uiscreenshots
收藏Hugging Face2026-05-17 更新2026-05-18 收录
下载链接:
https://huggingface.co/datasets/lmoroney/uiscreenshots
下载链接
链接失效反馈官方服务:
资源简介:
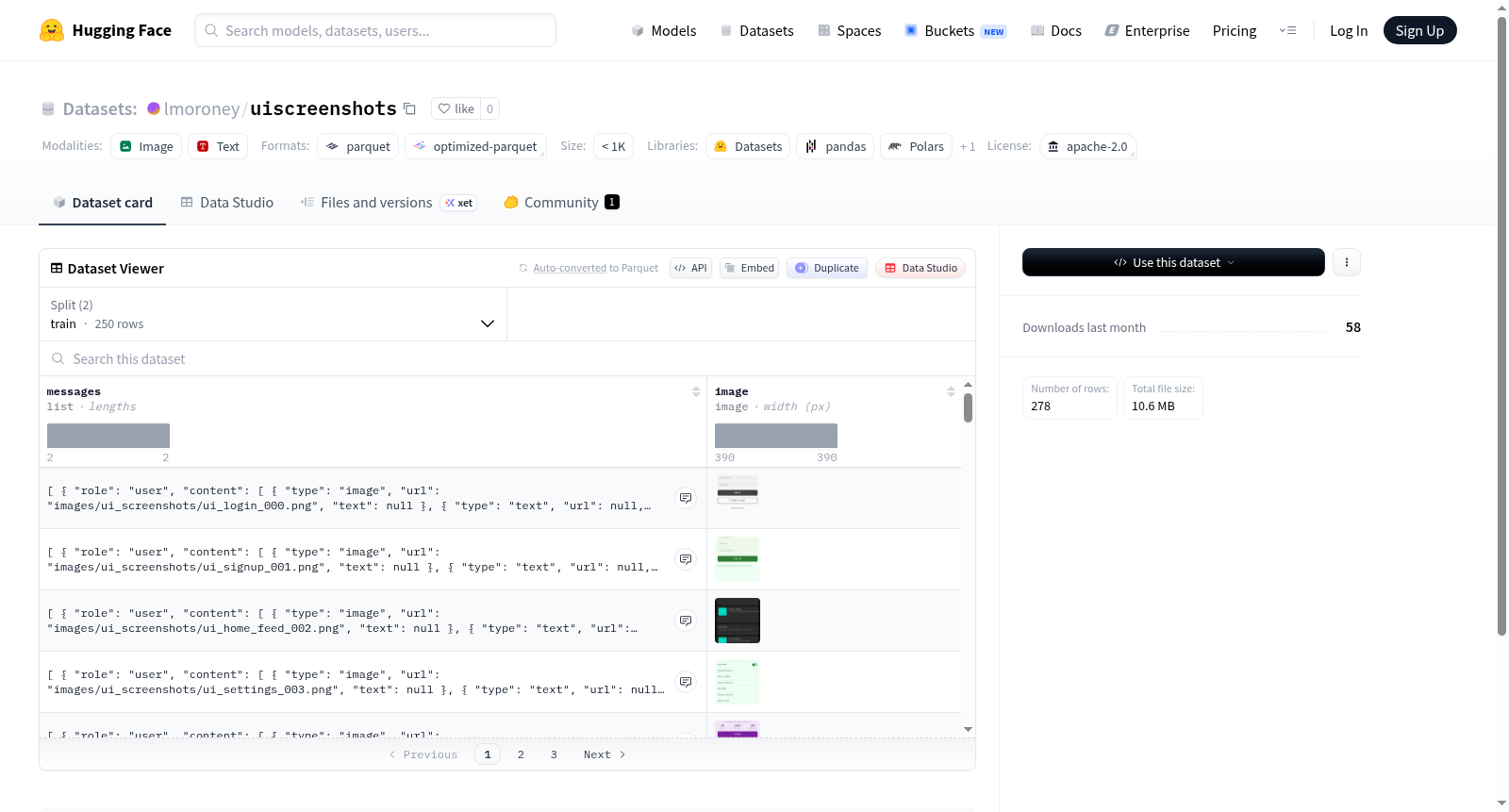
该数据集是一个多模态数据集,结合了文本对话和图像数据。它包含训练集和验证集,其中训练集有250个样本,验证集有28个样本。每个样本包括两个关键字段:messages和image。messages字段是一个列表,表示对话消息序列,每个消息由role(如用户或助手)和content组成。content字段本身也是一个列表,其中每个元素可能包含type、url和text,用于表示多类型内容,例如文本、链接或引用。image字段则存储相关的图像数据。该数据集适用于多种多模态任务,例如视觉语言理解、图像描述生成以及基于图像的对话系统开发。
This dataset is a multimodal dataset that combines text dialogues and image data. It consists of a training set and a validation set, with the training set containing 250 samples and the validation set containing 28 samples. Each sample includes two key fields: messages and image. The messages field is a list representing a sequence of dialogue messages, where each message contains a role (such as user or assistant) and content. The content field itself is also a list, with each element potentially containing type, url, and text, used to represent multi-type content, such as text, links, or references. The image field stores the associated image data. This dataset is suitable for various multimodal tasks, such as visual language understanding, image caption generation, and image-based dialogue system development.
