Laz4rz/wikipedia_science_chunked_small_rag_256
收藏Hugging Face2024-06-12 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/Laz4rz/wikipedia_science_chunked_small_rag_256
下载链接
链接失效反馈官方服务:
资源简介:
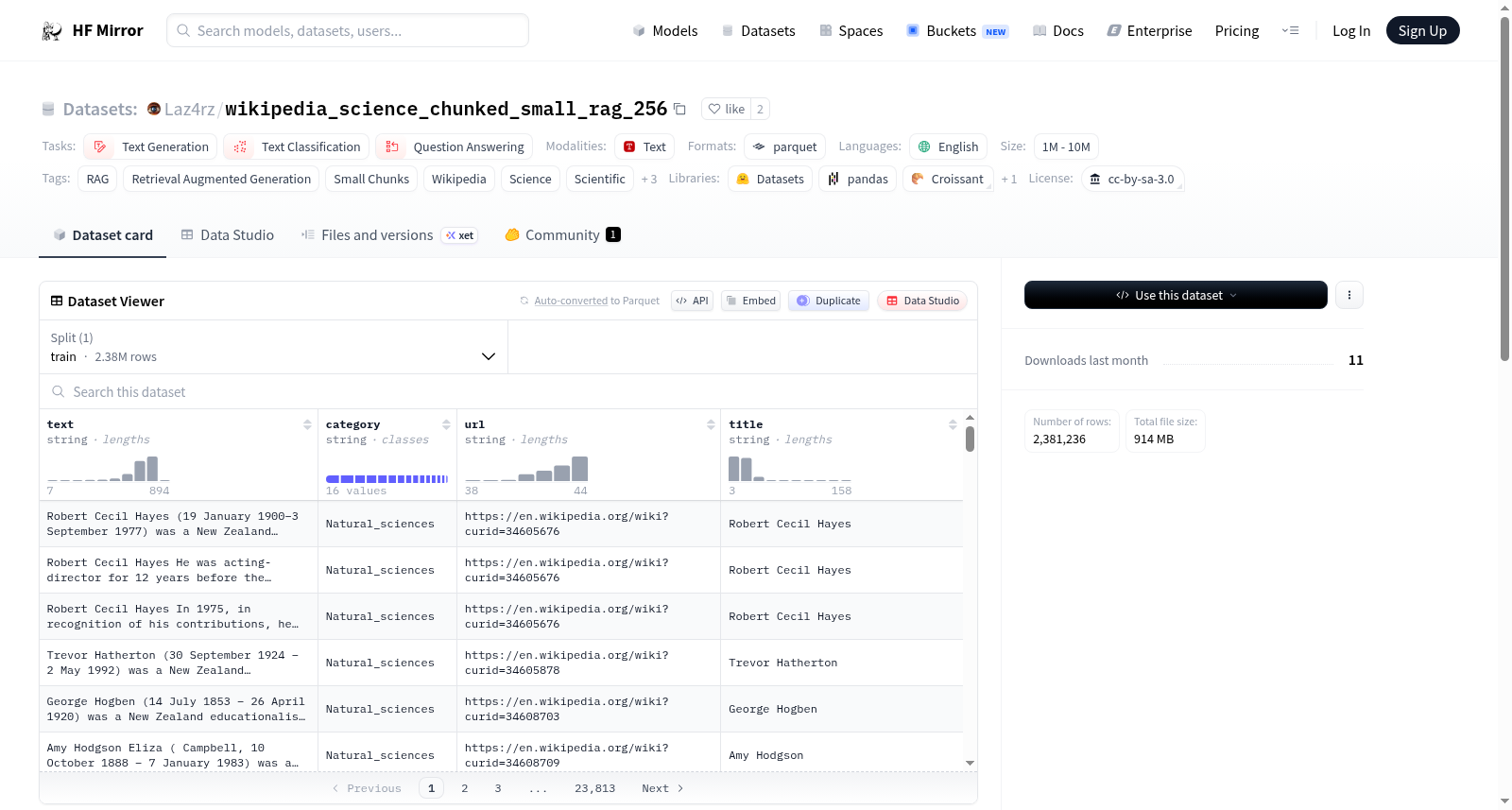
ScienceWikiSmallChunk数据集是millawell/wikipedia_field_of_science数据集的处理版本,专为小上下文长度的RAG(检索增强生成)系统设计。每个数据块的长度大约为256个token,较长的维基百科页面被分割成较小的条目,并在每个条目前添加了标题作为前缀。此外,还提供了一个512个token的数据集,并提供了如何准备其他长度数据块的代码示例。
ScienceWikiSmallChunk数据集是millawell/wikipedia_field_of_science数据集的处理版本,专为小上下文长度的RAG(检索增强生成)系统设计。每个数据块的长度大约为256个token,较长的维基百科页面被分割成较小的条目,并在每个条目前添加了标题作为前缀。此外,还提供了一个512个token的数据集,并提供了如何准备其他长度数据块的代码示例。
提供机构:
Laz4rz
原始信息汇总
ScienceWikiSmallChunk256
概述
- 名称: ScienceWikiSmallChunk256
- 标签:
- RAG
- Retrieval Augmented Generation
- Small Chunks
- Wikipedia
- Science
- Scientific
- Scientific Wikipedia
- Science Wikipedia
- 256 tokens
- 许可证: cc-by-sa-3.0
- 任务类别:
- text-generation
- text-classification
- question-answering
描述
- 来源: 基于
millawell/wikipedia_field_of_science数据集处理而成。 - 用途: 适用于小上下文长度的RAG系统。
- 分块长度: 每个分块大约为256个token,具体长度依赖于tokenizer。
- 处理方式: 长篇维基百科页面已被分割成较小的条目,并在每个条目前添加标题作为前缀。
相关资源
- 512 tokens数据集:
Laz4rz/wikipedia_science_chunked_small_rag_512 - 自定义分块长度: 使用
millawell/wikipedia_field_of_science数据集,并调整分块函数。
分块函数示例
python def chunker_clean(results, example, length=512, approx_token=3, prefix=""): if len(results) == 0: regex_pattern = r[ s]* [ s]* example = re.sub(regex_pattern, " ", example).strip().replace(prefix, "") chunk_length = length * approx_token if len(example) > chunk_length: first = example[:chunk_length] chunk = ".".join(first.split(".")[:-1]) if len(chunk) == 0: chunk = first rest = example[len(chunk)+1:] results.append(prefix+chunk.strip()) if len(rest) > chunk_length: chunker_clean(results, rest.strip(), length=length, approx_token=approx_token, prefix=prefix) else: results.append(prefix+rest.strip()) else: results.append(prefix+example.strip()) return results
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是维基百科科学领域文本的预处理版本,专为小型上下文长度的RAG系统优化,每个文本块约256个标记,适合自然语言处理任务如文本生成和问答。数据集包含约238万行文本,总文件大小为914MB,采用cc-by-sa-3.0许可证。
以上内容由遇见数据集搜集并总结生成


