Kubric; HUMOTO
收藏arXiv2026-04-03 更新2026-04-05 收录
下载链接:
https://void-model.github.io
下载链接
链接失效反馈官方服务:
资源简介:
该研究构建了基于Kubric物理仿真引擎和HUMOTO人体运动捕捉的双模态数据集,旨在解决动态物体移除后的物理一致性推理问题。Kubric数据集包含1900组刚性物体交互视频对,模拟碰撞、坠落等场景;HUMOTO提供4500组人体-物体互动数据,通过随机化纹理和摄像机轨迹增强泛化能力。数据集通过精确标注物体移除前后的时空变化,为视频编辑模型提供物理因果关系的监督信号,主要应用于影视特效和智能视频编辑领域,推动生成模型在动态场景中的因果推理能力。
This study constructs a bimodal dataset based on the Kubric physics simulation engine and HUMOTO human motion capture, aiming to solve the problem of physical consistency reasoning after dynamic object removal. The Kubric dataset includes 1,900 rigid object interaction video pairs, simulating scenarios such as collisions and falls; the HUMOTO dataset provides 4,500 sets of human-object interaction data, enhancing generalization capability by randomizing textures and camera trajectories. The dataset provides supervision signals of physical causal relationships for video editing models through precise annotations of spatiotemporal changes before and after object removal. It is mainly applied in the fields of visual effects and intelligent video editing, promoting the causal reasoning capability of generative models in dynamic scenes.
提供机构:
Netflix; INSAIT, 索非亚大学·圣克莱门特奥赫里德斯基
创建时间:
2026-04-03
搜集汇总
数据集介绍
构建方式
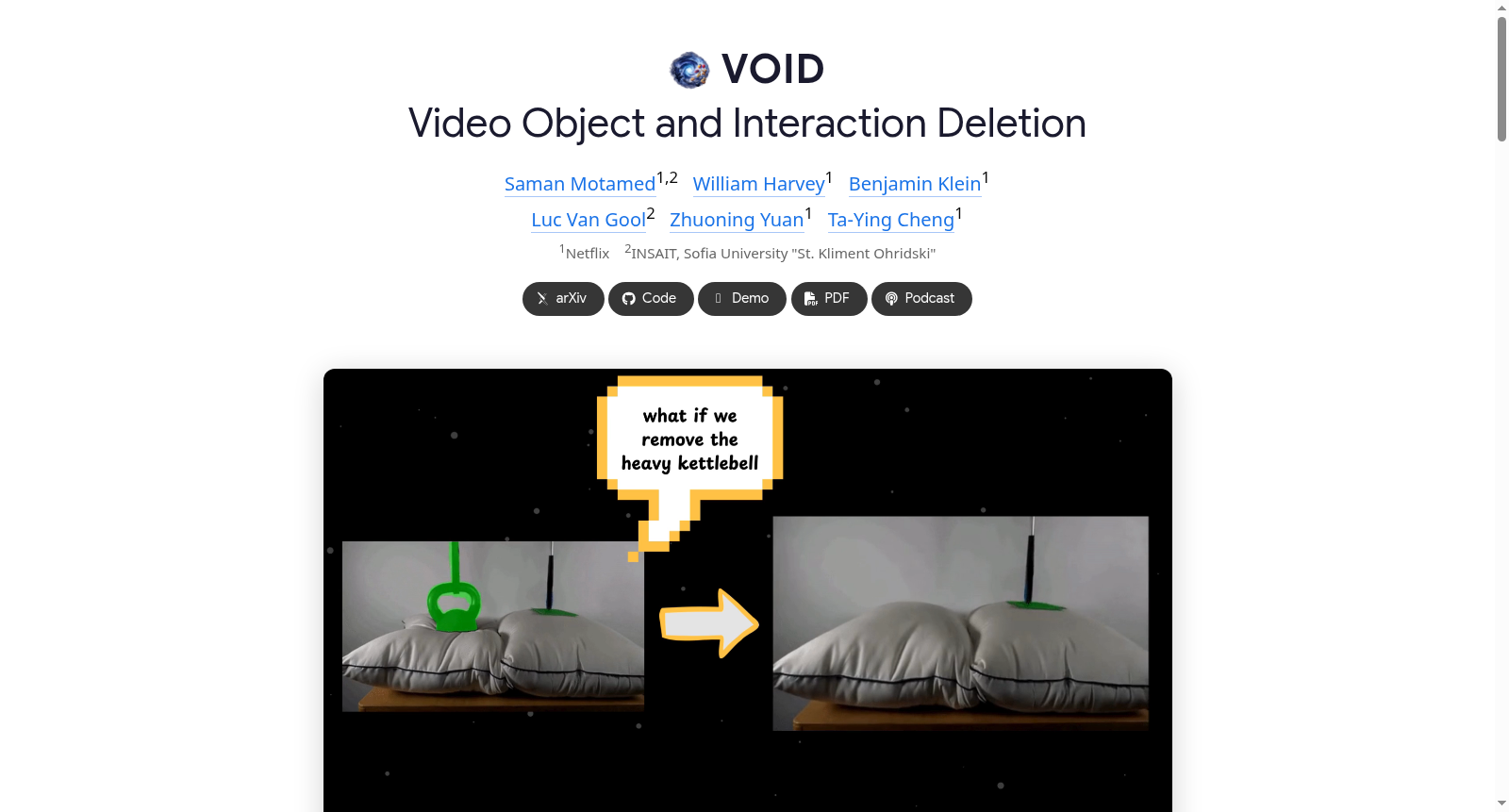
在视频对象移除领域,现有方法常局限于处理光影等表观效应,难以应对物体间复杂的物理交互。为此,VOID数据集通过整合Kubric物理仿真引擎与HUMOTO人体动作捕捉数据,构建了大规模的反事实视频对。具体而言,Kubric部分模拟刚体动力学场景,通过移除特定物体并重新仿真生成物理一致的交互序列;HUMOTO部分则聚焦于人体与物体的关节互动,通过渲染引擎生成包含动态操控的对比视频。数据生成过程中随机化摄像机轨迹与纹理,以增强模型对场景动态的解耦能力,最终形成了涵盖多样物理交互的合成监督数据。
特点
VOID数据集的核心特点在于其专注于物理交互的反事实建模。与仅关注阴影、反射等表观效应的传统数据集不同,该数据集强调物体移除后引发的连锁动力学变化,如支撑消失导致的坠落、碰撞避免等复杂场景。数据集通过精细的四元掩码标注,明确区分待移除物体、受影响的区域及其重叠部分,为模型提供了丰富的结构引导。此外,合成数据与真实场景间的泛化能力显著,使训练后的模型能够推理未见过的物理效应,展现了高层次因果推理的潜力。
