emrQA-msquad
收藏arXiv2024-04-18 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/Eladio/emrqa-msquad
下载链接
链接失效反馈官方服务:
资源简介:
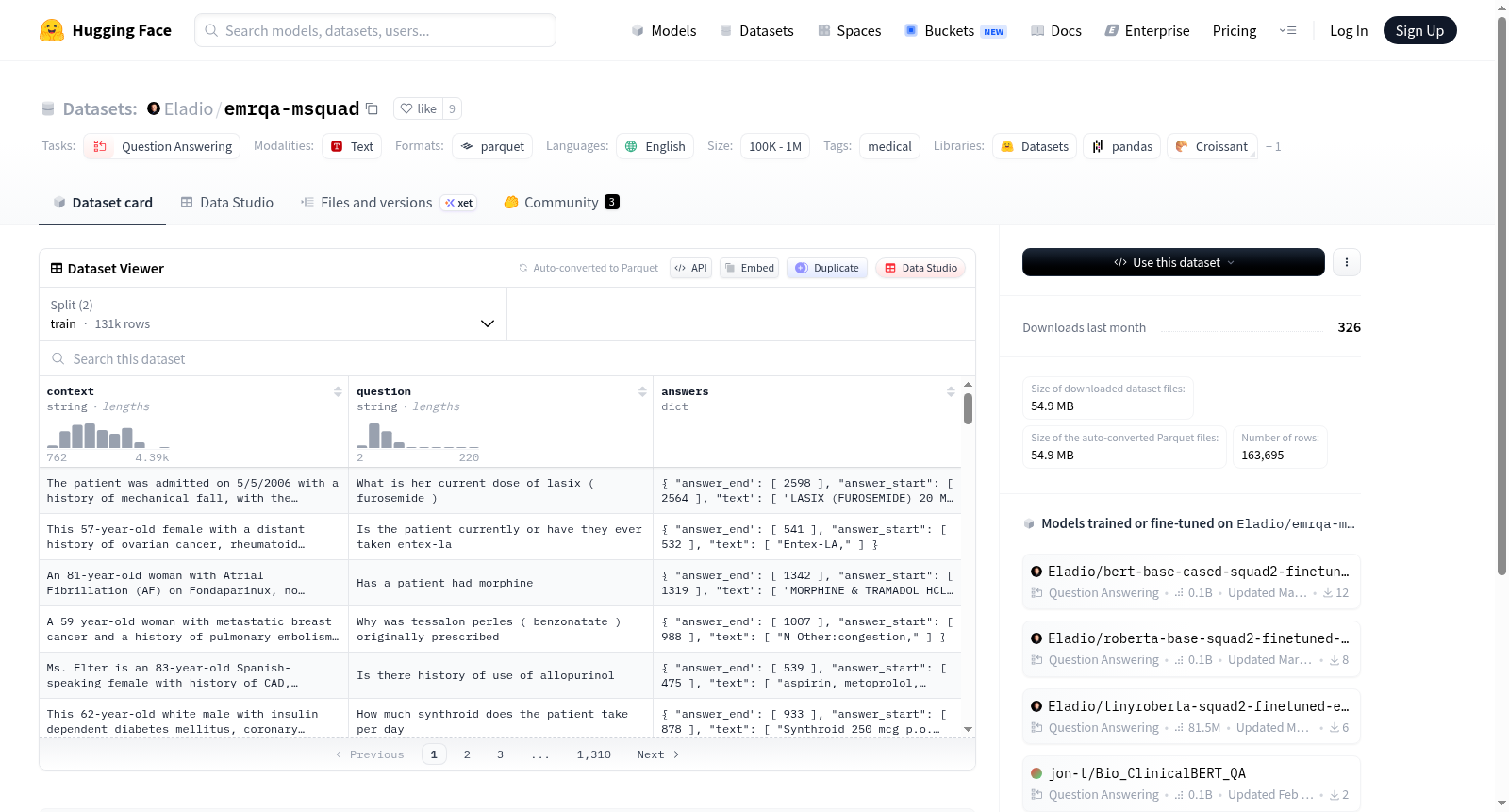
emrQA-msquad是一个专为医疗领域设计的机器阅读理解数据集,由北京理工大学计算机科学与技术学院创建。该数据集包含163,695个问题和4,136个手动获取的答案,旨在提高医疗问答系统的准确性。数据集通过整合emrQA和SQuAD V2.0框架,专注于医疗术语和问题的复杂性。其应用领域包括临床决策支持和医疗研究,致力于解决医疗信息访问和应用中的挑战。
emrQA-msquad is a machine reading comprehension dataset specifically designed for the medical domain, created by the School of Computer Science and Technology, Beijing Institute of Technology. This dataset contains 163,695 questions and 4,136 manually obtained answers, aiming to improve the accuracy of medical question answering systems. It integrates the frameworks of emrQA and SQuAD V2.0, focusing on medical terminology and the complexity of questions. Its application fields include clinical decision support and medical research, and it is committed to addressing the challenges in medical information access and application.
