myanmar_cele_voices
收藏Hugging Face2025-06-21 更新2025-06-22 收录
下载链接:
https://huggingface.co/datasets/freococo/myanmar_cele_voices
下载链接
链接失效反馈官方服务:
资源简介:
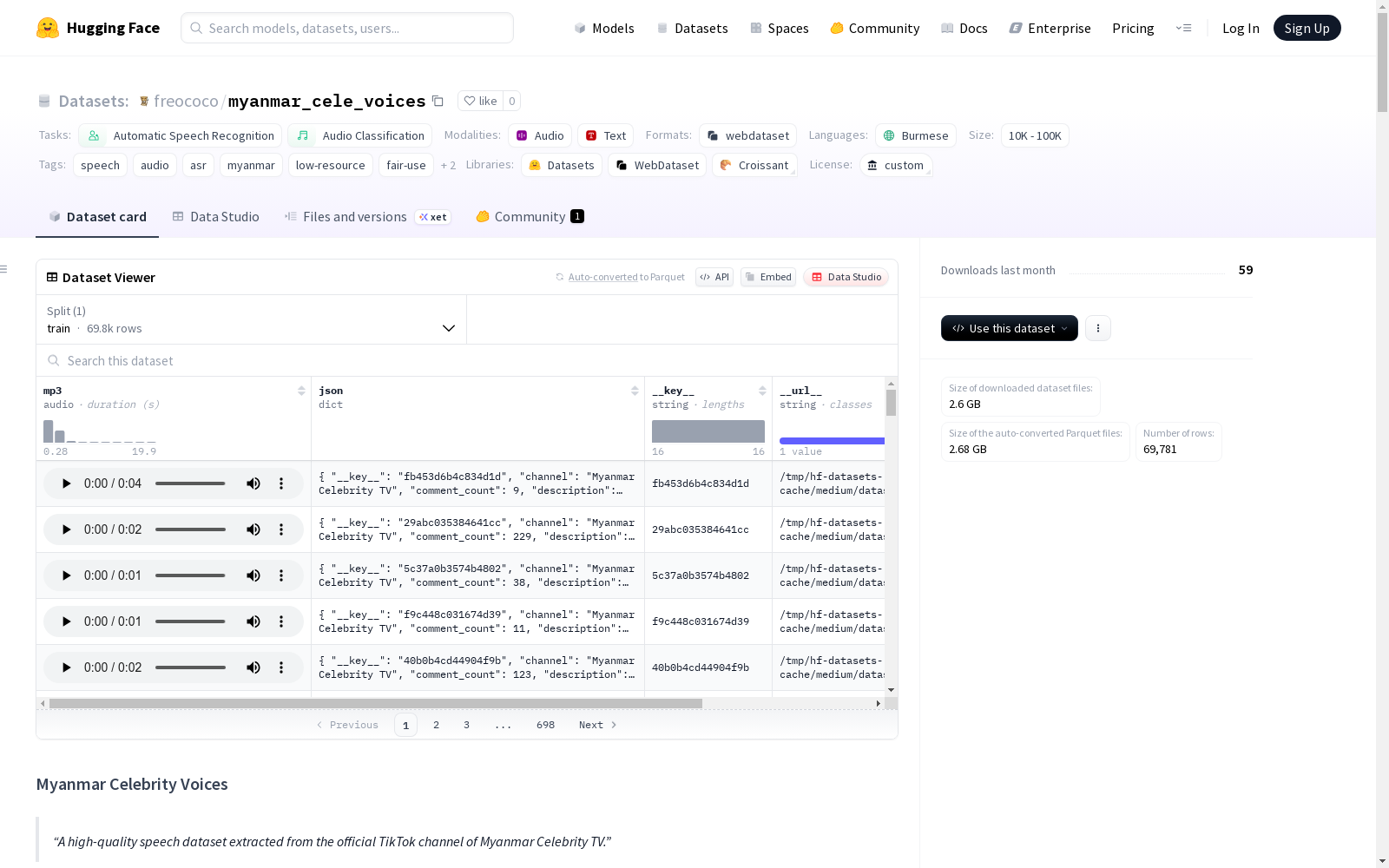
Myanmar Celebrity Voices是一个包含69,781个短音频片段(约46小时)的数据集,这些音频片段从缅甸明星电视官方TikTok频道中提取。数据集包含了清晰的缅甸语对话,适用于自动语音识别和音频分类任务。
创建时间:
2025-06-19
原始信息汇总
数据集概述:Myanmar Celebrity Voices
基本信息
- 名称:Myanmar Celebrity Voices
- 类型:语音数据集
- 语言:缅甸语 (my)
- 标签:speech, audio, asr, myanmar, low-resource, fair-use, tikTok, webdataset
- 任务类别:automatic-speech-recognition, audio-classification
- 许可证:custom (非商业研究/教育用途)
- 许可证链接:https://huggingface.co/datasets/freococo/myanmar_cele_voices/blob/main/LICENSE
数据内容
- 来源:缅甸名人电视官方TikTok频道
- 数据量:69,781个短音频片段(≈46小时)
- 内容类型:
- 缅甸顶级电影演员访谈
- 歌手/喜剧演员幕后花絮
- 粉丝问答/活动剪辑/生活评论
- 特点:自然、情感丰富的缅甸流行文化口语
数据集结构
- 格式:WebDataset格式的
.tar.gz压缩包 - 文件组成:
.mp3:音频片段.json:包含以下元数据:- 文件名/原始文件
- 转录文本
- 持续时间
- 视频URL
- 观看/点赞/评论数
- 频道/上传日期
- 标题/描述/标签
- 缩略图链接
使用方式
Hugging Face Datasets加载示例
python from datasets import load_dataset ds = load_dataset( "freococo/myanmar_cele_voices", data_files="train/myanmar_cele_voices_000001.tar.gz", split="train", streaming=True )
本地下载
bash wget https://huggingface.co/datasets/freococo/myanmar_cele_voices/resolve/main/data/myanmar_cele_voices_000001.tar.gz
局限性
- 转录错误率:约30%片段存在自动字幕错误
- 未人工校正:原始自动字幕数据
- 语音多样性:可能包含背景声/音乐叠加
- 方言代表性:主要为标准缅甸语
许可信息
- 允许用途:非商业研究/教育/语言保护
- 禁止用途:未经许可的商业用途
- 原始内容来源:https://www.tiktok.com/@myanmarcelebritytv
引用格式
bibtex @misc{freococo2025myanmarcelebrityvoices, title = {Myanmar Celebrity Voices: A WebDataset for Burmese ASR and Speech Research}, author = {freococo}, year = {2025}, howpublished = {Hugging Face Datasets}, url = {https://huggingface.co/datasets/freococo/myanmar_cele_voices} }
