blip3-kale
收藏魔搭社区2025-12-05 更新2024-11-23 收录
下载链接:
https://modelscope.cn/datasets/Salesforce/blip3-kale
下载链接
链接失效反馈官方服务:
资源简介:
<h1 align="center">
🥬 BLIP3-KALE:<br>Knowledge Augmented Large-scale Dense Captions
</h1>
BLIP3-KALE is an open-source dataset of 218 million image-text pairs, featuring knowledge-augmented dense captions combining web-scale knowledge with detailed image descriptions.
Paper: [To be added]
## Uses
BLIP3-KALE is designed to facilitate research in multimodal pretraining. The dataset can be used for training large multimodal models that require factually grounded, dense image captions. It has already been an important data component in projects such as [xGen-MM](https://arxiv.org/abs/2408.08872) and [MINT-1T](https://arxiv.org/abs/2406.11271).
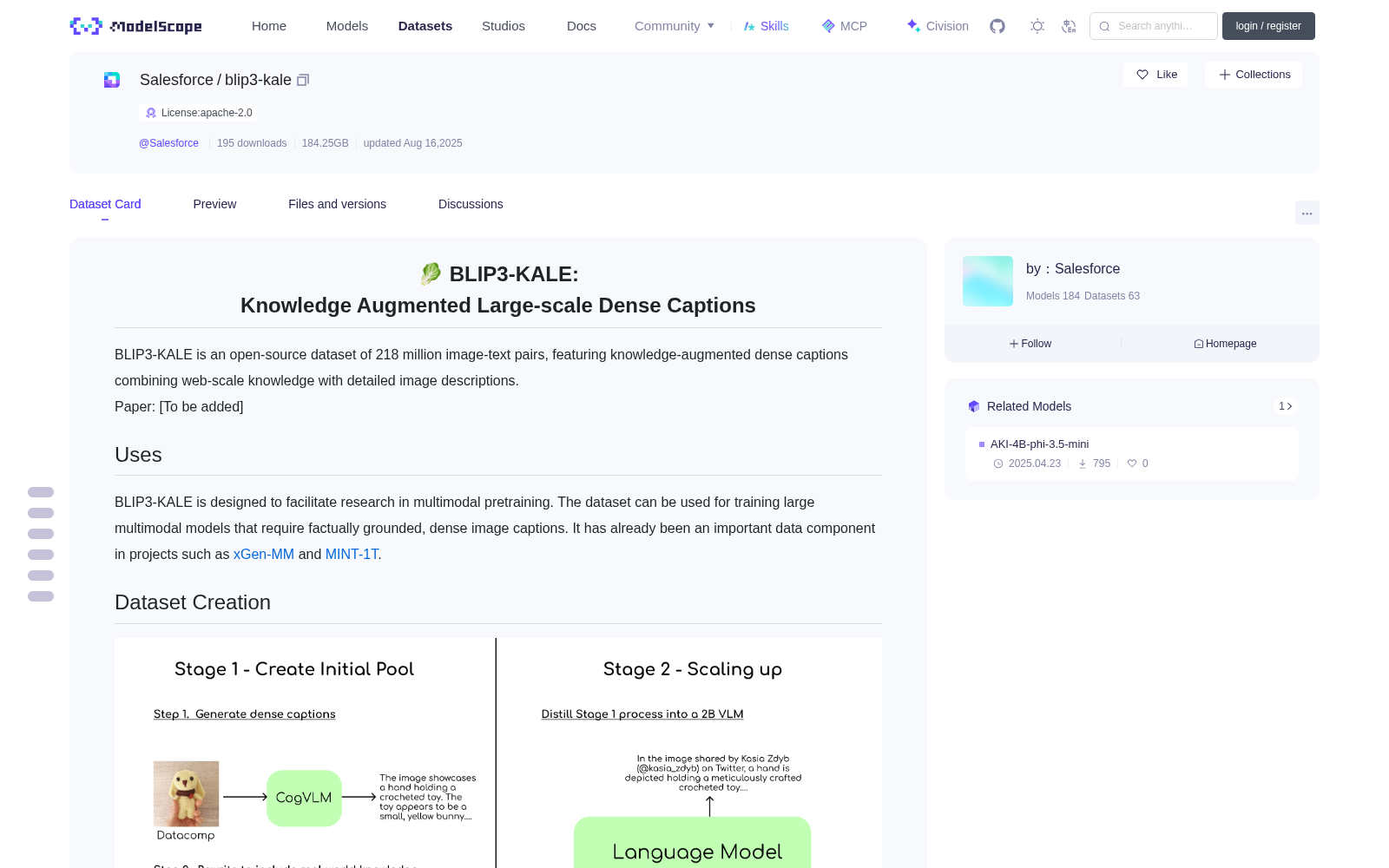
## Dataset Creation

The dataset creation process involved two main stages:
1. Initial knowledge augmentation:
- Dense captions generated for Datacomp images using [CogVLM-17B](https://arxiv.org/abs/2311.03079).