提供机构:
北京理工大学计算机科学与技术学院
创建时间:
2024-04-18
搜集汇总
数据集介绍
构建方式
在医学自然语言处理领域,构建高质量数据集是提升问答系统性能的关键。emrQA-msquad数据集以emrQA的医学内容为基础,通过整合SQuAD V2.0的结构化框架进行重构。原始emrQA报告的非结构化特性促使研究团队采用大型语言模型进行自动化摘要生成,以浓缩医学信息并保留答案内容。随后,通过人工方式从摘要中逐一提取答案,形成新的真实标注,最终构建出包含163,695个问题和4,136个答案的标准化数据集,确保了数据在医学语境下的准确性与一致性。
使用方法
emrQA-msquad数据集主要用于医学问答系统的训练与评估,特别适用于基于阅读理解的跨度提取任务。研究人员可借助该数据集对预训练模型如BERT、RoBERTa等进行领域特定的微调,以提升模型在医学文本上的理解能力。使用过程中,需按照数据集的划分进行训练与验证,并利用提供的标准指标如F1分数、精确率和召回率进行性能评估。该数据集的结构兼容主流机器学习框架,便于集成到现有研究流程中,推动医学人工智能应用的进步。
背景与挑战
背景概述
随着机器阅读理解技术在医疗问答系统中的广泛应用,构建高质量的专业医学数据集成为推动该领域发展的关键。emrQA-msquad数据集由北京理工大学的Jimenez Eladio与吴浩等人于近年创建,旨在应对医学领域内术语复杂、问题模糊等固有挑战。该数据集巧妙融合了emrQA的医学内容与SQuAD V2.0的结构化框架,包含超过16万个问题与4千余条人工标注答案,为医学问答系统提供了精准的训练资源。其诞生不仅显著提升了BERT、RoBERTa等模型在医学文本理解上的性能,更对临床决策支持与医学研究产生了深远影响。
当前挑战
emrQA-msquad数据集致力于解决医学问答系统中机器阅读理解的核心挑战,即如何准确提取医学文本中的关键信息以回答复杂问题。构建过程中面临多重困难:原始emrQA数据集缺乏结构化,医学报告内容冗长且非标准化,难以直接应用于现有问答模型;同时,自动化摘要技术无法完整保留答案的精确位置,迫使研究人员采用耗时的人工方式重新标注答案。此外,医学术语的多样性与问题的歧义性进一步增加了数据集构建的复杂性,要求模型具备深度的领域知识适应能力。
常用场景
经典使用场景
在医疗自然语言处理领域,emrQA-msquad数据集为机器阅读理解任务提供了结构化且专业的训练资源。该数据集通过整合emrQA的医学内容与SQuAD V2.0的框架,构建了包含16万余个问题与4千余个答案的标准化语料库。其经典应用场景在于支持医学问答系统的开发与评估,特别是在电子病历文本的跨度提取任务中,能够有效训练模型从复杂的临床文档中精准定位关键信息。
解决学术问题
emrQA-msquad数据集主要解决了医学领域机器阅读理解中的两大核心问题:一是缓解了医学专业术语复杂性和问题模糊性带来的模型理解障碍,二是填补了公开医学数据集中结构化标注资源的不足。通过提供高质量的标注数据,该数据集显著提升了BERT、RoBERTa等预训练模型在医学语境下的性能,使得模型在F1分数等关键指标上实现了从10.1%到46.8%的跨越式提升,为临床决策支持系统的研究奠定了数据基础。
实际应用
在实际医疗场景中,emrQA-msquad数据集能够赋能智能临床辅助系统的构建。例如,在电子病历分析系统中,基于该数据集训练的模型可快速提取患者病史、诊断结果或治疗建议等关键信息,辅助医生进行病例回顾与诊断决策。此外,该数据集还可用于开发医学教育工具,帮助医学生通过问答形式高效学习临床知识,提升医疗信息检索的准确性与效率。
数据集最近研究
最新研究方向
在医疗问答系统领域,emrQA-msquad数据集的研究正聚焦于如何通过结构化改造提升机器阅读理解模型在医学文本中的性能。该数据集将emrQA的医学内容与SQuAD V2.0的清晰框架相结合,构建了包含16万余个问题与4千余个手动标注答案的专用资源。前沿探索主要围绕预训练语言模型如BERT、RoBERTa等的领域自适应微调,实验表明经过针对性优化的模型在F1分数0.75至1.00区间内的表现显著提升,增幅最高达30个百分点以上。这一进展不仅推动了临床决策支持系统的精准化,也为处理医学术语复杂性和问题歧义性提供了新的数据基础,强化了人工智能在医疗信息处理中的实际应用潜力。
相关研究论文
- 1emrQA-msquad: A Medical Dataset Structured with the SQuAD V2.0 Framework, Enriched with emrQA Medical Information北京理工大学计算机科学与技术学院 · 2024年
以上内容由遇见数据集搜集并总结生成


