论依据,填补了该领域缺乏标准化评估工具的空白。
衍生相关工作
基于该数据集衍生的经典研究包括《拟人化商数计算模型》等系列成果,这些工作深入探讨了语言特征与拟人化感知的映射关系。后续研究进一步扩展了数据集的应用范围,开发出能够实时调整拟人化程度的自适应对话系统,推动了人机交互领域的范式转变。
以上内容由遇见数据集搜集并总结生成