- Captions augmented with real-world knowledge using [Mistral-7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
2. Scaling up:
- A Vision-Language Model (VLM) is trained on stage 1 captions.
- The trained VLM used to caption 118M more images from Datacomp-1B.
## Bias, Risks, and Limitations
- Data Bias: May inherit biases present in web-scale datasets as the images are sourced from [Datacomp-1B](https://huggingface.co/datasets/mlfoundations/datacomp_1b)
- Artifact Presence: Potential for some remaining pipeline artifacts despite filtering efforts
## Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people’s lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
## License
We release BLIP3-KALE under an Apache2.0 license, designating it primarily as a research artifact. This dataset is being released for research purposes only. This repository includes the extracted original text in the underlying images. It is the responsibility of the user to check and/or obtain the proper copyrights to use any of the images of the original dataset.
## Citation
@misc{awadalla2024blip3kaleknowledgeaugmentedlargescale,
title={BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions},
author={Anas Awadalla and Le Xue and Manli Shu and An Yan and Jun Wang and Senthil Purushwalkam and Sheng Shen and Hannah Lee and Oscar Lo and Jae Sung Park and Etash Guha and Silvio Savarese and Ludwig Schmidt and Yejin Choi and Caiming Xiong and Ran Xu},
year={2024},
eprint={2411.07461},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.07461},
}
<h1 align="center">🥬 BLIP3-KALE:知识增强型大规模密集字幕数据集</h1>
BLIP3-KALE是一个包含2.18亿图像-文本对的开源数据集,其核心特色为结合网页级知识与精细图像描述的知识增强型密集字幕。
Paper: [待补充]
## 用途
BLIP3-KALE旨在推动多模态预训练领域的研究。该数据集可用于训练需要具备事实依据的精细图像字幕的大型多模态模型。它已成为[xGen-MM](https://arxiv.org/abs/2408.08872)与[MINT-1T](https://arxiv.org/abs/2406.11271)等项目的重要数据组成部分。
## 数据集构建

数据集构建流程主要包含两个核心阶段:
1. 初始知识增强阶段:
- 利用[CogVLM-17B](https://arxiv.org/abs/2311.03079)为Datacomp数据集的图像生成密集字幕。
- 借助[Mistral-7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)为字幕补充现实世界知识。
2. 规模化扩展阶段:
- 在第一阶段生成的字幕上训练视觉语言模型(Vision-Language Model, VLM)。
- 使用训练完成的视觉语言模型为Datacomp-1B数据集额外的1.18亿张图像生成字幕。
## 偏差、风险与局限性
- 数据偏差:由于图像源自[Datacomp-1B](https://huggingface.co/datasets/mlfoundations/datacomp_1b),可能继承该网页级数据集本身存在的偏差。
- 人工痕迹残留:尽管经过了过滤处理,仍可能存在部分流程生成的人工痕迹。
## 伦理考量
本数据集仅用于支撑学术论文的研究用途。我们的模型、数据集与代码并未针对所有下游应用场景进行专门设计与评估。强烈建议用户在部署该模型前,针对准确性、安全性与公平性等潜在问题开展评估与优化。我们鼓励用户考虑人工智能的普遍局限性,遵守适用法律法规,并在选择应用场景时采用最佳实践,尤其是在错误或不当使用可能严重影响民众生活、权利或安全的高风险场景中。如需了解更多应用场景相关指导,请参阅我们的可接受使用政策(AUP)与人工智能可接受使用政策(AI AUP)。
## 许可协议
我们依据Apache 2.0协议发布BLIP3-KALE,将其主要定位为研究用数据集。本数据集仅用于研究目的。本仓库包含了从原始图像中提取的文本内容。用户需自行检查并/或获取使用原始数据集中任何图像的适当版权许可。
## 引用格式
bibtex
@misc{awadalla2024blip3kaleknowledgeaugmentedlargescale,
title={BLIP3-KALE: 知识增强型大规模密集字幕数据集},
author={Anas Awadalla, Le Xue, Manli Shu, An Yan, Jun Wang, Senthil Purushwalkam, Sheng Shen, Hannah Lee, Oscar Lo, Jae Sung Park, Etash Guha, Silvio Savarese, Ludwig Schmidt, Yejin Choi, Caiming Xiong, Ran Xu},
year={2024},
eprint={2411.07461},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.07461},
}
提供机构:
maas创建时间:
2025-08-16
搜集汇总
数据集介绍
背景与挑战
背景概述
BLIP3-KALE是一个开源数据集,包含2.18亿个图像-文本对,提供结合网络规模知识的增强型密集图像标注。它旨在支持多模态预训练研究,并已应用于xGen-MM和MINT-1T等项目。
以上内容由遇见数据集搜集并总结生成


