jmccardle/pulse-sofroniew-emotion-concept-texts
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/jmccardle/pulse-sofroniew-emotion-concept-texts
下载链接
链接失效反馈官方服务:
资源简介:
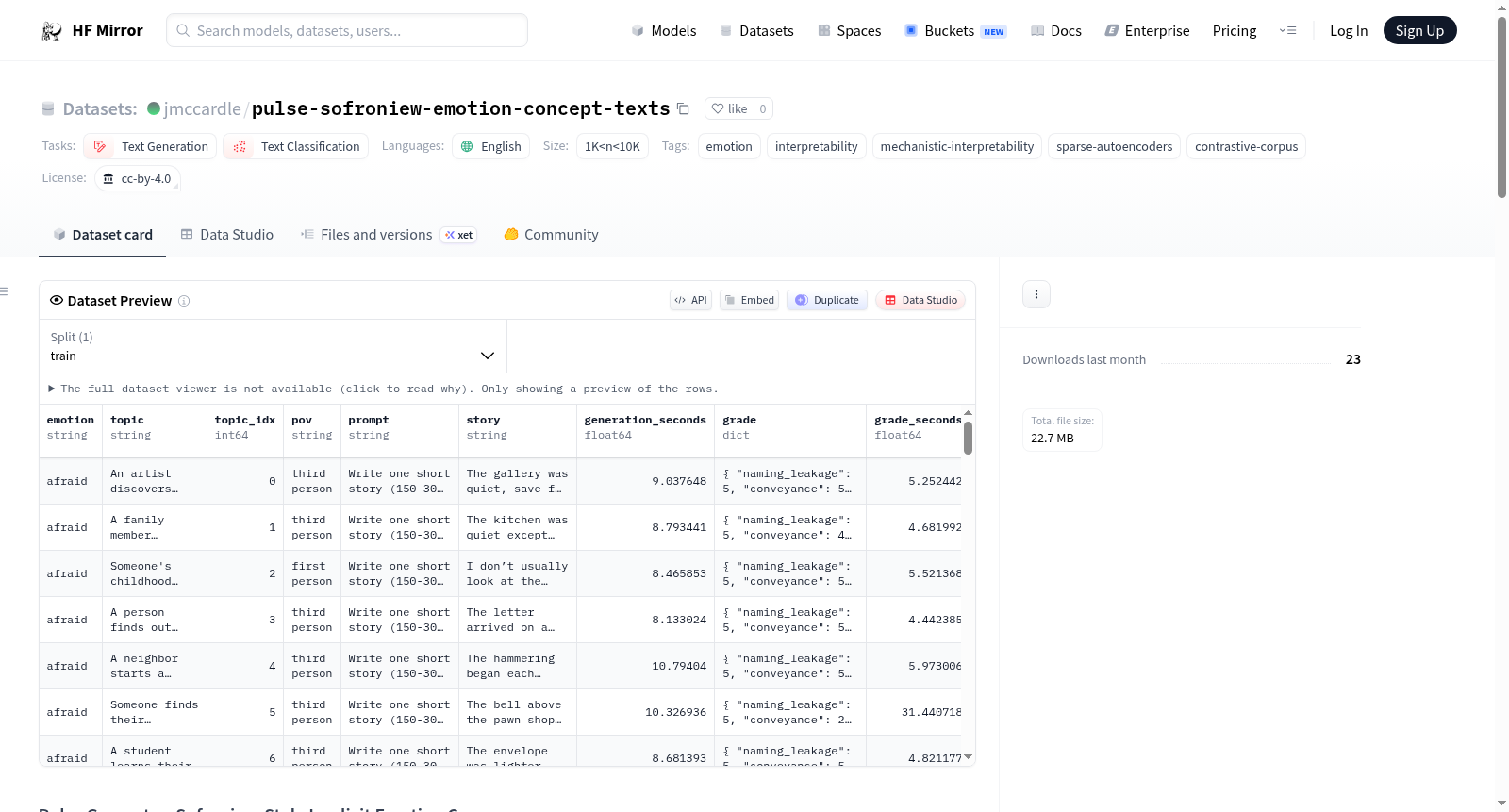
Pulse Geometry: Sofroniew式隐式情感语料库是一个包含8,550个短篇故事的对比语料库(171种情感×50个主题),这些故事通过行为、感觉、对话、内心思想或环境描述来隐式传达目标情感,而从不直接命名情感。每个故事由Claude Sonnet根据四轴评分标准进行评分。该语料库旨在作为几何复制的基底,探究Claude Sonnet 4.5中的情感向量布局是否也存在于Gemma 2 2B中。数据集结构为每个(情感,主题)单元格一个JSON记录,文件按`<情感>/topic_NNN.json`组织。情感标签来自Sofroniew等人(2026年),主题种子同样来源于此。数据集适用于几何/探测、隐式情感建模以及评分标准研究。
Pulse Geometry: Sofroniew-Style Implicit Emotion Corpus is a contrastive corpus of 8,550 short stories (171 emotions × 50 topics) that convey a target emotion implicitly — through behavior, sensation, dialogue, internal thought, or environmental description, but never by naming the emotion. Each story is scored on a four-axis rubric by Claude Sonnet. The corpus was built as the substrate for a geometry replication, probing whether an emotion-vector layout analogous to Sofroniew et al. (2026) for Claude Sonnet 4.5 also exists in Gemma 2 2B. The dataset structure consists of one JSON record per (emotion, topic) cell, with files organized as `<emotion>/topic_NNN.json`. The emotion labels are taken from Sofroniew et al. (2026), and the topic seeds are also sourced from the same. The dataset is intended for geometry/probing, implicit-affect modeling, and rubric and grader research.