搜集汇总
数据集介绍
构建方式
Myanmar Celebrity Voices数据集源自缅甸名人电视官方TikTok频道的公开视频,通过系统化的数据采集与处理流程构建而成。研究者从短视频中提取了69,781个音频片段,总时长约46小时,采用自动化字幕生成技术获取对应文本转录。每个数据样本包含MP3音频文件和JSON格式的元数据,其中详细记录了视频标题、观看量、点赞数等丰富上下文信息。数据集采用WebDataset标准打包为.tar.gz压缩格式,确保高效存储与流式读取。
使用方法
研究者可通过Hugging Face Datasets库直接流式加载数据集,或下载.tar.gz文件使用WebDataset进行处理。数据集兼容PyTorch训练流程,每个样本包含音频文件及对应的JSON元数据。典型应用场景包括缅甸语自动语音识别(ASR)模型训练、语音分类任务等。使用建议配合人工校对或半监督微调以提升模型性能。根据许可协议,该数据集仅限非商业研究用途,需遵守原始内容版权所有者的相关规定。
背景与挑战
背景概述
缅甸名人语音数据集(Myanmar Celebrity Voices)由研究人员freococo于2025年构建,旨在为缅甸语这一低资源语言提供高质量的语音数据支持。该数据集源自缅甸名人电视官方TikTok频道的公开视频,包含69,781条短音频片段,总计约46小时,涵盖了缅甸顶级演员、歌手及喜剧演员的访谈、幕后花絮等内容。这些数据不仅捕捉了缅甸现代流行文化的自然表达,还为自动语音识别(ASR)和语音分类任务提供了丰富的语料库。该数据集的发布填补了缅甸语语音数据的空白,为相关领域的研究奠定了重要基础。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题方面,缅甸语作为低资源语言,其语音数据的稀缺性限制了ASR模型的性能提升,且方言多样性不足可能导致模型泛化能力受限;构建过程方面,数据依赖TikTok自动生成的字幕,约30%的转录存在错误,包括拼写不一致、标点符号误用等问题,同时缺乏人工校对环节。此外,音频中可能包含背景噪音、音乐叠加等干扰因素,进一步增加了数据清洗和模型训练的难度。
常用场景
经典使用场景
在低资源语言技术开发领域,Myanmar Celebrity Voices数据集为缅甸语自动语音识别(ASR)系统提供了关键训练素材。其46小时的真实名人访谈音频,覆盖了缅甸流行文化中自然对话的丰富声学特征,常被用于构建端到端语音识别模型的声学建模单元。研究者特别看重其包含的情感表达和即兴对话特性,这能有效提升ASR系统对非正式口语的识别鲁棒性。
解决学术问题
该数据集直接应对缅甸语在计算语言学中的资源匮乏问题,填补了东南亚语言语音数据集的空白。通过提供带自动转录的标准化音频片段,解决了传统缅甸语ASR研究依赖人工标注的高成本瓶颈。其嵌入的视频元数据更支持多模态学习研究,为探究社交媒体语音与文本对齐机制提供了实验基础。
实际应用
在缅甸本土化智能语音产品开发中,该数据集支撑着语音助手、实时字幕生成等应用的模型训练。媒体机构利用其丰富的名人语音特征开发声纹识别系统,用于内容自动化分类。教育科技公司则借助数据集中的标准发音样本,构建缅甸语发音评估工具,辅助语言学习者矫正语调韵律。
数据集最近研究
最新研究方向
在低资源语言处理领域,缅甸语(Burmese)的自动语音识别(ASR)技术正逐渐成为研究热点。Myanmar Celebrity Voices数据集的推出,为这一领域注入了新的活力。该数据集不仅包含了大量自然、真实的缅甸语语音片段,还涵盖了丰富的文化背景信息,为研究者提供了宝贵的资源。当前,前沿研究主要集中在如何利用这一数据集提升ASR模型在低资源语言环境下的表现,特别是在处理自动转录错误和方言多样性方面的挑战。此外,该数据集还被用于探索多模态学习,结合音频和文本信息,进一步提升语音识别的准确性。这一研究不仅对缅甸语的语音技术发展具有重要意义,也为其他低资源语言的处理提供了可借鉴的解决方案。
以上内容由遇见数据集搜集并总结生成


