community-datasets/sogou_news
收藏Hugging Face2024-06-26 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/community-datasets/sogou_news
下载链接
链接失效反馈官方服务:
资源简介:
Sogou News数据集是来自SogouCA和SogouCS新闻语料库的2,909,551篇新闻文章的混合体,分为5个类别。每个类别的训练样本数量为90,000个,测试样本数量为12,000个。新闻的分类标签由其URL中的域名决定。例如,URL为http://sports.sohu.com的新闻被归类为体育类。数据集中的中文汉字已转换为拼音。
The Sogou News Dataset is a combined collection of 2,909,551 news articles sourced from the SogouCA and SogouCS news corpora, divided into 5 categories. For each category, there are 90,000 training samples and 12,000 test samples. The classification labels of the news articles are determined by the domain name in their respective URLs. For example, a news article with the URL http://sports.sohu.com is categorized as the sports category. All Chinese characters in this dataset have been converted to pinyin.
提供机构:
community-datasets
原始信息汇总
搜狗新闻数据集(Sogou News)
数据集概述
搜狗新闻数据集包含来自搜狗CA和搜狗CS新闻语料库的2,909,551篇新闻文章,分为5个类别。每个类别的训练样本数量为90,000篇,测试样本数量为12,000篇。注意,中文汉字已转换为拼音。新闻的分类标签由其URL中的域名决定。
数据结构
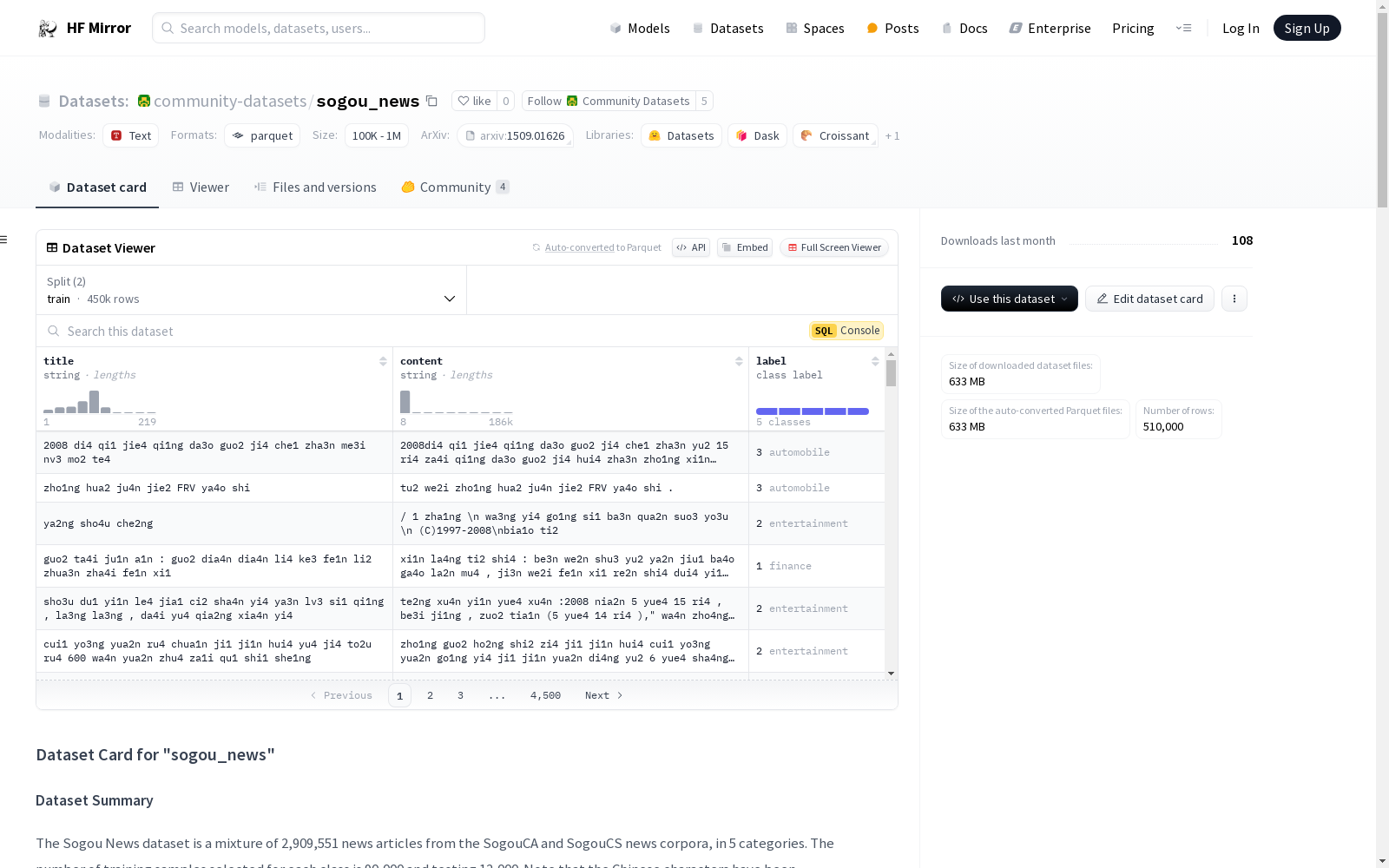
数据实例
以下是一个训练样本的示例:
json { "content": "du2 jia1 ti2 go1ng me3i ri4 ba4o jia4 \n re4 xia4n :010-64438227\n che1 xi2ng ba4o jia4 - cha2 xu2n jie2 guo3 \n pi3n pa2i xi2ng ha4o jia4 ge2 ji1ng xia1o sha1ng ri4 qi1 zha1 ka4n ca1n shu4 pi2ng lu4n ", "label": 3, "title": " da3o ha2ng " }
数据字段
所有分割的数据字段相同:
title:字符串特征。content:字符串特征。label:分类标签,可能的值包括sports(0),finance(1),entertainment(2),automobile(3),technology(4)。
数据分割
| 名称 | 训练集 | 测试集 |
|---|---|---|
| 默认 | 450000 | 60000 |
数据集创建
数据集大小
- 下载的数据集文件大小:384.27 MB
- 生成的数据集大小:1.43 GB
- 总磁盘使用量:1.81 GB
引用信息