提供机构:
jmccardle
搜集汇总
数据集介绍
构建方式
该数据集以生成隐式情感文本为核心,通过系统化的流水线构建而成。首先选取源自Sofroniew等人研究中的171种情感标签与50个场景主题,形成8550个独立单元。每个单元由Qwen3-32B模型在特定温度与采样参数下生成一则短篇故事,故事需通过行为、感官、对话、内心独白或环境描写含蓄地传达目标情感,严禁直接提及情感词汇。随后由Claude Sonnet模型依据命名泄露、情感传达、主题契合与文本连贯性四个维度进行五分制评分,仅当所有维度得分不低于4分时被视为合格样本。数据以JSON格式按情感分类存储,确保每个情感下的主题序列完整对齐。
特点
该数据集的核心特色在于其精心设计的对比性结构与隐式情感表达机制。所有8550篇故事均遵循“展示而非告知”原则,通过丰富的暗示性描写传递情感,而非直白命名,这为研究语言模型的内在情感表征提供了纯净素材。数据集的对比性体现在每个场景主题均与全部171种情感配对,使得任意两种情感之间均拥有50组主题匹配的对照样本,有效控制了场景变量。此外,四轴评分体系不仅量化了生成质量,更通过命名泄露评分确保了情感词汇的零出现,维护了隐式语料的纯粹性,为机械可解释性与稀疏自编码器研究奠定了坚实基础。
使用方法
该数据集在自然语言处理研究中具有多重应用场景。在几何探测任务中,研究者可基于主题匹配的对比对,训练情感分类器或从开放权重语言模型的残差流中提取情感方向向量,探索情感语义空间的几何结构。对于隐式情感建模,数据集提供了丰富的“展示而非告知”示例,支持分析模型在表面标签被抑制时的生成能力与情感理解深度。同时,研究者可借助8550组包含故事与四轴评分的配对记录,开展评分机制与模型评估标准的研究,构建更精准的自动评估系统。使用时需注意评分为单一语言模型所给的噪声信号,且故事仅由Qwen3-32B生成,存在风格单一性局限。
背景与挑战
背景概述
在机械可解释性与情感表示学习的前沿领域,隐式情感语料库的构建是理解语言模型内部情感几何结构的关键基石。Pulse Geometry — Sofroniew-Style Implicit Emotion Corpus 于2025年由研究团队创建,旨在复现Sofroniew等人(2026)关于Claude Sonnet 4.5中情感向量布局的发现,并将其推广至Gemma 2 2B模型。该数据集汇聚了8,550则短篇故事,覆盖171种情感与50个主题,每则故事均通过行为、感知、对话、内心独白或环境描写隐式传达目标情感,而绝不直呼其名。研究团队利用Qwen3-32B生成文本,并借助Claude Sonnet在四个轴线上进行评分,构建了一个兼具对比性与可审计性的资源。该语料库不仅为情感方向探测提供了匹配的主题对照对,还推动了可解释性与隐式情感建模的交叉研究,成为连接语言模型内部表示与人类情感认知的重要桥梁。
