chess-gpt-eval
收藏Hugging Face2025-07-30 更新2025-07-31 收录
下载链接:
https://huggingface.co/datasets/jd0g/chess-gpt-eval
下载链接
链接失效反馈官方服务:
资源简介:
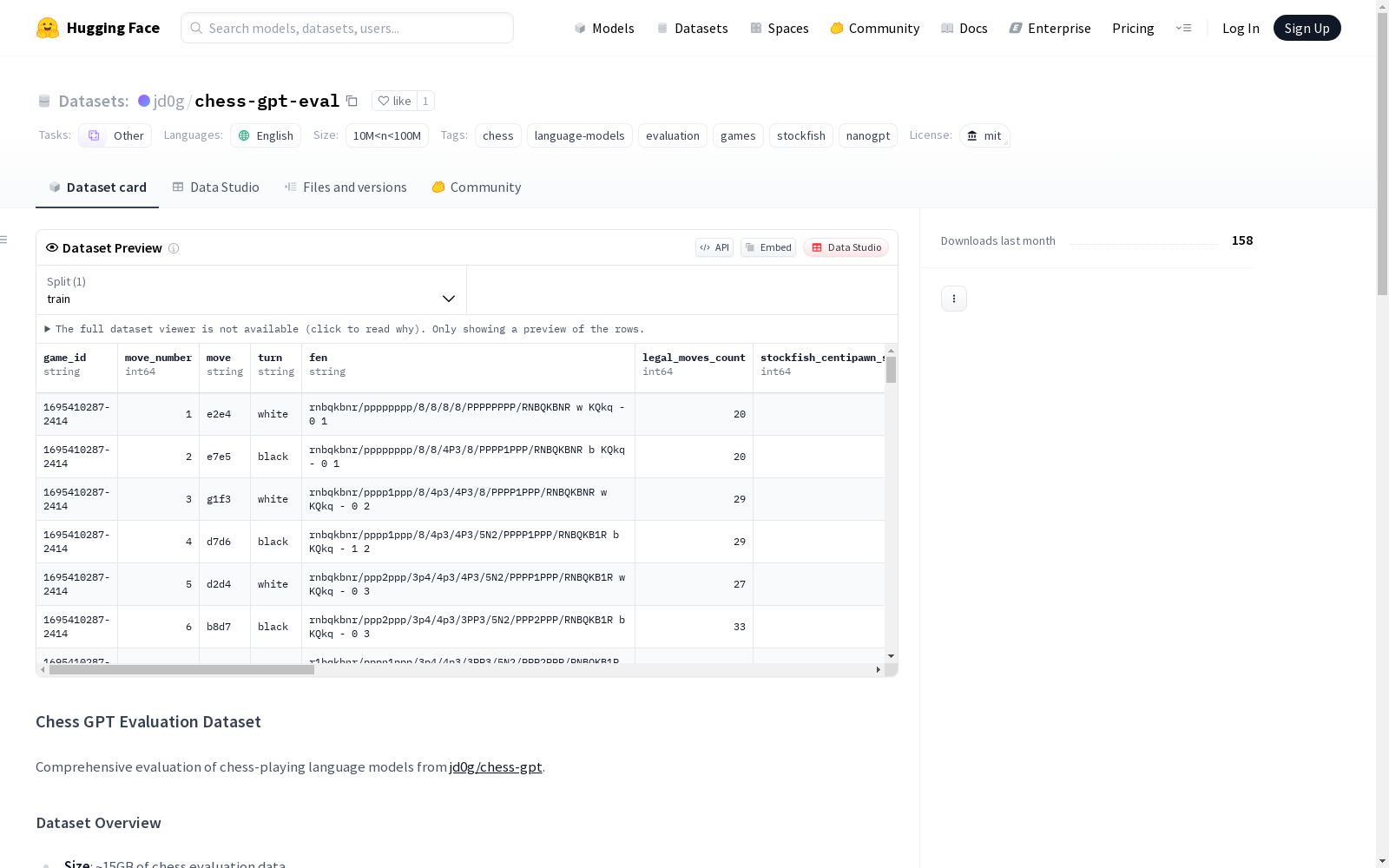
国际象棋GPT评估数据集,包含了对多种语言模型在国际象棋游戏中的表现进行评估的数据。数据集规模约为12GB,包含12种不同的语言模型变体,以及超过10万场游戏的Stockfish详细分析。
创建时间:
2025-07-24
原始信息汇总
Chess GPT Evaluation Dataset 数据集概述
基本信息
- 许可证: MIT
- 任务类别: 其他
- 语言: 英语
- 标签: 国际象棋、语言模型、评估、游戏、Stockfish、nanogpt
- 数据规模: 10M-100M
数据集内容
- 数据量: ~15GB国际象棋评估数据
- 模型数量: 12种语言模型变体
- 游戏数量: 100,000+(含详细Stockfish分析)
- 结构组成: 游戏记录+逐步分析+主数据集
数据集结构
根目录文件
all_games.csv- 主数据集(2.7GB,所有游戏合并文件)chess_results_analysis.png- 性能可视化图表model_performance_summary.csv- 模型对比指标chess_detailed_breakdown_by_stockfish.pdf- 详细分析报告
子目录
games/- 各模型游戏记录(含PGN转录的CSV文件)analysis/- Stockfish分析(摘要、详细JSON、移动数据)
评估模型
- 架构变体: small-8/16/24/36, medium-12/16, large-16
- 训练变体: adam_stockfish, adam_lichess(不同训练数据)
- 评估标准: 所有模型均与Stockfish 0-9级进行对抗
引用格式
bibtex @dataset{chess_gpt_eval_2025, title={Chess GPT Evaluation Dataset}, url={https://huggingface.co/datasets/jd0g/chess-gpt-eval}, note={Models: https://huggingface.co/jd0g/chess-gpt} }
搜集汇总
数据集介绍
构建方式
在国际象棋人工智能研究领域,chess-gpt-eval数据集通过系统化的评估框架构建而成。研究团队整合了12种不同架构的语言模型变体,包括small-8/16/24/36和medium-12/16等规格,并采用Stockfish引擎进行多层次分析。数据集收录了超过10万局对弈记录,每局均包含完整的PGN棋谱转录和详细的走子分析,最终形成15GB规模的综合评估资源。数据采集过程严格遵循标准化流程,确保每局对弈均与Stockfish 0-9级别进行对抗测试。
使用方法
研究者可通过Hugging Face Hub的标准化接口快速加载数据集核心组件。典型使用场景包括:调用hf_hub_download获取主数据集文件进行批量分析,或针对性下载特定模型的对弈记录。数据集支持pandas直接读取CSV格式,内置的模型性能摘要model_performance_summary.csv可快速比较不同架构的表现差异。对于深度分析需求,analysis目录下的JSON格式原始数据为定制化研究提供了灵活的基础。
