Perceive Anything Model (PAM) 数据集
收藏arXiv2025-06-06 更新2025-06-07 收录
下载链接:
https://Perceive-Anything.github.io
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为Perceive Anything Model (PAM) 数据集,由香港中文大学、香港大学、香港理工大学和北京大学的研究团队创建。数据集包含150万个图像和视频区域语义标注,涵盖了丰富的视觉特征、定位和语义先验信息。数据集的创建过程使用了先进的视觉语言模型(如GPT-4o)和人工专家验证,以确保高质量和多样性。该数据集旨在解决图像和视频中的区域理解问题,如预测类别、解释定义和功能,以及生成详细描述。数据集支持多语言响应,包括英语和中文版本。
This dataset, named the Perceive Anything Model (PAM) Dataset, was developed by research teams from The Chinese University of Hong Kong, The University of Hong Kong, The Hong Kong Polytechnic University, and Peking University. It contains 1.5 million semantic annotations for image and video regions, covering rich visual features, localization information, and semantic prior knowledge. The construction of this dataset utilized cutting-edge vision-language models (e.g., GPT-4o) and underwent manual expert verification to guarantee high quality and diversity. This dataset aims to address regional understanding tasks in images and videos, such as category prediction, definition and function explanation, and detailed description generation. It supports multilingual responses, including English and Chinese versions.
提供机构:
香港中文大学, 香港大学, 香港理工大学, 北京大学
创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
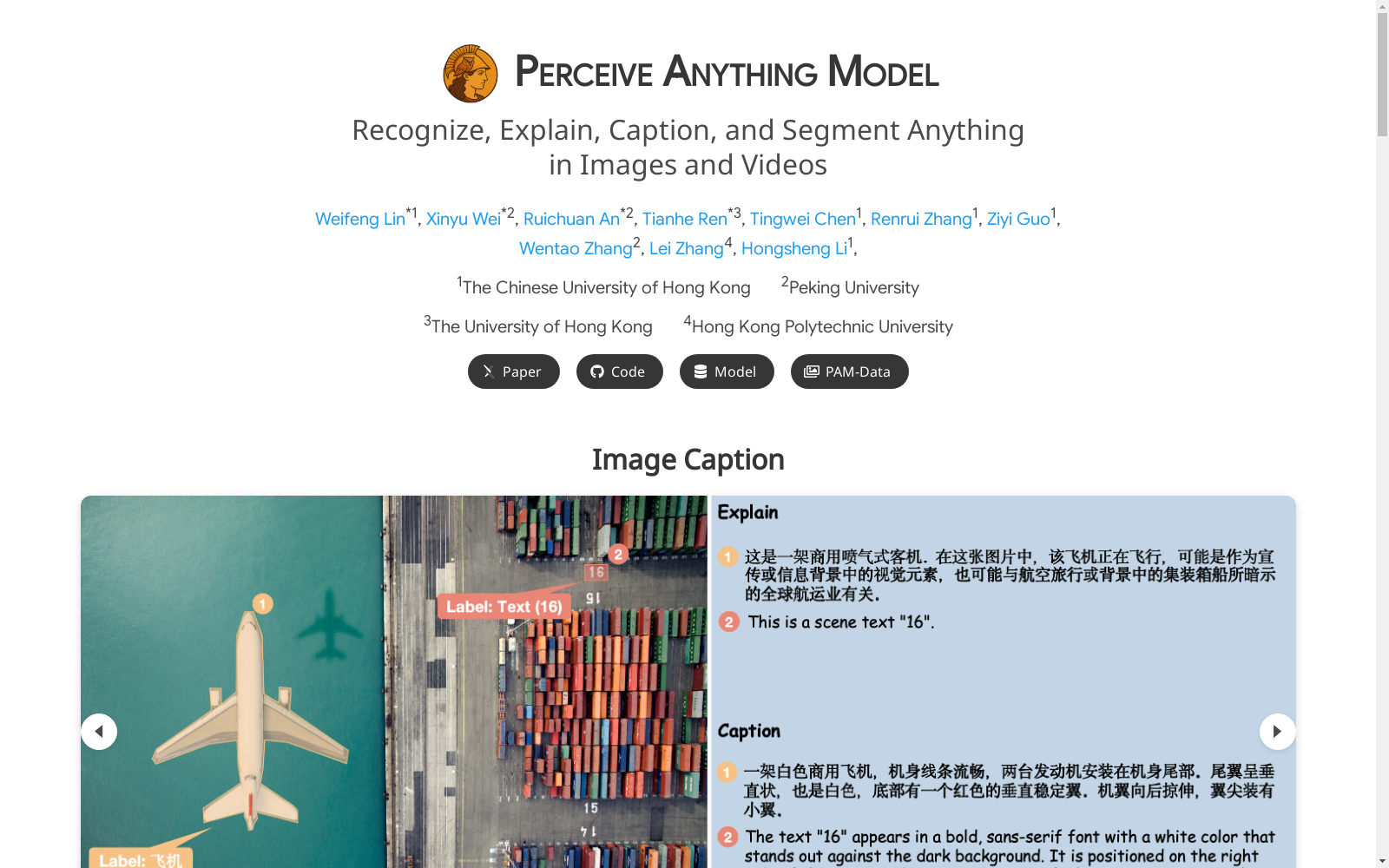
Perceive Anything Model (PAM) 数据集的构建采用了先进的数据精炼与增强流程,结合了大型视觉语言模型(如GPT-4o)和人工专家验证。具体步骤包括:首先,从公开的实例检测、分割和场景文本识别数据集中收集数据;其次,利用Set-of-Mask (SoM)方法识别感兴趣区域,并通过原始标注引导模型生成多维度语义输出,如细粒度类别标签、上下文感知定义和详细描述;最后,通过规则过滤和人工审核确保数据质量。对于视频数据,采用故事板驱动的标注扩展方法,通过关键帧采样和LLM辅助生成时间感知的区域级描述。
