egyptian-arabic-hate-speech
收藏Hugging Face2025-05-08 更新2025-05-09 收录
下载链接:
https://huggingface.co/datasets/IbrahimAmin/egyptian-arabic-hate-speech
下载链接
链接失效反馈官方服务:
资源简介:
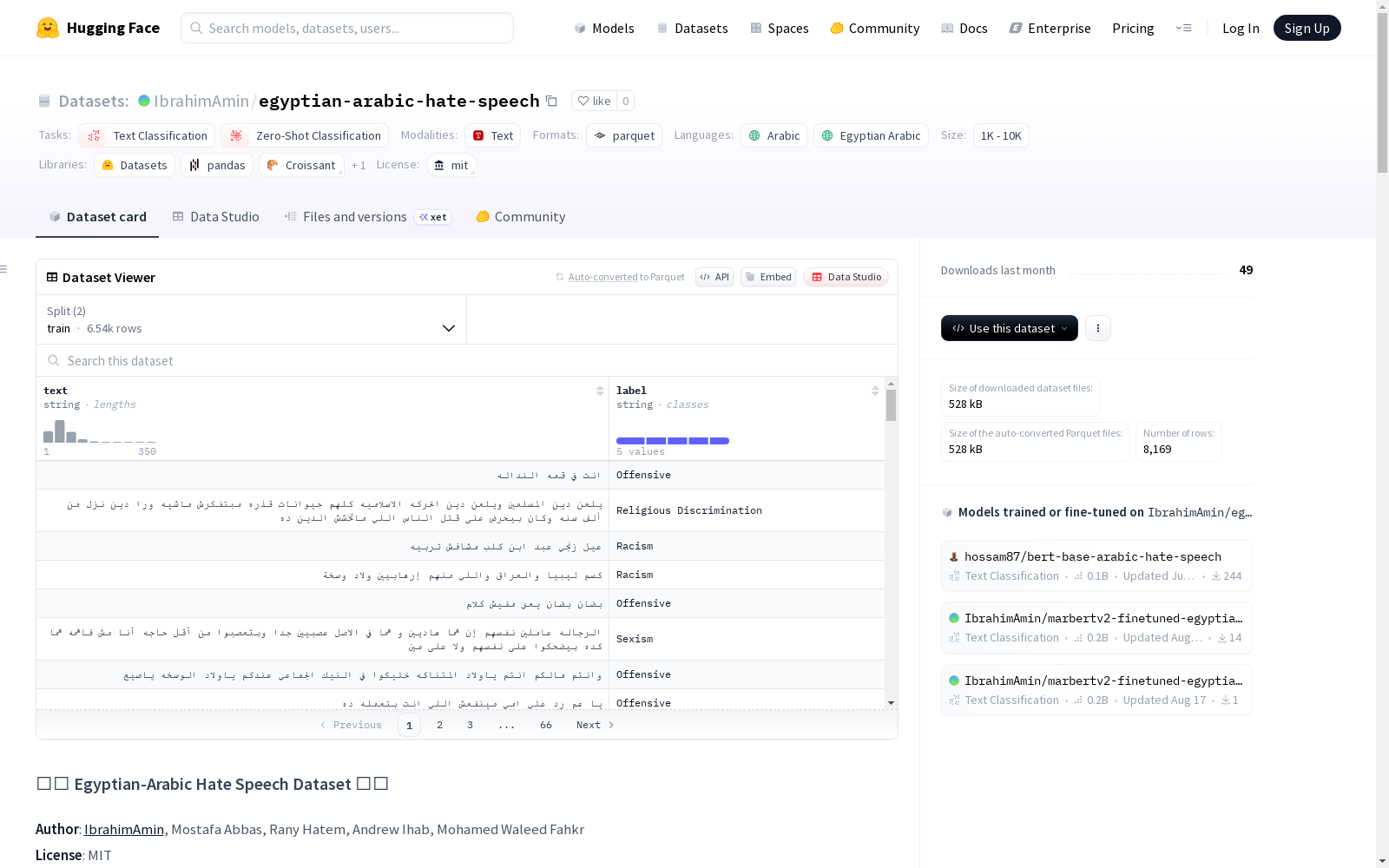
这是一个包含8,169个埃及阿拉伯语文本样本的数据集,用于仇恨言论和攻击性语言分类。样本来源于社交媒体、公开数据集和Google调查。每个样本被标注为中性、攻击性、性别歧视、宗教歧视或种族歧视之一。数据集分为训练集和测试集,确保了类别的平衡分布。
创建时间:
2025-05-02
原始信息汇总
埃及阿拉伯语仇恨言论数据集概述
基本信息
- 作者: IbrahimAmin, Mostafa Abbas, Rany Hatem, Andrew Ihab, Mohamed Waleed Fahkr
- 许可证: MIT
- 论文: Fine-tuning Arabic Pre-Trained Transformer Models for Egyptian-Arabic Dialect Offensive Language and Hate Speech Detection and Classification
- 语言: 阿拉伯语(埃及方言)
数据集摘要
- 样本数量: 8,169个埃及阿拉伯语文本样本
- 标注类别:
- 🟢 中性
- ⚠️ 冒犯性
- 🚺 性别歧视
- ✝️ 宗教歧视
- 🧬 种族歧视
- 数据来源:
- 社交媒体(Facebook、Twitter等)
- 公共数据集
- 自定义Google调查
数据集结构
- 字段:
text(string): 埃及阿拉伯语文本样本label(string): 标注类别
- 数据分割:
- 训练集: 6,535个样本
- 测试集: 1,634个样本
- 总计: 8,169个样本
数据集创建
- 收集来源:
- 现有的阿拉伯语情感和仇恨言论数据集
- 手动整理的埃及社交媒体帖子
- 自定义Google调查(250+条回复)
- 预处理:
- 标准化阿拉伯字符
- 移除tashkeel、tatweel、英语/印地语字符
- 去除特殊字符和停用词
- 数据增强: 用于确保少数类别的平衡
预期用途
- 阿拉伯语社交媒体中的仇恨言论检测
- 阿拉伯语Transformer模型的基准测试
- 中东和北非地区的NLP公平性研究
使用示例
python from datasets import load_dataset
dataset = load_dataset("IbrahimAmin/egyptian-arabic-hate-speech")
访问样本
sample = dataset["train"][3453] print(sample["text"]) print(sample["label"])
局限性
- 数据集专注于埃及方言,可能不适用于其他阿拉伯方言
- 标注可能存在主观性导致的偏见
引用
bibtex @INPROCEEDINGS{10009167, author={Ahmed, Ibrahim and Abbas, Mostafa and Hatem, Rany and Ihab, Andrew and Fahkr, Mohamed Waleed}, booktitle={2022 20th International Conference on Language Engineering (ESOLEC)}, title={Fine-tuning Arabic Pre-Trained Transformer Models for Egyptian-Arabic Dialect Offensive Language and Hate Speech Detection and Classification}, year={2022}, volume={20}, pages={170-174}, doi={10.1109/ESOLEC54569.2022.10009167} }
