ghananlpcommunity/multilingual-emotion-ghana
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ghananlpcommunity/multilingual-emotion-ghana
下载链接
链接失效反馈官方服务:
资源简介:
一个多语言情感分类数据集,覆盖加纳的四种语言(英语、Twi、Ewe、Dagbani),旨在支持低资源非洲语言环境下的小型语言模型(如SmolLM2)的情感检测微调任务。数据集格式为指令调优(input → structured output),分为训练集、验证集和测试集(80/10/10比例)。每行数据包含input(指令提示、标签列表、语言标签和源文本)、output(结构化目标)、language(语言标识)和label(原始标签字符串)四个列。所有非英语样本都是相应英语样本的翻译,四个语言的子集在行数和标签分布上是平衡的。数据集的设计目的是用于微调小型语言模型,特别是在多语言非洲情感分类方面。
A multilingual emotion classification dataset covering four languages spoken in Ghana (English, Twi, Ewe, Dagbani), built to support fine-tuning of small language models (e.g. SmolLM2) for emotion detection in low-resource African language contexts. The dataset is formatted as instruction-tuned (input → structured output) and split into train, validation, and test sets (80/10/10 ratio). Each row contains four columns: input (instruction prompt with label list, language tag, and source text), output (structured target), language (language identifier), and label (raw label string). All non-English samples are translations of corresponding English samples, with balanced row counts and label distributions across all four language subsets. The dataset is designed for fine-tuning small language models, particularly for multilingual African emotion classification.
提供机构:
ghananlpcommunity
搜集汇总
数据集介绍
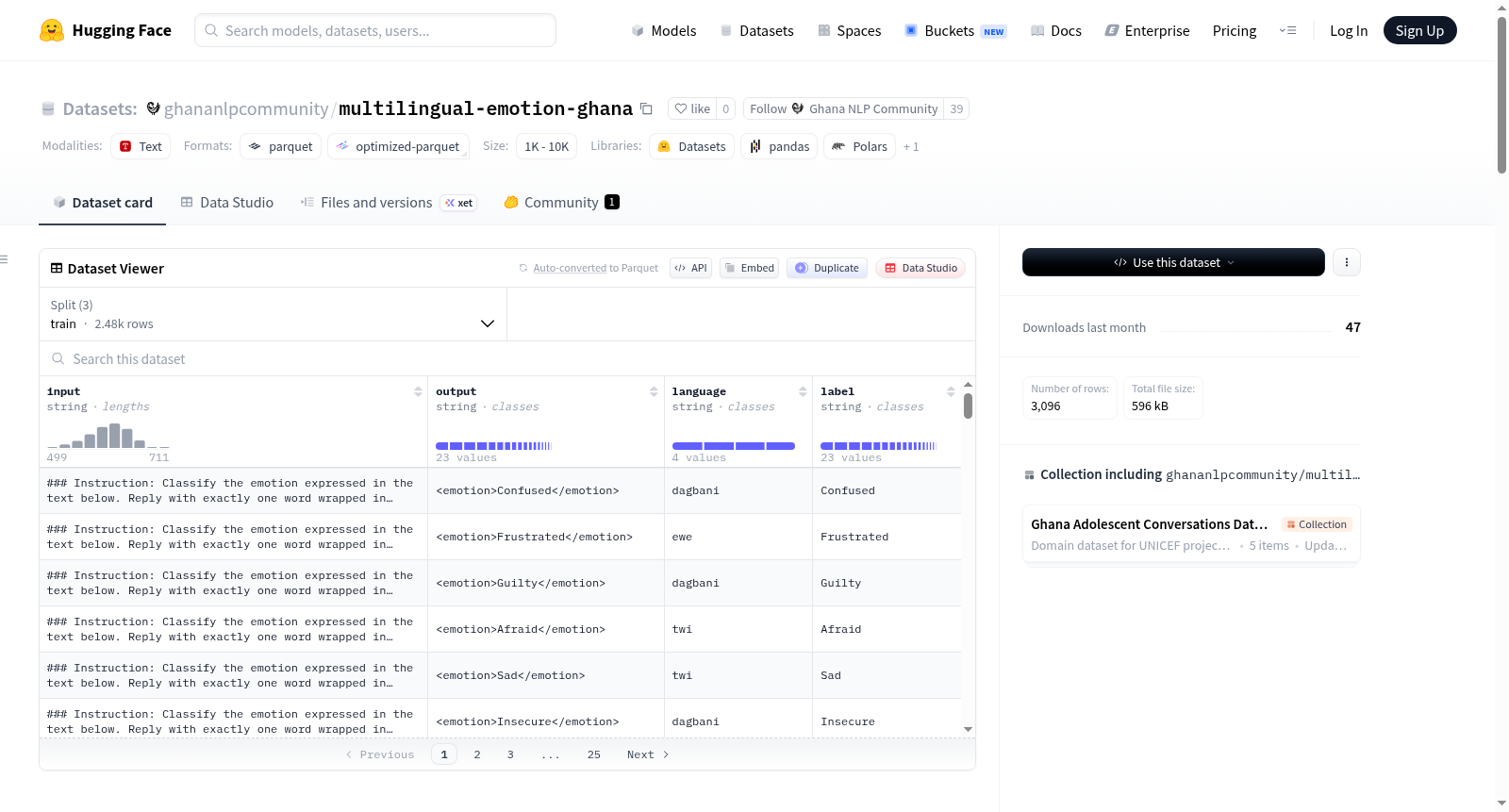
构建方式
该数据集由加纳自然语言处理社区(GhanaNLP Community)精心构建,旨在填补非洲低资源语言情感识别领域的空白。数据集覆盖英语、契维语、埃维语和达格巴尼语四种加纳境内广泛使用的语言,共计3096条样本。所有非英语样本均源自对应英文样本的翻译,并采用索引对齐方式实现情感标签的跨语言传递,确保四个子集在样本数量与标签分布上保持均衡。数据集按照80/10/10的比例划分为训练集(2476条)、验证集(309条)和测试集(311条),以指令微调格式(input → structured output)组织,每条记录包含输入指令、结构化情感输出、语言标签和原始标签四个字段。
使用方法
