lance-format/chartqa-lance
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/lance-format/chartqa-lance
下载链接
链接失效反馈官方服务:
资源简介:
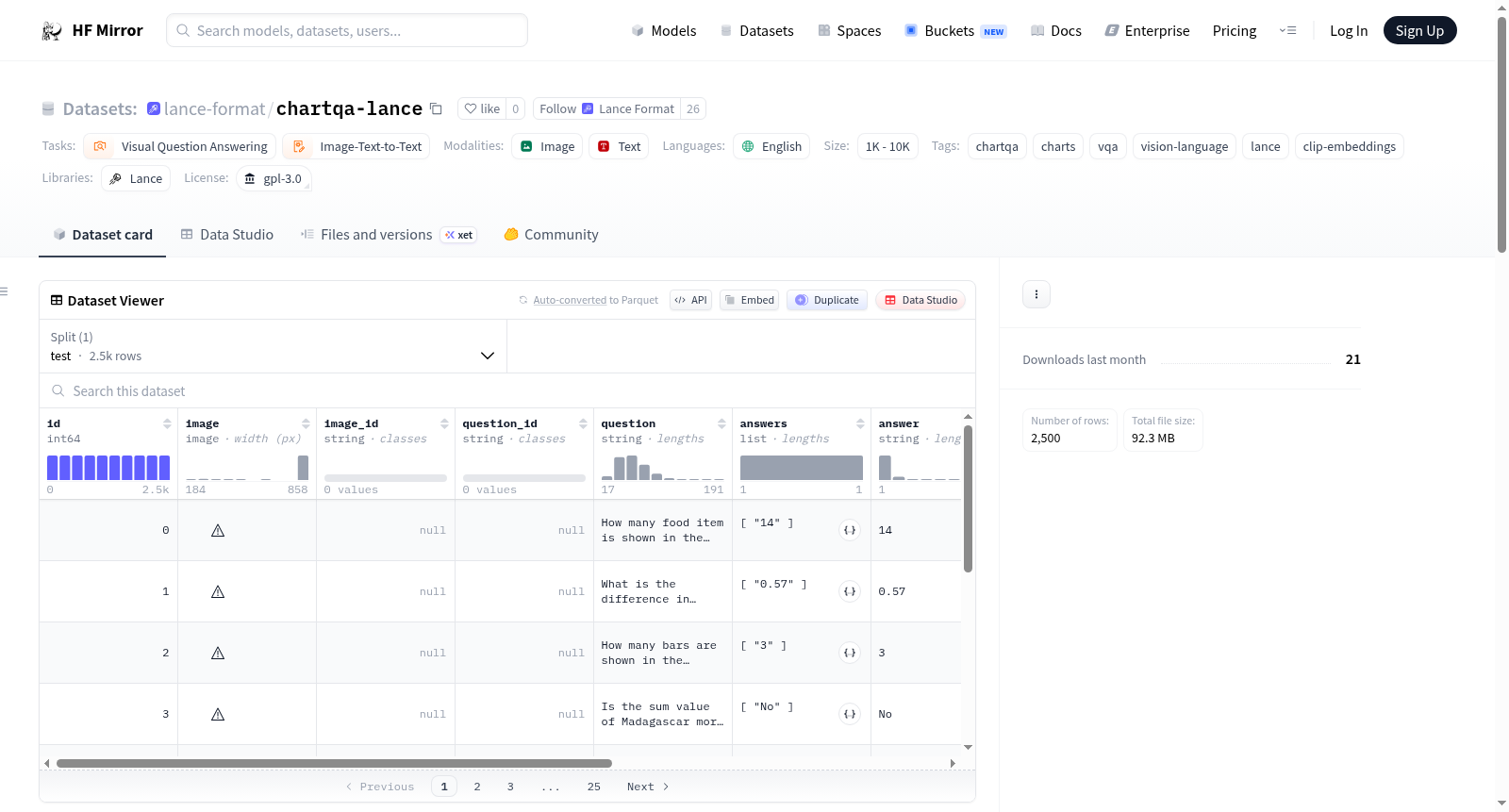
ChartQA(Lance格式)是一个用于视觉问答(VQA)任务的数据集,专注于科学和商业图表,结合了逻辑和视觉推理。该数据集是`lmms-lab/ChartQA`的Lance格式版本,仅包含测试集。数据集包含图表图像、自然语言问题、参考答案等列,并提供了CLIP图像和文本嵌入。数据集适用于视觉语言任务,如图像文本到文本的转换。
ChartQA (Lance Format) is a dataset for Visual Question Answering (VQA) tasks, focusing on scientific and business charts that combine logical and visual reasoning. This dataset is a Lance-formatted version of `lmms-lab/ChartQA` and includes only the test set. It contains columns such as chart images, natural-language questions, reference answers, and provides CLIP image and text embeddings. The dataset is suitable for vision-language tasks like image-text-to-text conversion.
