SAND-MATH
收藏Hugging Face2025-07-29 更新2025-07-30 收录
下载链接:
https://huggingface.co/datasets/amd/SAND-MATH
下载链接
链接失效反馈官方服务:
资源简介:
SAND-Math是一个由LLM生成的数学问题及其解决方案的高质量、高难度数据集,旨在解决数学LLM训练数据稀缺的问题。数据集通过一个全面的端到端流程生成,包括问题生成、难度提升、质量控制和评估。每个实例包含问题文本、解决方案、难度评分、所属的数学分支以及是否为难度提升版本的标识。
提供机构:
AMD
创建时间:
2025-07-29
原始信息汇总
SAND-MATH数据集概述
数据集基本信息
- 名称: SAND-MATH (Synthetic Augmented Novel and Difficult Mathematics)
- 语言: 英语 (en)
- 许可证: 其他 (other)
- 任务类别: 问答、文本生成
- 标签: 数学、合成数据、问答、推理、大语言模型 (LLM)
- 库名称: datasets
数据集特点
- 新颖问题生成: 利用SOTA LLMs的潜在元认知能力,通过最小约束提示生成问题。
- 系统性难度提升: 通过合成新约束、高级定理和跨领域概念增加问题复杂性。
- 严格质量控制: 多阶段过滤管道确保解决方案的正确性、内部多样性、基准数据去污染和网络数据新颖性检查。
- 最先进性能: 在AIME、AMC和MATH等挑战性基准测试中取得顶级结果。
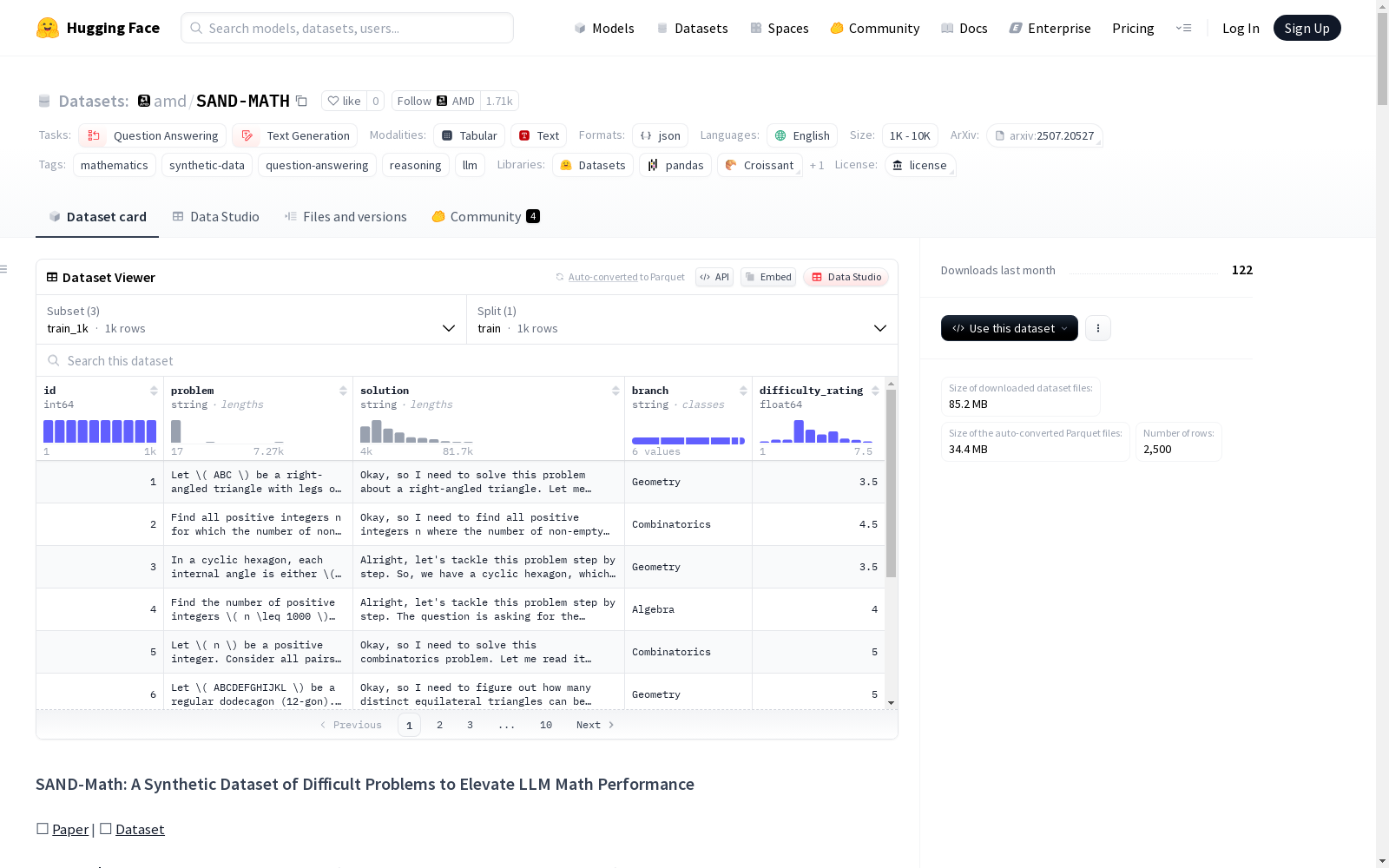
数据集结构
数据分割
train_500: 500样本子集,用于独立微调比较。train_1k: 1000样本的基础SAND-Math数据子集。train_dh_1k: 1000样本的难度提升数据子集。
数据字段
id: 问题IDproblem: 数学问题文本solution: 详细的分步解决方案difficulty_rating: 1-10的难度评分branch: 主要数学分支version: 问题版本(stage1: 原始问题, stage2: 难度提升问题)
使用方法
python from datasets import load_dataset dataset = load_dataset("amd/SAND-MATH", name="train_1k")
训练细节
超参数
| 超参数 | 值 |
|---|---|
| 学习率 | 5.0e-6 |
| LR调度器类型 | cosine |
| 预热比例 | 0.0 |
| 训练周期数 | 10 |
| 梯度累积步数 | 1 |
| 截断长度 | 32,768 |
| Flash Attention实现 | fa2 |
| DeepSpeed策略 | ZeRO-3 |
评估结果
难度分布
SAND-Math的平均难度评分约为6,覆盖更广的复杂度范围。
微调性能
| 训练数据配置 | 数据样本量 | AIME25 | AIME24 | AMC | MATH-500 | 平均 |
|---|---|---|---|---|---|---|
| LIMO + SAND-Math | 817+500 | 48.89 | 57.92 | 92.50 | 94.00 | 73.32 |
难度提升影响
| 数据集 | 数据量 | AIME25 | AIME24 | AMC24 | MATH500 | 平均 |
|---|---|---|---|---|---|---|
| LIMO + SAND-Math (DH) | 817 + 1500 | 49.23 | 60.55 | 93.17 | 94.60 | 74.39 |
许可证
- 类型: ResearchRAIL许可证
- 用途: 学术和研究目的
引用