bibtex @misc{zhang2015characterlevel, title={Character-level Convolutional Networks for Text Classification}, author={Xiang Zhang and Junbo Zhao and Yann LeCun}, year={2015}, eprint={1509.01626}, archivePrefix={arXiv}, primaryClass={cs.LG} }
贡献者
感谢 @lhoestq, @mariamabarham, @lewtun, @thomwolf 添加此数据集。
搜集汇总
数据集介绍
构建方式
Sogou News数据集的构建基于SogouCA和SogouCS新闻语料库,涵盖了2,909,551篇新闻文章。数据集的分类标签通过新闻URL中的域名确定,例如,URL为http://sports.sohu.com的新闻被归类为体育类别。数据集中的中文内容已被转换为拼音,以适应特定的研究需求。训练集和测试集分别包含450,000和60,000个样本,确保了数据集的均衡性和广泛性。
使用方法
Sogou News数据集适用于多种自然语言处理任务,特别是文本分类和情感分析。研究者可以通过加载数据集的训练和测试分割来训练和评估模型。数据集的结构包括新闻标题、内容和分类标签,这些字段可以直接用于模型的输入和输出。为了充分利用数据集,建议研究者根据具体任务调整数据预处理步骤,并选择合适的模型架构进行训练和验证。
背景与挑战
背景概述
Sogou News数据集是由SogouCA和SogouCS新闻语料库中的2,909,551篇新闻文章组成,涵盖了五个主要类别:体育、财经、娱乐、汽车和技术。该数据集的主要研究人员包括Xiang Zhang、Junbo Zhao和Yann LeCun,其核心研究问题在于文本分类,特别是基于字符级别的卷积网络。该数据集的创建旨在为自然语言处理领域提供一个大规模、多类别的新闻文本分类基准,从而推动相关技术的发展和应用。
当前挑战
Sogou News数据集在构建过程中面临的主要挑战包括:首先,数据集的规模庞大,处理和存储这些数据需要高效的计算资源和存储解决方案。其次,新闻文本的多样性和复杂性使得分类任务变得尤为困难,尤其是在处理不同领域和主题的新闻时。此外,数据集中可能存在的偏见和噪声也是需要解决的重要问题,以确保分类模型的公平性和准确性。
常用场景
经典使用场景
在自然语言处理领域,Sogou News数据集常用于文本分类任务,特别是新闻内容的自动分类。通过训练模型识别新闻标题和内容中的关键信息,该数据集能够有效区分体育、财经、娱乐、汽车和技术等五大类别。这一应用场景不仅提升了新闻分类的准确性,还为后续的文本挖掘和信息检索提供了坚实的基础。
解决学术问题
Sogou News数据集在学术研究中解决了文本分类中的多类别识别问题,特别是在中文语境下的应用。其丰富的样本量和明确的类别标签,为研究者提供了一个标准化的测试平台,促进了中文文本分类算法的发展和优化。此外,该数据集还推动了跨语言文本分类技术的研究,具有重要的学术价值和影响力。
实际应用
在实际应用中,Sogou News数据集被广泛用于新闻推荐系统和内容过滤系统。通过自动分类新闻内容,这些系统能够为用户提供个性化的新闻推荐,提高用户体验。同时,该数据集也在舆情监控和信息安全领域发挥了重要作用,帮助企业和政府机构快速识别和处理敏感信息,确保信息传播的安全性和有效性。
数据集最近研究
最新研究方向
在新闻分类领域,Sogou News数据集的最新研究方向主要集中在多模态融合与深度学习模型的优化上。研究者们致力于通过结合文本、图像和视频等多模态信息,提升新闻分类的准确性和鲁棒性。此外,随着自然语言处理技术的进步,基于Transformer架构的模型,如BERT和GPT系列,被广泛应用于新闻内容理解和分类任务中,显著提高了分类性能。这些研究不仅推动了新闻推荐系统的发展,也为跨领域信息处理提供了新的思路。
以上内容由遇见数据集搜集并总结生成