许可证
- 许可证类型: MIT许可证
- 许可证链接: https://opensource.org/licenses/MIT
搜集汇总
数据集介绍
构建方式
在阿拉伯语自然语言处理领域,埃及阿拉伯语仇恨言论数据集的构建采用了多源数据融合策略。研究团队从社交媒体平台、现有阿拉伯语数据集以及定制化问卷调查三个维度收集原始语料,通过人工标注将8169条埃及方言文本划分为中立、冒犯性言论、性别歧视、宗教歧视和种族歧视五类标签。为确保数据质量,实施了字符标准化、去除变音符号与特殊字符等预处理流程,并对少数类别采用数据增强技术以维持类别平衡。
使用方法
基于Transformers架构的自然语言处理研究可借助HuggingFace生态系统便捷加载该数据集。通过调用load_dataset函数直接获取经标准化的数据分割,研究人员能够快速构建埃及方言仇恨言论检测 pipeline。该资源特别适用于阿拉伯语预训练模型的微调实验,为社交媒体内容审核、自然语言处理公平性研究等应用场景提供关键数据支撑,使用时需注意其方言特异性可能对泛化能力产生的影响。
背景与挑战
背景概述
埃及阿拉伯语仇恨言论数据集由Ibrahim Ahmed等研究人员于2022年创建,隶属于阿拉伯科学技术与海运学院计算机工程专业的毕业设计项目。该数据集聚焦于埃及方言的社交媒体文本分析,旨在解决阿拉伯语自然语言处理中方言多样性带来的技术难题。通过收集来自社交媒体平台和定制化调查的8,169条标注样本,该资源为中东地区的内容审核系统提供了重要的基准数据,推动了跨文化语境下人工智能伦理研究的发展。
当前挑战
在领域问题层面,该数据集需应对埃及方言特有的语言变体与文化隐喻,这对传统阿拉伯语模型的特征提取能力构成严峻考验。构建过程中面临双重挑战:其一,标注工作需克服仇恨言论主观性带来的标注一致性难题;其二,针对性别歧视、宗教歧视等少数类别的数据不平衡问题,研究团队不得不采用数据增强技术以维持分类器的鲁棒性。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,该数据集为埃及阿拉伯方言的仇恨言论检测提供了关键资源。研究者通常利用其精细标注的文本样本,训练和评估分类模型以识别社交媒体中的冒犯性内容、性别歧视、宗教歧视及种族主义言论。该数据集凭借其平衡的类别分布和方言特性,成为阿拉伯语内容安全研究的重要基准。
解决学术问题
该数据集有效解决了阿拉伯语方言场景下仇恨言论自动识别的学术难题。通过提供埃及方言的标注语料,弥补了标准阿拉伯语与方言间语义差异导致的研究空白。其多类别标注体系助力学者深入探究仇恨言论的细粒度特征,并为跨文化语境下的自然语言处理公平性研究提供了数据支撑。
实际应用
在实际应用层面,该数据集为中东地区社交媒体平台的内容审核系统开发提供了核心技术支持。基于该数据集训练的模型可自动识别埃及方言中的有害内容,辅助平台实施高效的内容治理。同时,该资源也被广泛应用于政府舆情监测、数字人权保护等社会管理领域,促进线上空间的文明交流。
数据集最近研究
最新研究方向
在阿拉伯语自然语言处理领域,埃及阿拉伯语仇恨言论数据集正推动方言特异性内容审核的前沿探索。当前研究聚焦于利用预训练Transformer模型进行细粒度分类,通过对抗训练和数据增强技术解决方言变体与标注主观性带来的泛化挑战。随着中东地区数字治理需求增长,该数据集已成为评估模型跨文化偏见的重要基准,为构建公平包容的社交媒体生态系统提供关键支撑。
以上内容由遇见数据集搜集并总结生成