当前挑战
该数据集面临的挑战首先源自所解决的领域问题:情感表示学习长期依赖显式标签,难以捕获情感在自然语言中的微妙表达,而隐式情感的建模需要数据在避免命名泄露的同时,仍能确保情感的鲜明传达。为此,数据集在构建过程中引入了多重策略,但面临评分噪声的困扰——所有评分仅由单一语言模型(Claude Sonnet)生成,缺乏人类交叉校准,使得其作为筛选标准的可靠性存疑。此外,情感本体并不纯净,171个标签中包含大量近义词,尽管这一设计有利于几何分析,却使分类任务难以直接应用。在构建流程中,仅依赖Qwen3-32B作为文本生成源,导致数据集中存在模型特有的风格偏差;同时,非试点情感仅禁止字面情感词,语义近邻的命名泄露可能未被惩罚,影响数据纯净度。这些挑战共同制约了数据集在广泛下游任务中的适用性与鲁棒性。
常用场景
经典使用场景
该数据集最经典的使用场景是作为情感几何(emotion geometry)分析的对比语料库。它包含8,550篇短篇故事,覆盖171种情感和50个主题,每篇故事通过行为、感觉、对话、内心独白或环境描写等渠道隐式传达目标情感,而从不直接提及情感名称。这种结构使得研究人员可以在控制主题内容不变的前提下,构建情感间的对比对,从而训练情感分类器或从开放权重语言模型的残差流中提取情感方向。数据集还提供了基于四项评分的质量筛选机制,便于提取高质量的‘干净’子集用于下游分析。
解决学术问题
该数据集解决了情感表示研究中一个关键的方法论问题——如何系统性地生成并验证隐式情感文本。传统情感数据集多依赖显式命名或简单标签,难以支撑对语言模型内部情感几何结构的精细节探。通过大语言模型生成长达150至300词的短篇故事,并采用自动评分机制评估命名泄露、情感传达、主题遵循和文本连贯性,该数据集为研究‘展示而非告知’的情感生成提供了可靠资源。其设计直接回应了Sofroniew等人的工作中关于情感向量布局可迁移性的假设,使得在较小开源模型如Gemma 2 2B上复现复杂情感几何成为可能。
衍生相关工作
该数据集衍生出一系列围绕可解释性与情感表示的重要工作。最直接的是乔治·索弗罗尼耶夫等人2026年关于情感几何的研究,其旨在揭示大语言模型中情感向量的空间排列结构。在此基础上,研究者使用该语料库探索稀疏自编码器(如Gemma Scope SAE)特征是否能够复现类似的情感布局架构,从而检验情感表示在不同规模模型间的迁移性与稳健性。相关工作还包括对比分析隐式情感生成与显式情感标注之间的表征差异,以及自动评分器的校准与跨模型一致性评测,推动了情感可解释性领域的边界拓展。
以上内容由遇见数据集搜集并总结生成


