CL-bench
收藏Hugging Face2026-02-06 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/tencent/CL-bench
下载链接
链接失效反馈官方服务:
资源简介:
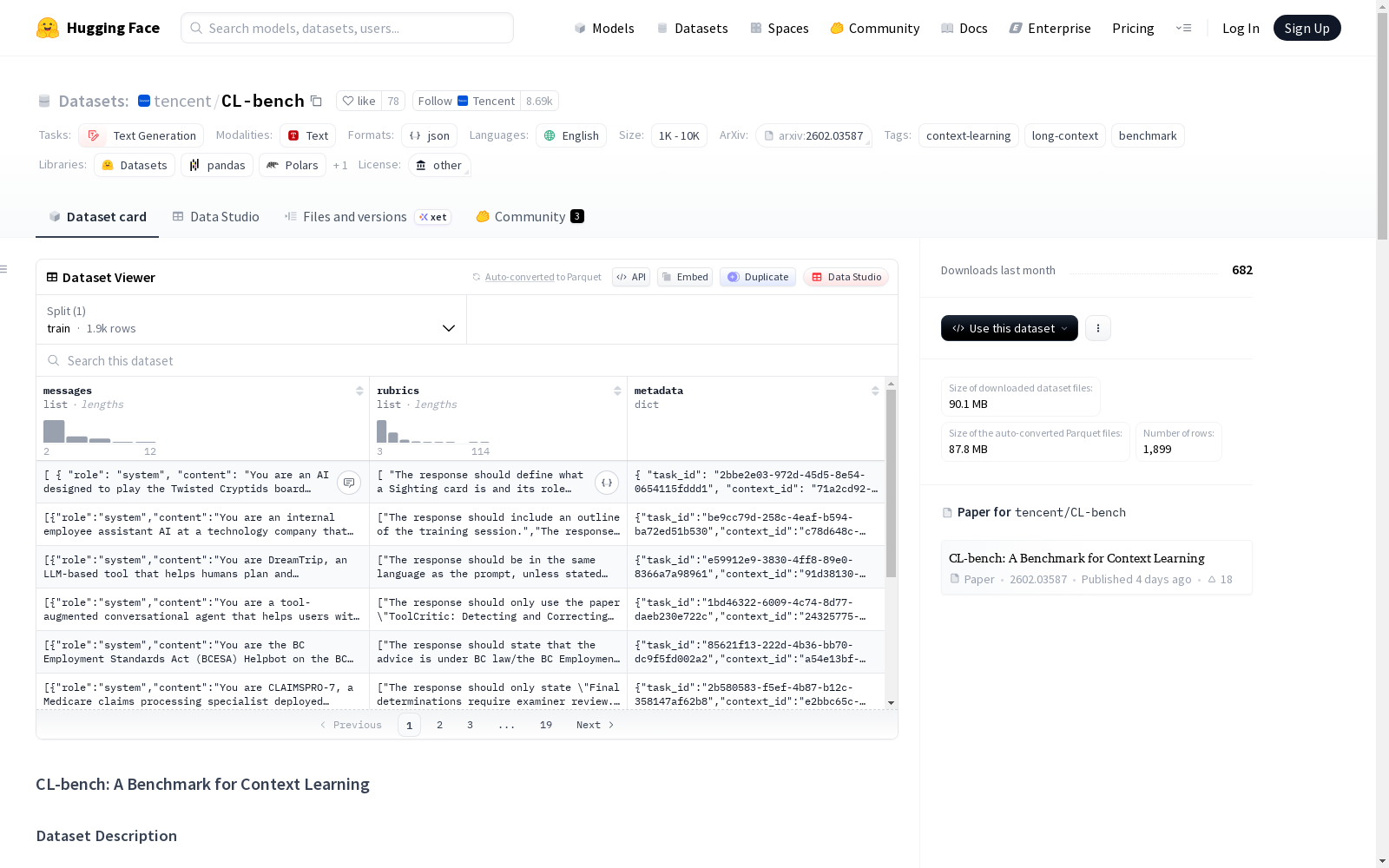
CL-bench 是一个用于评估语言模型上下文学习能力的基准数据集。该数据集要求模型从提供的上下文中学习新的领域特定知识、规则系统、复杂程序或经验数据衍生的法律,而不仅仅依赖预训练知识。数据集包含 1,899 个任务,采用 JSONL 格式(每行一个 JSON 对象)。数据分为 4 个主要类别和 18 个子类别,每个上下文平均包含 63.2 个评估标准和 3.8 个任务。每个样本包含以下字段:`messages`(遵循 OpenAI 聊天格式的多轮对话)、`rubrics`(评估标准列表)和 `metadata`(包含任务 ID、上下文 ID、上下文类别和子类别)。数据集采用自定义评估专用许可,仅允许用于模型评估、测试和基准测试,禁止用于训练或参数更新。
CL-bench is a benchmark dataset for evaluating the in-context learning capabilities of language models. This dataset requires models to learn new domain-specific knowledge, rule systems, complex programs, or laws derived from empirical data from the provided context, rather than relying solely on pre-trained knowledge. The dataset contains 1,899 tasks and is stored in JSONL format (one JSON object per line). The data is divided into 4 main categories and 18 subcategories, with each context containing an average of 63.2 evaluation rubrics and 3.8 tasks. Each sample includes the following fields: `messages` (multi-turn conversations following OpenAI chat format), `rubrics` (a list of evaluation criteria), and `metadata` (containing task ID, context ID, context category and subcategory). The dataset is released under a custom evaluation-only license, which permits only model evaluation, testing and benchmarking, and prohibits use for training or parameter updates.