使用方法
使用VOID数据集时,首先需通过用户提供的稀疏点击生成初始对象掩码,随后利用视觉语言模型分析场景,预测受移除物体影响的区域,并生成指导性的四元掩码。该掩码与输入视频共同馈入基于扩散变换器的VOID框架,进行两阶段生成:第一阶段合成反事实运动轨迹,第二阶段可选地通过光流扭曲噪声稳定对象结构,以提升时间一致性。评估时,可采用人工偏好研究、视觉语言模型自动评分及传统视频质量指标,综合衡量模型在物理合理性与视觉保真度方面的表现。
背景与挑战
背景概述
视频对象移除技术旨在从视频序列中消除指定目标,同时保持场景的视觉连贯性与物理合理性。传统方法主要关注修复被遮挡的背景区域以及处理阴影、反射等外观层面的伪影,但在处理涉及复杂物理交互(如碰撞、支撑关系)的动态场景时,往往无法生成符合因果逻辑的对抗事实结果。VOID框架由Netflix与INSAIT的研究团队于2026年提出,其核心研究问题在于如何使视频编辑模型具备高阶因果推理能力,从而在移除对象后能够准确模拟场景的动态演变。该工作通过构建基于Kubric物理引擎与HUMOTO人体动作捕捉数据集的全新对抗事实视频对,为视频生成领域引入了物理感知的世界建模范式,显著推动了视频编辑从像素修复向场景动态推理的范式转变。
当前挑战
VOID数据集及其方法所应对的核心领域挑战,在于实现物理可信的视频对象与交互删除。这要求模型不仅需完成目标对象的视觉抹除,更须对其缺失所引发的连锁物理效应进行准确预测与合成,例如被支撑物体的坠落轨迹改变或预期碰撞的避免。构建过程中的主要挑战体现在数据制备与模型引导两个维度。在数据层面,获取真实世界中对象移除前后精确配对的对抗事实视频极为困难,研究团队需借助Kubric与HUMOTO合成数据,并通过严谨的物理仿真与渲染来生成包含复杂动力学交互的监督信号。在方法层面,如何将高阶的因果推理需求转化为模型可理解的像素级引导(如四元掩码),并利用视觉语言模型的世界知识动态推断受影响区域,构成了模型设计与推理流程中的关键难题。
常用场景
经典使用场景
在视频生成与编辑领域,物理一致性的对象移除是长期存在的挑战。VOID框架通过Kubric和HUMOTO数据集构建了物理交互感知的训练范式,其最经典的使用场景在于处理具有复杂动力学交互的对象移除任务。例如在多米诺骨牌序列中移除中间骨牌时,模型需要推理后续骨牌应保持静止的因果逻辑;在移除手持物体的操作者时,模型需模拟物体自由下落的自然过程。这种场景超越了传统视频修复仅关注外观层面补全的局限,要求模型具备对物理世界因果关系的深层理解能力。
解决学术问题
该数据集系统性地解决了视频编辑领域三个核心学术问题:传统方法无法处理对象间动力学交互的物理一致性修正,现有模型缺乏对反事实场景的推理能力,以及训练数据中物理交互监督信号的缺失。通过Kubric提供的刚体动力学仿真和HUMOTO提供的人体-物体交互数据,研究者首次获得了大规模、高质量的反事实视频对,使得模型能够学习对象移除后的场景演化规律。这种数据构建方式为视频生成模型注入了物理直觉,推动了从外观修复到因果推理的范式转变。
衍生相关工作
基于该数据集的创新范式,学术界衍生出多个重要研究方向。在模型架构层面,出现了结合视觉语言模型进行场景分析的混合推理框架,如扩展掩码生成技术和四元掩码条件机制。训练策略上发展出两阶段去噪流程,通过运动轨迹对齐的噪声采样提升时序一致性。评估体系也得到革新,研究者建立了结合人类偏好研究、VLM自动评判和多维度物理合理性指标的复合评估协议。这些工作共同推动了视频编辑模型从感知智能向认知智能的演进,为具身智能和世界模型研究提供了重要技术基础。
以上内容由遇见数据集搜集并总结生成