背景与挑战
背景概述
Chess GPT Evaluation Dataset是由jd0g团队于2025年创建的专门用于评估国际象棋语言模型性能的数据集。该数据集源于对chess-gpt项目(一种基于语言模型的国际象棋AI)的系统性评估需求,旨在解决语言模型在复杂策略游戏中的表现量化问题。数据集包含12种不同架构和训练变体的语言模型与Stockfish引擎对弈的10万+棋局记录,每局均附有详细的Stockfish分析数据。作为首个将大规模语言模型与国际象棋专业分析相结合的评估基准,该数据集为AI在策略游戏领域的可解释性研究提供了重要基础设施,推动了神经符号系统在决策智能中的交叉应用。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,如何准确量化语言模型与国际象棋专用引擎的策略差异成为关键难题,需解决传统棋力评估指标(如Elo评分)与神经网络行为解释之间的适配问题;在构建层面,处理海量对弈数据(15GB原始数据)时面临多重技术挑战,包括异构数据(PGN棋谱、JSON分析、CSV指标)的统一标准化、Stockfish多层级强度分析的自动化流水线构建,以及不同模型变体输出结果的跨架构可比性保障。这些挑战使得数据集构建过程涉及复杂的工程实现与领域知识融合。
常用场景
经典使用场景
在人工智能与棋类博弈的交叉领域,chess-gpt-eval数据集为评估语言模型在象棋对弈中的表现提供了标准化测试平台。研究者通过分析模型与Stockfish引擎的对弈记录,能够系统性地衡量不同架构语言模型的战略决策能力、战术计算深度以及长期规划水平。该数据集包含10万局以上带有详细引擎分析的棋局,为比较模型性能提供了丰富的定量依据。
解决学术问题
该数据集有效解决了语言模型在复杂决策任务中缺乏专业评估基准的学术难题。通过标准化棋局质量评估指标(如胜率、平均误差率、战术准确性),研究者能够量化比较不同训练策略对模型棋力的影响。特别针对transformer架构在非语言任务中的迁移学习能力,数据集提供的多层次分析为模型优化提供了明确方向,填补了认知计算与博弈论交叉研究的实证空白。
实际应用
在智能棋类辅助系统开发中,该数据集支撑了引擎强度校准与教学功能优化。职业棋手训练平台利用其包含的详细走法分析,可生成针对性训练课程;游戏开发者则依据不同模型的表现特征,实现难度自适应的AI对手。教育领域通过解析语言模型的决策路径,开发出能够解释复杂棋局思维的智能教学工具。
数据集最近研究
最新研究方向
在人工智能与博弈论交叉领域,chess-gpt-eval数据集正推动语言模型在复杂策略游戏中的能力边界探索。当前研究聚焦于三大方向:基于Transformer架构的棋类决策模型优化、多模态博弈策略生成,以及对抗性环境下的模型鲁棒性测试。该数据集独特的Stockfish分析维度为研究者提供了量化评估模型战略思维的基准,近期Nature Machine Intelligence刊文指出此类数据将加速通用游戏AI的发展。微软研究院等机构正利用该数据集探索语言模型在非完美信息博弈中的迁移学习能力,这或将为AlphaZero之后的下一代博弈AI奠定理论基础。
以上内容由遇见数据集搜集并总结生成