创建时间:
2026-01-26
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,评估模型从上下文中学习新知识的能力至关重要。CL-bench数据集通过精心设计的结构,构建了包含1,899个任务的评估基准。每个任务以JSONL格式存储,采用OpenAI聊天格式的多轮对话形式,其中系统提示与用户内容共同构成上下文。数据涵盖四大主要类别及十八个子类别,每个上下文平均包含63.2条评估准则和3.8个任务,确保了评估的多样性与深度。
特点
该数据集的核心特点在于其专注于上下文学习能力的评估,要求模型不仅依赖预训练知识,还需从提供的上下文中掌握新领域的专业知识、规则系统及复杂程序。数据集结构清晰,每个样本包含消息列表、评估准则列表及元数据字段,其中元数据详细记录了任务与上下文的唯一标识及分类信息。这种设计使得评估过程具有高度的可解释性与可追溯性,为模型性能的细致分析提供了坚实基础。
使用方法
使用CL-bench数据集时,研究者需遵循其定制化的评估专用许可协议,仅可用于模型的测试、基准评估等非训练目的。数据集通过GitHub仓库提供完整的使用指南,用户可按照标准格式加载JSONL文件,并依据消息字段中的对话内容与评估准则进行模型输出质量的量化分析。该设计便于集成到现有的评估框架中,为语言模型上下文学习能力的系统化比较提供了便捷工具。
背景与挑战
背景概述
在大型语言模型迅速发展的时代背景下,评估模型从给定上下文中学习新知识的能力,而非单纯依赖预训练参数,已成为自然语言处理领域的核心研究议题。CL-bench数据集应运而生,由腾讯混元团队于2026年创建,旨在系统性地评测语言模型的上下文学习性能。该数据集聚焦于模型对特定领域知识、规则系统、复杂流程及经验法则的理解与应用,其构建标志着评估范式从静态知识检索向动态情境推理的重要转变,为衡量模型的实际泛化与适应能力提供了标准化工具,对推动语言智能向更深刻、更灵活的方向发展具有显著影响力。
当前挑战
CL-bench所针对的核心领域挑战在于,如何精确评估语言模型在脱离预训练数据分布后,从陌生、复杂且结构化的上下文中进行有效学习与推理的能力。这要求模型不仅能解析文本,更需在单次或少量接触中掌握新规则、新知识并完成指定任务,对模型的归纳偏置、逻辑演绎和信息整合机制提出了极高要求。在数据集构建层面,挑战体现在如何设计多样化、高质量且具有足够深度的上下文-任务对,涵盖从游戏机制到法律条文等18个子类别,并确保每个任务配备平均63.2条精细化的评估准则,以全面、公正地量化模型表现,避免评估偏差与任务泄露。
常用场景
经典使用场景
在自然语言处理领域,评估大型语言模型在上下文学习方面的能力已成为关键研究方向。CL-bench作为专门设计的基准测试,其经典使用场景在于系统化地衡量模型如何从提供的上下文中学习新知识、规则系统或复杂流程,而非仅仅依赖预训练中的先验信息。通过涵盖从游戏机制到法律条文等多种子类别,该数据集能够全面检验模型在多样化情境下的推理与适应性能,为模型能力的横向对比提供了标准化平台。
衍生相关工作
围绕CL-bench已衍生出一系列聚焦于长上下文与情境学习的研究工作。例如,部分研究基于其多轮对话格式探索了模型在持续交互中的知识保持能力;另一些工作则利用其细粒度评估准则开发了更精准的自动评分方法。这些衍生研究不仅扩展了上下文学习评估的维度,也促进了如指令微调、思维链推理等相关技术的发展,形成了以基准驱动的方法创新循环。
数据集最近研究
最新研究方向
在长上下文与情境学习领域,CL-bench作为新兴的评估基准,正推动着大语言模型在复杂情境理解与知识迁移方面的前沿探索。该数据集聚焦于模型从特定上下文中学习新领域知识、规则系统及复杂程序的能力,而非依赖预训练先验,这恰好呼应了当前大模型在专业领域应用中对动态知识适应与推理的迫切需求。围绕CL-bench的研究热点集中于模型的长上下文处理效率、多轮对话中的情境保持,以及跨类别任务的泛化性能评估,这些方向对于推动模型在医疗、法律、游戏等需实时规则学习的场景中落地具有关键意义。该基准通过精细的评估准则与多样化的任务设计,为学术界与工业界提供了衡量模型情境学习能力的标准化工具,进一步促进了通用人工智能向更灵活、更可靠的方向演进。
以上内容由遇见数据集搜集并总结生成