bibtex @misc{manem2025sandmathusingllmsgenerate, title={SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers}, author={Chaitanya Manem and Pratik Prabhanjan Brahma and Prakamya Mishra and Zicheng Liu and Emad Barsoum}, year={2025}, eprint={2507.20527}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2507.20527}, }
搜集汇总
数据集介绍
构建方式
在数学大语言模型(LLMs)训练数据稀缺的背景下,SAND-MATH数据集通过创新的生成流程构建而成。该流程采用最小约束提示从头生成数学问题,并引入系统化的难度提升方法,通过合成新约束、高级定理和跨领域概念来增加问题复杂性。生成的问题经过多阶段质量过滤,包括自一致性验证、内部多样性评估、基准数据去污染及网络数据新颖性检查,确保数据集的高质量和难度。
特点
SAND-MATH数据集以其高质量和高难度著称,问题难度评分分布在6-10之间,显著高于其他合成数学数据集。其核心特点包括新颖问题生成、系统化难度提升和严格的质量控制。数据集分为基础版本和难度提升版本,涵盖数论、代数等多个数学分支,每个问题均配有详细解答和精细难度评分。
使用方法
SAND-MATH数据集可通过HuggingFace的datasets库便捷加载,支持三种数据分割的访问。用户可单独使用基础问题集,或对比原始问题与难度提升版本,以研究难度变化对模型性能的影响。数据集适用于数学大语言模型的微调,特别适合提升模型在AIME、AMC等高难度数学基准上的表现。加载后可直接用于模型训练,或通过过滤操作提取特定难度或版本的问题进行研究。
背景与挑战
背景概述
SAND-MATH数据集由AMD研究团队于2025年推出,旨在解决大语言模型在数学推理任务中面临的高难度训练数据稀缺问题。该数据集通过创新的问题生成流程,构建了涵盖代数、数论等数学分支的复杂问题集合,其核心创新在于采用难度提升技术,将基础问题转化为更具挑战性的变体。作为首个系统化生成高难度数学问题的开源数据集,SAND-MATH在AIME、AMC等权威数学竞赛基准测试中显著提升了模型性能,为数学推理研究提供了新的数据范式。
当前挑战
构建高难度数学问题数据集面临双重挑战:在领域层面,传统方法难以生成符合竞赛级难度的新颖问题,且人工标注成本极高;在技术层面,需确保生成问题的数学严谨性,避免出现逻辑漏洞或概念混淆。数据集构建过程中,研究团队需攻克问题复杂度量化、跨领域知识融合等关键技术,并通过多阶段过滤机制解决生成内容的自洽性问题。此外,保持生成问题与真实数学竞赛题目在认知难度上的可比性,也是该数据集面临的重要挑战。
常用场景
经典使用场景
在数学推理领域,SAND-MATH数据集通过其高难度和系统性的问题生成机制,成为评估和提升大型语言模型数学解题能力的黄金标准。该数据集特别适用于模型在复杂数学问题上的微调实验,如代数、数论等高级分支的推理任务。研究者可利用其分阶段难度递增的特性,系统性地测试模型从基础到高阶的数学理解能力。
衍生相关工作
该数据集催生了多项重要研究,包括基于难度传播的课程学习框架DiffCurriculum和跨模态数学推理系统MathCross。其核心的难度爬升方法论被拓展至物理、化学等STEM领域,形成了SAND系列数据集。相关成果在NeurIPS和ICLR等顶会上引发了对合成数据质量评估标准的新讨论。
数据集最近研究
最新研究方向
在数学推理与大型语言模型(LLM)的交叉领域,SAND-MATH数据集通过创新的难度提升机制和严格的质量控制流程,为高难度数学问题的生成与求解设立了新标准。该数据集的前沿研究聚焦于如何通过系统性难度升级(Difficulty Hiking)技术,将基础数学问题转化为跨领域、高复杂度的挑战性题目,从而显著提升模型在AIME、AMC等权威数学竞赛基准上的表现。当前研究热点包括探索生成问题与真实竞赛题目间的语义一致性,以及如何利用该数据集增强模型的多步推理能力和定理应用水平。这一工作对突破LLM在复杂数学推理任务中的性能瓶颈具有重要价值,为教育智能和自动解题系统的发展提供了高质量数据支撑。
以上内容由遇见数据集搜集并总结生成