该数据集专为多语言情感分类任务的模型微调而设计。使用者可通过HuggingFace Datasets库直接加载数据,利用其预定义的训练、验证和测试划分进行模型训练与评估。由于输出采用标准化的<emotion>标签格式,推荐使用Python的re模块编写如下解析函数:import re; def extract_emotion(model_output): match = re.search(r'<emotion>(.*?)</emotion>', model_output); return match.group(1) if match else None,从而从模型输出中可靠提取情感标签。此外,数据集提供的原始标签字段(label)可直接用于计算分类指标或按语言过滤样本,便于进行细粒度性能分析。
背景与挑战
背景概述
多语言情感数据集(multilingual-emotion-ghana)由加纳NLP社区(GhanaNLP Community)于2025年创建,专注于解决低资源非洲语言在情感分类任务中的稀缺性问题。该数据集覆盖英语、契维语、埃维语和达戈巴尼语四种加纳主要语言,涵盖好奇、沮丧、不安全、宽慰和悲伤五种情感标签,采用指令微调格式构建。作为面向小语言模型(如SmolLM2)微调的资源,其发布填补了撒哈拉以南非洲语言情感分析领域的空白,为多语言自然语言处理研究提供了基础性支撑,推动了非洲本土语言技术发展。
当前挑战
该数据集面临的挑战首先源于领域问题的复杂性:低资源非洲语言的情感标注语料极度匮乏,且情感表达受文化语境影响显著,通用情感标签可能无法准确映射本土语义。其次,构建过程中需克服跨语言平行语料对齐的困难——非英语样本通过翻译英文句子获得,标签依赖索引对齐,可能引入翻译偏差或情感语义丢失;同时,四种语言分属不同语系家族,如契维语和埃维语属尼日尔-刚果语系库阿语支,达戈巴尼语属古尔语支,其语法结构和情感词汇差异增加了标注一致性维护的难度。
常用场景
经典使用场景
在低资源非洲语言的情感分析领域,multilingual-emotion-ghana数据集扮演了不可或缺的角色。它涵盖了加纳地区四种代表性语言——英语、契维语、埃维语和达巴尼语,为研究者提供了一个跨语言情感标注的宝贵资源。该数据集最经典的使用场景在于微调小型语言模型,如SmolLM2,以实现多语言情感分类任务。通过其精心设计的指令微调格式,每条数据都包含结构化的输入与输出,使得模型能够准确地识别并生成带有情感标签的响应,从而在资源受限的环境中高效运行。这一场景不仅推动了非洲本土语言的自然语言处理技术进步,也为全球多语言情感分析提供了新的实验基准。
解决学术问题
该数据集直面学术研究中的核心痛点:低资源语言的情感标注数据极度匮乏,导致情感分析模型在非洲语言上表现不佳。通过提供平衡的四种语言情感标签,它解决了跨语言情感分类中的标注不一致问题,使得研究者能够在一个统一的框架下比较不同语言的情感表达模式。其设计还特别关注了结构化输出的可靠性,通过<emotion>标签简化了模型推理结果的解析,降低了评估误差。这一贡献弥合了高资源与低资源语言之间的鸿沟,为多语言情感分析的公平性和包容性注入了新的活力,推动了自然语言处理技术向更广泛的语言社区延伸。
实际应用
在实际应用层面,multilingual-emotion-ghana数据集为加纳及西非地区的智能系统开发提供了坚实基础。例如,它可用于构建情感感知的客户服务机器人,在契维语或埃维语中识别用户情绪,从而提供更贴心的响应;或用于分析社交媒体上的公共情感动态,帮助政府机构和企业了解民众的反馈。此外,该数据集还支持教育领域的情绪监测系统,识别学生在学习平台上的困惑或挫败感,进而优化教学内容。这些应用不仅增强了技术在非洲本土语境中的适用性,也展示了低资源语言数据集在现实场景中的巨大潜力,促进了数字包容性的实现。
数据集最近研究
最新研究方向
在当前非洲语言自然语言处理技术迅猛发展的浪潮中,多语言情感数据集multilingual-emotion-ghana的发布为低资源语言情感识别研究开辟了崭新维度。该数据集覆盖加纳四种官方及本土语言——英语、契维语、埃维语和达格巴尼语,采用指令微调格式与结构化情感标签输出,特别适配SmolLM2等小型语言模型的微调需求。其前沿研究方向聚焦于情感分类任务在多语种非洲语境下的迁移学习与跨语言泛化能力,通过平衡的样本分布与标签对齐策略,探索情感表达在不同语系间的语义映射规律。该数据集与GhanaNLP社区推动的契维语洁净语料库等工作形成生态互补,不仅为稀缺的低资源非洲语言情感分析提供了标准化基准,更助力弥合全球情感计算领域的地域鸿沟,对推动包容性人工智能发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