特点
PAM数据集具有三大显著特点:一是广泛的语义粒度,涵盖从粗粒度(类别、定义)到细粒度(详细描述)的多层次标注;二是首创的区域级流式视频标注,支持对视频中特定区域的连续跟踪与描述;三是双语标注(英文和中文),增强了模型的跨语言响应能力。数据集包含150万图像区域语义三元组和60万视频区域语义三元组,为模型提供了丰富的训练资源。
使用方法
PAM数据集支持多种视觉理解任务的使用方法。用户可通过视觉提示(如点击、框选或掩码)指定感兴趣区域,模型将同步生成区域掩码并输出多维度语义信息,包括类别识别、定义解释、功能说明及详细描述。对于视频数据,用户可灵活指定解码时间戳,模型将生成指定时间区间内的区域描述。此外,数据集支持流式视频处理,通过分段处理与历史信息传递实现连续描述生成。模型采用轻量化设计,推理速度较现有方法快1.2-2.4倍,适用于实际部署场景。
背景与挑战
背景概述
Perceive Anything Model (PAM) 数据集由香港中文大学、香港大学、香港理工大学和北京大学的研究团队于2025年提出,旨在推动区域级视觉理解的研究。该数据集基于强大的分割模型SAM 2,结合大型语言模型(LLMs),能够同时实现对象分割和多样化的语义输出生成,包括类别识别、标签定义、功能解释和详细描述。PAM数据集的构建不仅填补了现有视觉语言模型在细粒度区域理解上的空白,还为图像和视频中的多维度语义分析提供了重要支持。其影响力体现在为计算机视觉领域提供了一个高效、轻量级的解决方案,显著提升了区域级视觉任务的性能。
当前挑战
PAM数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,PAM旨在解决图像和视频中区域级语义理解的复杂性问题,包括如何在多模态环境下实现高效的语义分割和描述生成,以及如何处理视频中的时序信息以支持流式视频描述。在构建过程中,挑战包括如何从现有粗粒度标注数据中提取高质量的细粒度语义信息,如何设计有效的数据增强流程以支持多语言(中英文)输出,以及如何确保生成的标注在时间和空间上的一致性。此外,数据集中流式视频标注的构建是一项创新性工作,需要克服视频事件分割和连续描述生成的难题。
常用场景
经典使用场景
Perceive Anything Model (PAM) 数据集在计算机视觉领域被广泛应用于细粒度的视觉理解任务。该数据集通过结合强大的分割模型SAM 2和大语言模型(LLMs),能够同时实现对象分割和多样化的语义输出生成。研究人员利用PAM数据集进行区域级别的图像和视频理解,包括对象分类、定义解释、上下文功能描述以及详细字幕生成。该数据集特别适用于需要同时处理视觉定位和语义理解的多模态任务,为视觉-语言模型的研究提供了丰富的实验数据。
实际应用
在实际应用场景中,PAM数据集支持多种有价值的视觉理解任务。在智能监控领域,可用于实时分析视频中特定对象的行为和状态变化;在辅助技术中,能够为视障人士提供详细的周围环境描述;在内容审核方面,可精确识别和解释图像视频中的敏感内容。特别值得注意的是,PAM首次构建了区域级流式视频字幕数据,使模型能够支持视频流中特定区域的连续描述,这一特性在实时视频分析和交互式应用中具有重要价值。
衍生相关工作
PAM数据集衍生了一系列重要的相关研究工作。基于该数据集的核心思想,研究人员开发了多种区域级视觉语言模型,如结合视觉提示的Draw-and-Understand模型、支持多概念个性化的MC-LLAVA等。在视频理解方向,PAM启发了如VideoLLM-online等流式视频理解模型的开发。此外,PAM提出的语义感知器架构和数据增强方法也被广泛应用于后续的视觉-语言模型研究中,成为区域级视觉理解领域的重要基准。
以上内容由遇见数据集搜集并总结生成