提供机构:
lance-format
搜集汇总
数据集介绍
构建方式
ChartQA-Lance数据集是基于广受认可的ChartQA基准数据集,经过格式转换与特征增强而构建的轻量级版本。原始ChartQA数据集由Masry等人提出,专注于科学图表与商业图表的视觉问答任务,要求模型同时具备逻辑推理与视觉理解能力。本版本从lmms-lab/ChartQA仓库中提取测试集部分,共包含2500个样本,并将每个样本的图表图像、自然语言问题及参考答案整合为标准化列式存储结构。尤为关键的是,通过CLIP模型为图像与问题分别预计算512维的余弦归一化嵌入向量,并直接存储于数据集中,使得下游应用无需重复运行视觉或文本编码器,显著提升了检索与推理效率。
特点
该数据集的核心优势在于其预计算的多模态嵌入与高效索引结构的结合。每个样本均附带图像嵌入与问题嵌入,并基于余弦相似度构建了IVF_PQ索引,支持近似最近邻搜索,极大加速了跨模态检索任务。同时,针对文本字段(问题与答案)构建了倒排全文索引,并针对类型字段构建了位图索引,进一步丰富了筛选与查询能力。所有数据采用Lance格式存储,这是一种专为高性能机器学习工作负载设计的列式格式,支持零拷贝随机访问与流式读取,特别适合大规模多模态场景下的快速迭代实验。
使用方法
使用者可通过Python的Lance库直接加载数据集,利用一行代码创建数据集对象并访问其行数、列名与索引列表。得益于内置的CLIP嵌入与向量索引,用户可基于余弦相似度执行图像或问题级别的近似检索,或使用全文索引对问题与答案进行关键词匹配。此外,数据集的列式存储特性允许按需选择特定字段进行读取,避免不必要的数据加载开销。对于需要训练或验证的场景,可通过原始ChartQA仓库的脚本补充训练与验证集后,以相同格式转换为Lance格式,实现全流程的无缝集成。
背景与挑战
背景概述
图表作为一种高效的数据可视化工具,在科学与商业领域被广泛用于传达复杂信息,而自动理解图表内容并回答相关问题则是视觉与语言交叉研究中的一项重要挑战。ChartQA数据集由Masry等人于2022年在ACL Findings会议上发布,旨在评估模型在兼具视觉感知与逻辑推理的图表问答任务上的表现。该数据集涵盖了多种科学报告与商业图表,问题类型包括人工撰写与自动增强两类,要求模型不仅识别图表中的视觉元素,还需进行数值计算或趋势推断。ChartQA迅速成为视觉语言模型评估的标准基准之一,推动了多模态推理能力的深入研究。其Lance格式版本chartqa-lance由社区维护,提供预计算CLIP嵌入与高效索引,旨在优化大规模检索与训练流程,进一步扩展了该数据集在工业与学术场景中的应用潜力。
当前挑战
ChartQA所聚焦的图表问答任务面临诸多独特挑战。首先,图表中的信息并非以自然文本呈现,而是通过坐标轴、图例、颜色与形状等视觉编码传递,模型需同时解析空间结构与语义含义,这对视觉语言系统的感知与推理能力提出了双重考验。其次,许多问题涉及复杂的逻辑运算,如比例计算、趋势比较或数据聚合,要求模型超越表层视觉识别,具备基础的数学与符号推理能力。在数据集构建过程中,如何确保问题覆盖足够广泛且难度均衡是一大难点,人工标注的多样性需与自动生成的规模性相平衡。此外,图像质量、图表类型分布以及答案格式的规范性也增加了数据清洗与标准化的复杂性。这些挑战共同构成了评估模型在多模态推理领域进展的核心试金石。
常用场景
经典使用场景
ChartQA-lance作为图表视觉问答领域的标准化测评基准,其核心应用在于评估多模态模型对图表中数值信息与视觉语义的联合理解能力。研究者常利用该数据集测试模型在金融报告、科学文献等场景中解读折线图、柱状图及饼图的能力,通过'human'与'augmented'两类问题分别检验模型对自然语言查询的解析深度与对抗性增强样本的鲁棒性。数据集提供的CLIP预计算嵌入向量使得快速检索与跨模态对齐实验成为可能,尤其适用于需要高效向量索引的大规模模型评估场景。
实际应用
在实际工业部署中,ChartQA-lance驱动的模型被广泛集成到商业智能仪表盘与科研数据解读工具中。例如金融分析师可通过自然语言查询季度营收趋势图的同比变化,科研工作者能快速询问实验数据散点图的异常值分布。数据集高兼容性的Lance格式与预构建的IVF_PQ索引,使得在数百毫秒内完成对百万级图表候选集的问答检索成为可能,显著提升了实时数据问答场景的响应效率。
衍生相关工作
该数据集衍生了一系列具有影响力的后续研究,包括ChartT5、ChartTransformer等专用图表推理模型,它们通过引入数值坐标编码器和图转换器结构,在ChartQA的human子集上取得了显著性能突破。此外,基于该数据集的嵌入向量索引特性,催生了如ChartRAG这类将检索增强生成技术应用于图表问答的创新框架,通过将预计算嵌入与外部知识库联动,有效缓解了模型在长尾图表类型上的知识盲区。
以上内容由遇见数据集搜集并总结生成