创建时间:
2026-05-15
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的概述:
数据集概述
基本信息
- 数据集名称:uiscreenshots
- 许可协议:Apache-2.0
- 数据集地址:https://huggingface.co/datasets/lmoroney/uiscreenshots
数据集结构
该数据集包含两个子集:
- 训练集(train):共有250个样本,占用约5.55 MB
- 验证集(validation):共有28个样本,占用约613 KB
总数据集大小约为6.16 MB,下载大小约为5.15 MB。
数据特征
数据集包含两个主要特征:
- messages:一个列表,每条消息包含:
- role(字符串):角色
- content(列表):内容,包含:
- type(字符串):类型
- url(字符串):URL链接
- text(字符串):文本
- image(图像类型):图片数据
配置文件
- 配置名称:default
- 数据文件:
- 训练数据:
data/train-* - 验证数据:
data/validation-*
- 训练数据:
搜集汇总
数据集介绍
构建方式
uiscreenshots数据集是在移动用户界面(UI)研究领域的一项精心构建的成果,旨在服务于多模态交互模型的训练与评估。该数据集收集了共计278张移动应用界面的截图,并配以结构化的对话式标注。在构建过程中,每个样本都包含一张原始UI图像以及一段代表用户与系统交互的对话历史(messages),对话中每条消息均详细区分了角色(如用户或系统)及其内容类型(如图像URL或文本描述),从而为理解UI上下文提供了丰富的语义信息。数据被划分为训练集(250例)和验证集(28例),确保了模型开发与性能验证的独立性。
使用方法
使用uiscreenshots数据集时,用户可直接通过HuggingFace的datasets库加载默认配置,路径为'uiscreenshots'。加载后的数据将按'datasets.Dataset'格式组织,每个样本包含'messages'字段(一个角色与内容类型的列表)和'image'字段(PIL图像对象)。适用于构建对话式UI助手或自动测试生成系统。经典的应用流程包括:首先利用图像编码器提取UI特征,然后与消息中的文本嵌入进行融合,通过序列生成模型预测下一步的用户或系统响应。建议在训练前对对话历史进行长度截断或重采样,以适应模型的最大序列限制。
背景与挑战
背景概述
uiscreenshots数据集由相关研究团队于近期创建,旨在为移动用户界面(UI)理解与自动化分析提供结构化训练数据。该数据集聚焦于多轮人机对话场景下的UI截图与自然语言描述的对应关系,每个样本包含用户与系统的消息序列以及对应的界面截图,共包含250个训练样本和28个验证样本。研究核心在于探索如何利用视觉与文本的多模态信息,使模型能够精准理解用户意图并生成合理的界面操作指令,对智能助手、自动化测试及无障碍技术等领域具有重要的推动作用。
当前挑战
该数据集所解决的领域问题在于多模态UI理解任务的复杂性与高标注成本。一方面,移动界面截图中的视觉元素(如按钮、文本字段、图标)与自然语言描述之间存在异构语义鸿沟,模型需具备精确的视觉定位与语言解析能力。另一方面,构建过程中面临的挑战包括:样本规模有限(仅278条),难以覆盖UI交互的多样性;标注数据中需同时保留界面截图的原始像素信息与多轮对话结构,对数据采集与清洗提出高要求。此外,如何确保消息序列与截图之间的时序对齐,避免歧义,是提升数据集实用性的关键瓶颈。
常用场景
经典使用场景
在移动界面与图形用户界面(GUI)的自动化分析领域,uiscreenshots数据集以其精心标注的屏幕截图与结构化对话记录,成为训练多模态视觉语言模型的宝贵资源。研究者常利用该数据集构建能够从界面截图中精准识别控件、理解布局逻辑并生成自然语言交互指令的智能系统,其典型用途涵盖UI元素导航序列预测与界面功能描述生成等任务。
解决学术问题
该数据集着力破解传统GUI理解研究中普遍存在的标注成本高昂、模态孤立以及跨平台泛化能力不足等顽疾。通过提供涵盖多样化应用程序与网页的截图及其对应的多轮对话描述,它使得学界能够更系统地探索视觉界面与语言指令之间的语义对齐机制。其核心意义在于为开发能够像人类一样‘看懂’屏幕并执行操作的通用智能体奠定了数据基础,从而推动了端到端界面自动化的理论前进。
实际应用
在实际应用层面,uiscreenshots数据集驱动的模型可无缝嵌入多种生活场景。例如,为视觉障碍人士提供实时的屏幕内容语音解读,辅助其在手机上完成消息发送、应用切换等操作;亦可用于构建自动化测试工具,通过截图对比与UI元素识别,高效检测移动应用在不同版本间的布局缺陷与功能异常,显著提升软件质量保障的自动化水平。
数据集最近研究
最新研究方向
uiscreenshots数据集作为移动端用户界面视觉理解的专用资源,正推动多模态大模型在图形用户界面理解与自动化交互领域的前沿探索。该数据集汇聚了278张高质量移动应用截图及对应的对话式指令描述,为模型提供了从像素级界面元素到高层用户意图的映射训练素材。当前研究聚焦于利用此类数据增强视觉语言模型对UI布局、组件功能以及操作序列的推理能力,进而催生智能助手在屏幕解析、任务自动化及无障碍辅助等场景的突破性应用。伴随大型语言模型与视觉编码器的深度融合,uiscreenshots成为连接计算机视觉与自然语言处理在移动计算环境中的关键纽带,其蕴含的细粒度界面事实知识,对于构建能够理解并执行复杂图形界面操作的通用AI代理具有不可替代的奠基意义。
以上内容由遇见数据集搜集并总结生成


